CenterNet踩坑记
借鉴了两位大佬的训练指导(非常感谢)
https://blog.csdn.net/weixin_42634342/article/details/97756458
https://blog.csdn.net/weixin_41765699/article/details/100118353
记录一下自己实验的情况(纯小白)
我的数据集一共6069张,3885张训练,1213张验证,971张测试(其实用7:2:1划分即可,我分的太乱了)
首先是常规流程
我的环境为cuda10.0 cudnn7.6 pytorch1.1.0
装CenterNet环境结合官方和这个issue安装,切记2080显卡pytorch需要装1.1版本:
https://github.com/xingyizhou/CenterNet
https://github.com/xingyizhou/CenterNet/issues/356
重点:

训练自己的数据
1.在CenterNet/src/lib/datasets/dataset文件夹中,依据coco.py新建自己数据集的文件work.py
import torch.utils.data as data
class Work(data.Dataset):
num_classes = 3
default_resolution = [512, 512]
mean = np.array([0.423766, 0.424928, 0.390202],
dtype=np.float32).reshape(1, 1, 3)
std = np.array([0.215500, 0.212954, 0.228594],
dtype=np.float32).reshape(1, 1, 3)
def __init__(self, opt, split):
super(Work, self).__init__()
self.data_dir = os.path.join(opt.data_dir, 'work')
self.img_dir = os.path.join(self.data_dir, 'images')
(1)这里出现了第一个不同于指导的地方是num_class,我的数据集有两类,当我填2的时候,出现了这个issue的错误:https://github.com/xingyizhou/CenterNet/issues/347
我的解决方法是num_classes改成3(两个类别+背景类),但是issue还有个老哥提出的原因是因为数据集存放目录不对,但是我改成3后是没有错的,就先这样处理了
均值和方差的计算在指导的网址中有,但是不建议尺寸不一的图片进行处理(因为算均值和方差需要统一图片尺寸,当统一了图片尺寸时还需要将标签也做一样的处理,较麻烦),直接使用coco数据集的均值和方差即可
if split == 'val':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'val.json').format(split)
else:
if opt.task == 'exdet':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json').format(split)
#if split == 'test':
#self.annot_path = os.path.join(
#self.data_dir, 'annotations',
#'test.json').format(split)
else:
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json').format(split)
(2)在测试时将注释部分取消注释即可
self.class_name = [
'__background__', 'blue' , 'darke']
self._valid_ids = [
0, 1, 2]
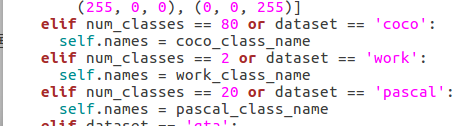
(3)更改类别(建议标号从0开始)
2.将数据集加入src/lib/datasets/dataset_factory里面

3.修改/src/lib/opts.py


这里我更改了学习率,因为使用autogluon训练了一小部分数据集(1000张训练),学习率1.25e-4和1e-4中,1e-4更适合我的数据集,使用一张2080的卡,batch_size设为16会出现下图错误,所以设为8


均值方差还是设为coco默认的就好
4.修改/src/lib/utils/debugger.py

正常准备到这里就可以了,但是还是依据其中一个指导更改了test.py文件
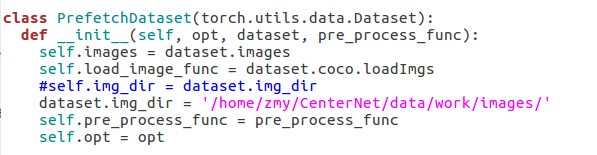
改成了绝对路径,然后再修改/src/lib/datasets/sample/ctdet.py文件

若需要保存测试的结果图,则在src/lib/detectors/cdet.py文件最后加一句

其次为我出现的错误
1.训练正常,map值很高,loss值很低,但是显示测试集检测效果时却什么都没显示,即使有显示的框也是偏离的

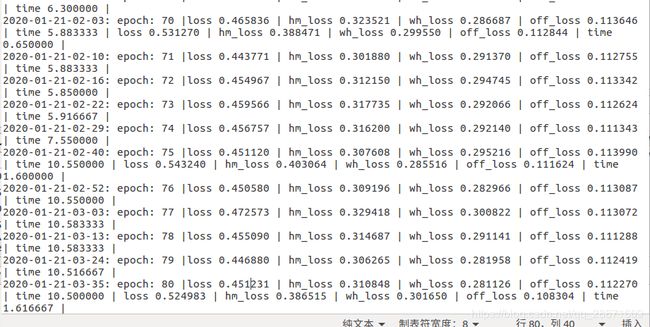
我的log.txt:大概是正常的吧?
于是我返回去查标签了,发现依据教程转换的json文件和xml文件的框的标签无法对应,不知道是否是转换出错![]()
![]()

怀疑原因有:(1)标签路径含有中文,导致转换出错(已排除,修改路径后还是错误);
(2)xml2json.py代码出错(也不是,生成的json文件bbox为xmin,ymin,w,h(左上角点坐标,宽,高)
好像模型过拟合了
验证集可视化结果

测试集可视化
