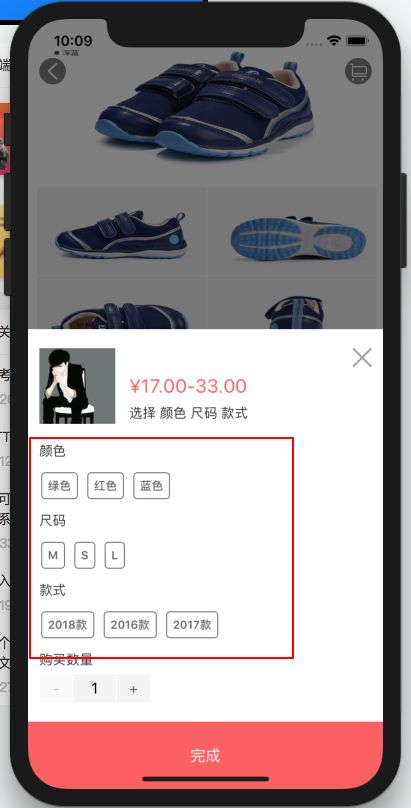
0 业务场景
服务器返回数据:
// 数据1
[
{"颜色" : "绿色", "款式" : "2018款", "尺码" : "M", "sku_id" : "1"},
{"颜色" : "红色", "款式" : "2016款", "尺码" : "M", "sku_id" : "2"},
{"颜色" : "绿色", "款式" : "2016款", "尺码" : "S", "sku_id" : "3"},
{"颜色" : "蓝色", "款式" : "2017款", "尺码" : "L", "sku_id" : "4"},
{"颜色" : "绿色", "款式" : "2018款", "尺码" : "L", "sku_id" : "5"}
]
当然中间还能添加sku库存或者价格之类的参数如下,但是本文不涉及此类内容
{@"颜色" : @"绿色", @"款式" : @"2018款", @"尺码" : @"M", @"sku_stock" : @"10", @"sku_price" : @"20.00", @"sku_id" : @"1"},
先将服务器返回数据进行group处理,处理后格式如下:
// 数据2
["颜色", "款式", "尺码"]
这时候需要列举出所有组合路径,形成一个笛卡尔积
// 数据3
[
["绿色", "2016款", "S"], // 可选
["绿色", "2016款", "M"],
["绿色", "2016款", "L"],
["绿色", "2017款", "S"],
["绿色", "2017款", "M"],
["绿色", "2017款", "L"],
["绿色", "2018款", "S"],
["绿色", "2018款", "M"], // 可选
["绿色", "2018款", "L"], // 可选
["红色", "2016款", "S"],
["红色", "2016款", "M"], // 可选
["红色", "2016款", "L"],
["红色", "2017款", "S"],
["红色", "2017款", "M"],
["红色", "2017款", "L"],
["红色", "2018款", "S"],
["红色", "2018款", "M"],
["红色", "2018款", "L"],
["蓝色", "2016款", "S"],
["蓝色", "2016款", "M"],
["蓝色", "2016款", "L"],
["蓝色", "2017款", "S"],
["蓝色", "2017款", "M"],
["蓝色", "2017款", "L"], // 可选
["蓝色", "2018款", "S"],
["蓝色", "2018款", "M"],
["蓝色", "2018款", "L"],
]
1 问题描述:
术语确定:
路径: 如"蓝色", "2016款", "S" 一种能够确定商品类型的选择
sku单元: 如 "蓝色" 一种能选择的最小单位
sku单元组: 如 {"颜色" : ["绿色", "红色", "蓝色"]} 一种规格的名称,及其规格下所有可选参数组成的集合
路径总数为每个sku单元组下可选参数数量的累乘,此中为 3 * 3 * 3 = 27种路径.到此为止都只是很简单的计算.
难点在于不是每种sku都可选,必须要将不可选的路径给置灰,否则容易造成用户的误解,以下介绍2中开发思路.
建议都进行阅读并对比两种思路的优劣.
1 常规开发思想
Sku 多维属性状态判断算法
2 利用质因数分解的方式进行开发
不同于上一种方式的多级遍历,此种方式利用任何数的质因数分解的结果唯一性去判断路径,比上一种方式的算法复杂度更低.
将数据1转化为以下格式
// 数据4
[["绿色", "红色", "蓝色"], ["2016款", "2017款", "2018款"], ["S", "M", "L"]]
将数据4按顺序转化为质数
// 数据5
[[2, 3, 5], [7, 11, 13], [17, 19, 23]]
根据数据1和数据5获得可行路径下每个sku选项对应质数的乘积
// 数据6
// {"颜色" : "绿色", "款式" : "2018款", "尺码" : "M", "sku_id" : "1", "prime" : 494},
// {"颜色" : "红色", "款式" : "2016款", "尺码" : "M", "sku_id" : "2", "prime"},
// {"颜色" : "绿色", "款式" : "2016款", "尺码" : "S", "sku_id" : "3"},
// {"颜色" : "蓝色", "款式" : "2017款", "尺码" : "L", "sku_id" : "4"},
// {"颜色" : "绿色", "款式" : "2018款", "尺码" : "L", "sku_id" : "5"}
// 绿 - 2018 - M = 2 * 13 * 19 = 494
// 红 - 2016 - M = 3 * 7 * 19 = 399
// 绿 - 2016 - S = 2 * 7 * 17 = 238
// 蓝 - 2017 - L = 5 * 11 * 23 = 1265
// 绿 - 2018 - L = 2 * 13 * 23 = 598
[494, 399, 238, 1265, 598]
然后维护一个每个sku单元组当前选中的质数(如果未选则为1)的数组,格式如下:
// 数据7
// 全不选
[1, 1, 1]
// 红 - 没选 - L
[3, 1, 23]
// 没选 - 2017 -M
[1, 11, 19]
假如都没选的情况下,点击了选中了绿色+L.则数据7
// 数据7的转化
[1, 1, 1] -> [2, 1, 23]
此时开始可以计算每个sku单元状态的调整:
每个 sku单元分为3中状态
计算流程如下:
1.通过判断sku单元对应的质数是否在数据7中出现来确定是否是状态1,如果存在则返回状态1. 如果不存在则继续进行计算
2.对数据7进行魔改将sku单元所在行的质数改为自己对应的字数并记录在一个临时数据8中
// 数据7此时状态
[2, 1, 23]
// 对于"红色"数据8为
[3, 1, 23]
// 对于"M"数据8为
[2, 1, 19]
// 对于"2018" 数据9为
[2, 13, 23]
// ...
3.将每个sku单元的数据8中的数据累乘并记录一个临时数据9
// 数据7此时状态
[2, 1, 23]
// 对于"红色"数据9为
3 * 1 * 23 = 69
// 对于"M"数据8为
2 * 1 * 19 = 38
// 对于"2018" 数据9为
2 * 13 * 23 = 598
// ...
4.每个sku单元用自己的数据9去对数据6中的数据进行除法运算如果能整除则为状态2反之为状态3
// "红色" 数据9: 69
无整除结果返回状态3
// "M" 数据9: 38
存在可以整除的数494 返回状态2
// "2018" 数据9: 598
存在可以整除的数598 返回状态2
-
结果如图:
 image-201804201142358的副本.png
image-201804201142358的副本.png
Demo地址
skuDemo