OpenCv学习笔记4--图像分割之GrabCut算法
说明: 本文章是opencv学习笔记系列的第四篇小结,可能前几篇内容太多,排版也不甚合理,所以为了更好的观看体验,这次的内容会稍微少那么一点点,再次重申
所有代码在我的github主页https://github.com/RenDong3/OpenCV_Notes.
欢迎star,不定时更新...
所谓图像分割指的是根据灰度、颜色、纹理和形状等特征把图像划分成若干互不交迭的区域,并使这些特征在同一区域内呈现出相似性,而在不同区域间呈现出明显的差异性。我们先对目前主要的图像分割方法做个概述,后面再对个别方法做详细的了解和学习。
一、图像分割算法概述
1、基于阈值的分割方法
阈值法的基本思想是基于图像的灰度特征来计算一个或多个灰度阈值,并将图像中每个像素的灰度值与阈值相比较,最后将像素根据比较结果分到合适的类别中。因此,该类方法最为关键的一步就是按照某个准则函数来求解最佳灰度阈值。
2、基于边缘的分割方法
所谓边缘是指图像中两个不同区域的边界线上连续的像素点的集合,是图像局部特征不连续性的反映,体现了灰度、颜色、纹理等图像特性的突变。通常情况下,基于边缘的分割方法指的是基于灰度值的边缘检测,它是建立在边缘灰度值会呈现出阶跃型或屋顶型变化这一观测基础上的方法。
阶跃型边缘两边像素点的灰度值存在着明显的差异,而屋顶型边缘则位于灰度值上升或下降的转折处。正是基于这一特性,可以使用微分算子进行边缘检测,即使用一阶导数的极值与二阶导数的过零点来确定边缘,具体实现时可以使用图像与模板进行卷积来完成。
3、基于区域的分割方法
此类方法是将图像按照相似性准则分成不同的区域,主要包括种子区域生长法、区域分裂合并法和分水岭法等几种类型。
种子区域生长法是从一组代表不同生长区域的种子像素开始,接下来将种子像素邻域里符合条件的像素合并到种子像素所代表的生长区域中,并将新添加的像素作为新的种子像素继续合并过程,直到找不到符合条件的新像素为止。该方法的关键是选择合适的初始种子像素以及合理的生长准则。
区域分裂合并法(Gonzalez,2002)的基本思想是首先将图像任意分成若干互不相交的区域,然后再按照相关准则对这些区域进行分裂或者合并从而完成分割任务,该方法既适用于灰度图像分割也适用于纹理图像分割。
分水岭法(Meyer,1990)是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。该算法的实现可以模拟成洪水淹没的过程,图像的最低点首先被淹没,然后水逐渐淹没整个山谷。当水位到达一定高度的时候将会溢出,这时在水溢出的地方修建堤坝,重复这个过程直到整个图像上的点全部被淹没,这时所建立的一系列堤坝就成为分开各个盆地的分水岭。分水岭算法对微弱的边缘有着良好的响应,但图像中的噪声会使分水岭算法产生过分割的现象。
4、基于图论的分割方法
此类方法把图像分割问题与图的最小割(min cut)问题相关联。首先将图像映射为带权无向图G=
5、基于能量泛函的分割方法
该类方法主要指的是活动轮廓模型(active contour model)以及在其基础上发展出来的算法,其基本思想是使用连续曲线来表达目标边缘,并定义一个能量泛函使得其自变量包括边缘曲线,因此分割过程就转变为求解能量泛函的最小值的过程,一般可通过求解函数对应的欧拉(Euler.Lagrange)方程来实现,能量达到最小时的曲线位置就是目标的轮廓所在。按照模型中曲线表达形式的不同,活动轮廓模型可以分为两大类:参数活动轮廓模型(parametric active contour model)和几何活动轮廓模型(geometric active contour model)。
参数活动轮廓模型是基于Lagrange框架,直接以曲线的参数化形式来表达曲线,最具代表性的是由Kasset a1(1987)所提出的Snake模型。该类模型在早期的生物图像分割领域得到了成功的应用,但其存在着分割结果受初始轮廓的设置影响较大以及难以处理曲线拓扑结构变化等缺点,此外其能量泛函只依赖于曲线参数的选择,与物体的几何形状无关,这也限制了其进一步的应用。
几何活动轮廓模型的曲线运动过程是基于曲线的几何度量参数而非曲线的表达参数,因此可以较好地处理拓扑结构的变化,并可以解决参数活动轮廓模型难以解决的问题。而水平集(Level Set)方法(Osher,1988)的引入,则极大地推动了几何活动轮廓模型的发展,因此几何活动轮廓模型一般也可被称为水平集方法。
二、图像分割之GrabCut算法
这里不去介绍GrabCut算法的原理,感兴趣的童鞋去参考博客后面的文章。该算法主要基于以下知识:
-
k均值聚类
- 高斯混合模型建模(GMM)
- max flow/min cut
这里介绍一些GrabCut算法的实现步骤:
- 在图片中定义(一个或者多个)包含物体的矩形。
- 矩形外的区域被自动认为是背景。
- 对于用户定义的矩形区域,可用背景中的数据来区分它里面的前景和背景区域。
- 用高斯混合模型(GMM)来对背景和前景建模,并将未定义的像素标记为可能的前景或者背景。
- 图像中的每一个像素都被看做通过虚拟边与周围像素相连接,而每条边都有一个属于前景或者背景的概率,这是基于它与周边像素颜色上的相似性。
- 每一个像素(即算法中的节点)会与一个前景或背景节点连接。
- 在节点完成连接后(可能与背景或前景连接),若节点之间的边属于不同终端(即一个节点属于前景,另一个节点属于背景),则会切断他们之间的边,这就能将图像各部分分割出来。下图能很好的说明该算法:
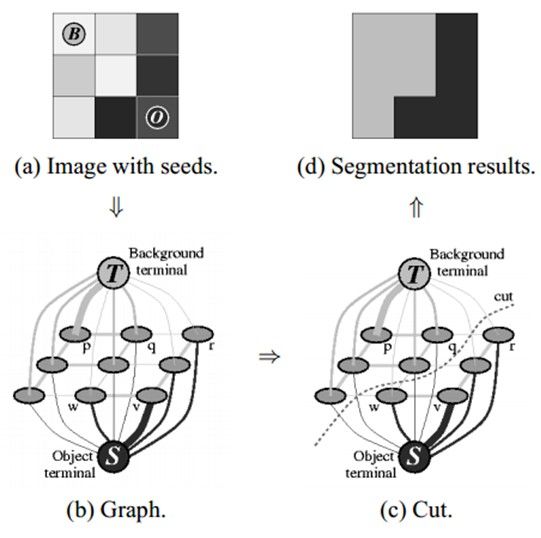
OpenCV提供了GrabCut算法相关的函数,grabCut函数:
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) → None输入:图像、被标记好的前景、背景
输出:分割图像
其中输入的前景、背景指的是一种概率,如果你已经明确某一块区域是背景,那么它属于背景的概率为1;当然如果你觉得它有可能背景,但是没有百分百的肯定,这个时候你就要用到高斯模型,对其进行建模,然后估算概率。现在我以下图为例,用户通过交互输入框选区域,前景位于框选区域内,也就是说矩形区域外的全部属于背景,且概率为百分百。然后方框内可能属于前景,概率需要用高斯混合建模求解。
| 参数: |
|
|---|
上面是属于opencv官方文档的讲解,不过个人感觉大神给出的解释更加通俗透彻,这里放上来,可以对比看下.
参数说明:
- img——待分割的源图像,必须是8位3通道,在处理的过程中不会被修改
- mask——掩码图像,如果使用掩码进行初始化,那么mask保存初始化掩码信息;在执行分割的时候,也可以将用户交互所设定的前景与背景保存到mask中,然后再传入grabCut函数;在处理结束之后,mask中会保存结果。mask只能取以下四种值:
GCD_BGD(=0),背景;
GCD_FGD(=1),前景;
GCD_PR_BGD(=2),可能的背景;
GCD_PR_FGD(=3),可能的前景。
如果没有手工标记GCD_BGD或者GCD_FGD,那么结果只会有GCD_PR_BGD或GCD_PR_FGD;
- rect——用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理;
- bgdModel——背景模型,如果为None,函数内部会自动创建一个bgdModel;bgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5;
- fgdModel——前景模型,如果为None,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5;
- iterCount——迭代次数,必须大于0;
- mode——用于指示grabCut函数进行什么操作,可选的值有:
GC_INIT_WITH_RECT(=0),用矩形窗初始化GrabCut;
GC_INIT_WITH_MASK(=1),用掩码图像初始化GrabCut;
GC_EVAL(=2),执行分割。
OK, 下面给出第一个简单的例子,这是关于grabcut算法的第一个初级代码,直接给定rect[ ],指定ROI.,和往常一样,代码可以直接copy运行.
完整代码如下:
# -*- coding:utf-8 -*-
import cv2
import numpy as np
'''
created on 08:10:27 2018-11-15
@author:ren_dong
Grabcut 图像分割
直接给定矩形区域作为ROI
GrabCut算法的实现步骤:
1 在图片中定义(一个或者多个)包含物体的矩形。
2 矩形外的区域被自动认为是背景。
3 对于用户定义的矩形区域,可用背景中的数据来区分它里面的前景和背景区域。
4 用高斯混合模型(GMM)来对背景和前景建模,并将未定义的像素标记为可能的前景或者背景。
5 图像中的每一个像素都被看做通过虚拟边与周围像素相连接,而每条边都有一个属于前景或者背景的概率,这是基于它与周边像素颜色上的相似性。
6 每一个像素(即算法中的节点)会与一个前景或背景节点连接。
7 在节点完成连接后(可能与背景或前景连接),若节点之间的边属于不同终端(即一个节点属于前景,另一个节点属于背景),则会切断他们之间的边,这就能将图像各部分分割出来。
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) → None
'''
#载入图像img
fname = 'test.jpg'
img = cv2.imread(fname)
#设定矩形区域 作为ROI 矩形区域外作为背景
rect = (275, 120, 170, 320)
#img.shape[:2]得到img的row 和 col ,
# 得到和img尺寸一样的掩模即mask ,然后用0填充
mask = np.zeros(img.shape[:2], np.uint8)
#创建以0填充的前景和背景模型, 输入必须是单通道的浮点型图像, 1行, 13x5 = 65的列 即(1,65)
bgModel = np.zeros((1,65), np.float64)
fgModel = np.zeros((1,65), np.float64)
#调用grabcut函数进行分割,输入图像img, mask, mode为 cv2.GC_INIT_WITH-RECT
cv2.grabCut(img, mask, rect, bgModel, fgModel, 5, cv2.GC_INIT_WITH_RECT)
##调用grabcut得到rect[0,1,2,3],将0,2合并为0, 1,3合并为1 存放于mask2中
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype(np.uint8)
#得到输出图像
out = img * mask2[:, :, np.newaxis]
cv2.imshow('origin', img)
cv2.imshow('grabcut', out)
cv2.waitKey()
cv2.destroyAllWindows()
下面是代码运行结果展示:


左图为原始图像,右图为进行grabcut算法处理之后的图像,我们完成了抠图, [斜眼] !
可能对于某些图片不能准确的指定任务或者ROI所在的区域,所以我们对上述程序进行了改进,加入了鼠标回调函数,可以进行交互式鼠标选取ROI,然后进行grabcut处理,可以说是完整版的grabcut算法.
完整代码如下:
# -*- coding:utf-8 -*-
import cv2
import numpy as np
'''
created on 08:10:27 2018-11-15
@author:ren_dong
Grabcut 图像分割
加入鼠标回调函数,可以进行交互式操作,鼠标选择矩形区域作为ROI
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) → None
on_mouse()
'''
# 鼠标事件的回调函数
def on_mouse(event, x, y, flag, param):
global rect
global leftButtonDown
global leftButtonUp
# 鼠标左键按下
if event == cv2.EVENT_LBUTTONDOWN:
rect[0] = x
rect[2] = x
rect[1] = y
rect[3] = y
leftButtonDown = True
leftButtonUp = False
# 移动鼠标事件
if event == cv2.EVENT_MOUSEMOVE:
if leftButtonDown and not leftButtonUp:
rect[2] = x
rect[3] = y
# 鼠标左键松开
if event == cv2.EVENT_LBUTTONUP:
if leftButtonDown and not leftButtonUp:
x_min = min(rect[0], rect[2])
y_min = min(rect[1], rect[3])
x_max = max(rect[0], rect[2])
y_max = max(rect[1], rect[3])
rect[0] = x_min
rect[1] = y_min
rect[2] = x_max
rect[3] = y_max
leftButtonDown = False
leftButtonUp = True
# 读入图片
img = cv2.imread('ouc.jpg')
'''
掩码图像,如果使用掩码进行初始化,那么mask保存初始化掩码信息;
在执行分割的时候,也可以将用户交互所设定的前景与背景保存到mask中,
然后再传入grabCut函数;
在处理结束之后,mask中会保存结果
'''
#img.shape[:2]=img.shape[0:2] 代表取彩色图像的长和宽 img.shape[:3] 代表取长+宽+通道
mask = np.zeros(img.shape[:2], np.uint8)
# 背景模型,如果为None,函数内部会自动创建一个bgdModel;bgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5;
bgdModel = np.zeros((1, 65), np.float64)
# fgdModel——前景模型,如果为None,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5;
fgdModel = np.zeros((1, 65), np.float64)
# 用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理;
# rect 初始化
rect = [0, 0, 0, 0]
# 鼠标左键按下
leftButtonDown = False
# 鼠标左键松开
leftButtonUp = True
# 指定窗口名来创建窗口
cv2.namedWindow('img')
# 设置鼠标事件回调函数 来获取鼠标输入
cv2.setMouseCallback('img', on_mouse)
# 显示图片
cv2.imshow('img', img)
##设定循环,进行交互式操作
while cv2.waitKey(2) == -1:
# 左键按下,画矩阵
if leftButtonDown and not leftButtonUp:
img_copy = img.copy()
# 在img图像上,绘制矩形 线条颜色为green 线宽为2
cv2.rectangle(img_copy, (rect[0], rect[1]), (rect[2], rect[3]), (0, 255, 0), 2)
# 显示图片
cv2.imshow('img', img_copy)
# 左键松开,矩形画好
elif not leftButtonDown and leftButtonUp and rect[2] - rect[0] != 0 and rect[3] - rect[1] != 0:
# 转换为宽度高度
rect[2] = rect[2] - rect[0]
rect[3] = rect[3] - rect[1]
# rect_copy = tuple(rect.copy())
rect_copy = tuple(rect)
rect = [0, 0, 0, 0]
# 物体分割
cv2.grabCut(img, mask, rect_copy, bgdModel, fgdModel, 5, cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
img_show = img * mask2[:, :, np.newaxis]
# 显示图片分割后结果
cv2.imshow('grabcut', img_show)
# 显示原图
cv2.imshow('img', img)
cv2.waitKey()
cv2.destroyAllWindows()下面是结果展示区:


调用完grabCut函数之后,掩模图像mask元素值已经变成了0~3之间的值。值为0和2的将转为0,值为1和3的将转为1,然后保存在mask2中,这样就可以用mask2过滤出所有的0值像素(理论上会保存所有的前景像素)。
OK,上面展示了我的在读院校(惭愧...),我们使用鼠标选取了标志所在的区域作为ROI,右图就是grabcut算法处理之后的结果,效果还不错.
这是说明一下,其实大部分内容是参考大神博客进行编写的,所以这里一直使用笔记作为记录标志,我只是在理解别人的思路,后来发现我写出的不如大神的理解深刻,所以这里给出大神的博客地址,非常感谢这些博主.
大神博客:https://www.cnblogs.com/zyly/p/9392881.html
opencv官方文档:https://docs.opencv.org/2.4/modules/imgproc/doc/miscellaneous_transformations.html?highlight=cv2.grab#cv2.grabCut
个人github主页:https://github.com/RenDong3/OpenCV_Notes