kaggle:BrackFriday数据集分析
数据
kaggle地址:https://www.kaggle.com/mehdidag/black-friday
也可以去我的资源里下
一、导入数据
老样子,用pd.read_csv导入,数据集共54w条数据只有23M,不用担心(之前分析一个220M的数据集直接把我电脑卡死了…)
data = pd.read_csv('./data/BlackFriday.csv')
data.head()
>>>
User_ID Product_ID Gender Age Occupation City_Category Stay_In... Marital_Status Product_Category_1 Product_Category_2 Product_Category_3 Purchase
0 1000001 P00069042 F 0-17 10 A 2 0 3 0.0 0.0 8370
1 1000001 P00248942 F 0-17 10 A 2 0 1 6.0 14.0 15200
2 1000001 P00087842 F 0-17 10 A 2 0 12 0.0 0.0 1422
3 1000001 P00085442 F 0-17 10 A 2 0 12 14.0 0.0 1057
4 1000002 P00285442 M 55+ 16 C 4+ 0 8 0.0 0.0 7969
二、处理空值
data.apply(lambda col: sum(col.isnull())/col.size)
>>>
User_ID 0.000000
Product_ID 0.000000
Gender 0.000000
Age 0.000000
Occupation 0.000000
City_Category 0.000000
Stay_In_Current_City_Years 0.000000
Marital_Status 0.000000
Product_Category_1 0.000000
Product_Category_2 0.310627
Product_Category_3 0.694410
Purchase 0.000000
dtype: float64
Product_Category_2和Product_Category_3存在大量的空值,这俩个值的数值类型为float64再考虑到这是产品类别,没有类别就把它用0.0填充,方便后续分析,也可以考虑删除列。
三、分析数据
1.得到消费直方图
plt.figure
plt.hist(data['Purchase'],bins=100)
plt.xlabel('purchase')
plt.ylabel('count')
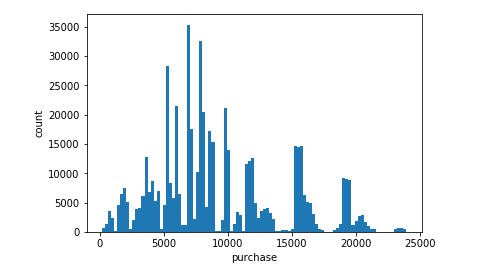
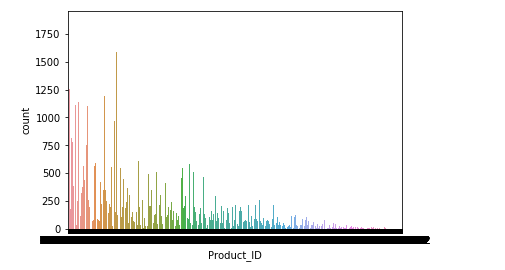
2.得到每个产品被购买的次数和用户购买产品数量
plt.figure()
sns.countplot(data['Product_ID'])
plt.figure()
sns.countplot(data['User_ID'])
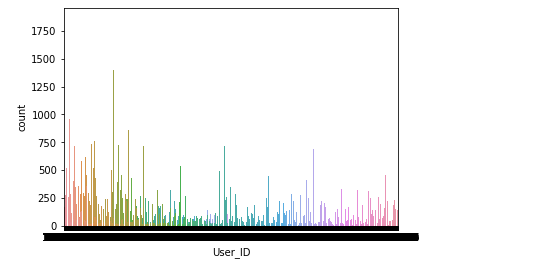
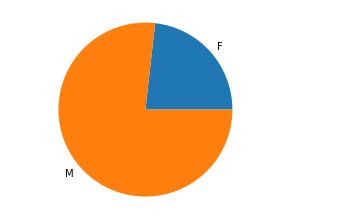
3.不同性别消费统计
该数据集中同一用户存在多次购买行为,所以在计算人数时需要先按照User_ID分组,统计下来共有5891位用户,总数据量为537577,平均每位用户购买了91.25件商品(买买买…)。
# 人数统计
user = data.groupby(['User_ID','Gender'])
c_user = user.count().count(level='Gender')
g_user = c_user.count(level='Gender')
plt.figure()
plt.pie(g_user['Age'],labels=['F','M'])
# 消费统计
gender_sum_user = user.sum()
gender_sum_user = gender_sum_user.sum(level='Gender')
plt.figure()
plt.pie(gender_sum_user['Purches'],labels=['F','M'])
结果:男人比女人会花钱
女性人数为1666,男性人数为4225,比例大约为1:2.5
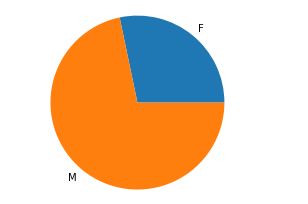
消费方面女性消费共11.6亿,男性消费38.5亿,比例大约为1:3.3
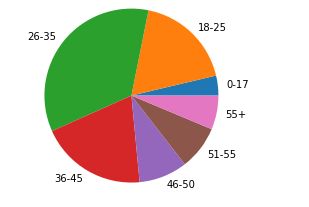
4.不同年龄段统计
# 统计人数
age = data.groupby(['User_ID','Age'])
c_age = age.count().count(level='Age')
plt.figure()
plt.pie(c_age['Gender'],labels=[i for i in c_age.index])
人数统计:
四、拟合
1.特征值处理
前面已经把缺失值进行处理了,这里由于User_ID和Product_ID数量过多使用LabelEncode处理,把他们转换成方便处理的数据类型。同时对其余的非数值类特征进行one-hot编码。
le = LabelEncoder()
data['User_ID'] = le.fit_transform(data['User_ID'])
data['Product_ID'] = le.fit_transform(data['Product_ID'])
data_AGCS = pd.get_dummies(data,columns=['Age','Gender', 'City_Category', 'Stay_In_Current_City_Years'])
data_encoded = pd.concat([data.drop('Purchase',axis=1), data_AGCS], axis=1)
data_encoded.drop(['Age','Gender', 'City_Category', 'Stay_In_Current_City_Years'], axis=1, inplace=True)
标准化后划分训练集、测试集
X = data_encoded.drop('Purchase',axis=1)
y = data_encoded['Purchase']
# 标准化
std = StandardScaler()
X = std.fit_transform(X)
X_train,X_test,y_train,y_test = train_test_split(X,y)
训练
rfr = RandomForestRegressor(n_estimators=10)
rfr.fit(X_train, y_train)
y_pre = rfr.predict(X_test)
print(y_pre)
五、预测结果

六、超参数调优
parameter_space = {
"n_estimators": [2,3,4,5,6,7],
"min_samples_leaf": [2],
}
estimator = RandomForestRegressor()
rfr_cv = GridSearchCV(estimator, parameter_space, cv=4)
rfr_cv.fit(X_train,y_train)
print(rfr_cv.best_params_)
print(rfr_cv.best_score_)
我的渣渣电脑跑了大概10分钟。。。得到结果:

源代码:https://github.com/DeepDarkFood/blackfriday_pre