生成对抗网络入门详解及TensorFlow源码实现--深度学习笔记
生成对抗网络入门详解及TensorFlow源码实现–深度学习笔记
一、生成对抗网络(GANs)
生成对抗网络是一种生成模型(Generative Model),其背后最基本的思想就是从训练库里获取很多的训练样本(Training Examples),从而学习这些训练案例生成的概率分布。
GAN[Goodfellow Ian,GAN]启发自博弈论中的二人零和博弈(two-player game),由[Goodfellow et al, NIPS 2014]开创性地提出。在二人零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当。生成模型G捕捉样本数据的分布,判别模型是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率。G和D一般都是非线性映射函数,例如多层感知机、卷积神经网络等。
二、生成对抗网络的原理
1、生成对抗过程
GANs的方法,就是让两个网络相互竞争“玩一个游戏”。
其中一个叫做生成器网络( Generator Network),它不断捕捉训练库里真实图片的概率分布,将输入的随机噪声(Random Noise)转变成新的样本(也就是假数据)。
另一个叫做判别器网络(Discriminator Network),它可以同时观察真实和假造的数据,判断这个数据到底是不是真的。
所以整个训练过程包含两步,(在下图里,判别器用 D 表示,生成器用 G 表示,真实数据库样本用 X 表示,噪声用 Z 表示)。
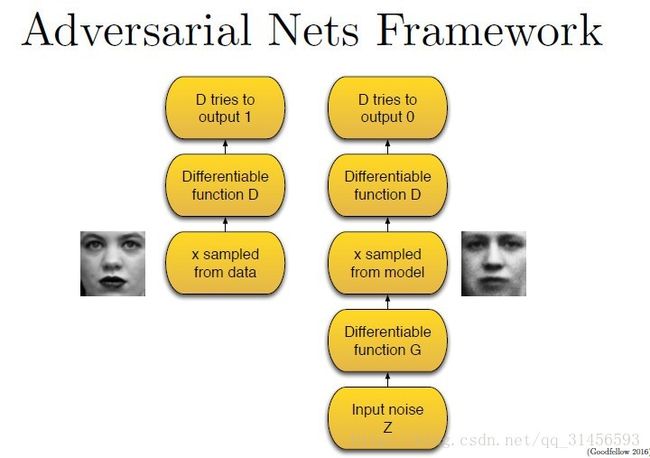
第一步,只有判别器D参与。
我们把X样本输入可微函数D里运行,D输出0-1之间的某个值,数值越大意味着X样本是真实的可能性越大。在这个过程中,判别器D尽可能使输出的值靠近1,因为这一阶段的X样本就是真实的图片。
第二步,判别器D和生成器G都参与。
我们首先将噪声数据Z喂给生成器G,G从原有真实图像库里学习概率分布,从而产生假的图像样本。然后,我们把假的数据交给判别器D。这一次,D将尽可能输入数值0,这代表着输入数据Z是假的。
所以这个过程中,判别器D相当于一个监督情况下的二分类器,数据要么归为1,要么归为0。
与传统神经网络训练不一样的且有趣的地方,就是我们训练生成器的方法不同。生成器一心想要“骗过”判别器。使用博弈理论分析技术,我们可以证明这里面存在一种均衡。
2、数学原理
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
以上只是大致说了一下GAN的核心原理,如何用数学语言描述呢?这里直接摘录论文里的公式:
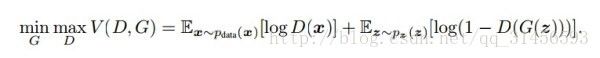
简单分析一下这个公式:
• 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
• D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
• G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
• D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
三、GAN的优势与缺陷
1、优势
• 根据实际的结果,它们看上去可以比其它模型产生了更好的样本(图像更锐利、清晰)。
• 生成对抗式网络框架能训练任何一种生成器网络(理论上-实践中,用 REINFORCE 来训练带有离散输出的生成网络非常困难)。大部分其他的框架需要该生成器网络有一些特定的函数形式,比如输出层是高斯的。重要的是所有其他的框架需要生成器网络遍布非零质量(non-zero mass)。生成对抗式网络能学习可以仅在与数据接近的细流形(thin manifold)上生成点。
• 不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何鉴别器都会有用。
• 无需利用马尔科夫链反复采样,无需在学习过程中进行推断(Inference),回避了近似计算棘手的概率的难题。
2、存在的主要问题:
• 解决不收敛(non-convergence)的问题。
目前面临的基本问题是:所有的理论都认为 GAN 应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的【OpenAI Ian Goodfellow的Quora】。
• 难以训练:崩溃问题(collapse problem)
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
• 无需预先建模,模型过于自由不可控。
与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。在GAN[Goodfellow Ian, Pouget-Abadie J] 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
四、DCGANs:深度卷积生成对抗网络
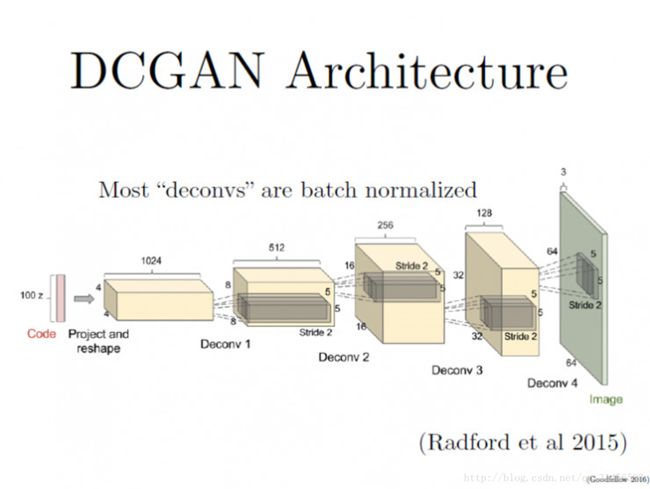
DCGANs的基本架构就是使用几层“反卷积”(Deconvolution)网络。“反卷积”类似于一种反向卷积,这跟用反向传播算法训练监督的卷积神经网络(CNN)是类似的操作。
CNN是将图像的尺寸压缩,变得越来越小,而反卷积是将初始输入的小数据(噪声)变得越来越大(但反卷积并不是CNN的逆向操作,这个下面会有详解)。
如果你要把卷积核移动不止一个位置, 使用的卷积滑动步长更大,那么在反卷积的每一层,你所得到的图像尺寸就会越大。
这个论文里另一个重要思想,就是在大部分网络层中使用了“批量规范化”(batch normalization),这让学习过程的速度更快且更稳定。另一个有趣的思想就是,如何处理生成器里的“池化层”(Pooling Layers),传统CNN使用的池化层,往往取区域平均或最大来压缩表征数据的尺寸。
在反卷积过程中,从代码到最终生成图片,表征数据变得越来越大,我们需要某个东西来逐渐扩大表征的尺寸。但最大值池化(max-pooling)过程并不可逆,所以DCGANs那篇论文里,并没有采用池化的逆向操作,而只是让“反卷积”的滑动步长设定为2或更大值,这一方法确实会让表征尺寸按我们的需求增大。
DCGANs非常擅长生成特定Domain里的小图片,这里是一些生成的“卧室”图片样本。这些图片分辨率不是很高,但是你可以看到里面包含了门、窗户、棉被、枕头、床头板、灯具等卧室常见物品。

五、生成对抗网络应用
1、GANs的应用:“文本转图像”(Text to Image)
我们可以用GANs做很多应用,其中一种就是“文本转图像”(Text to Image)。在Scott Reed等人的一篇论文里(Generative Adversarial Text to Image Synthesis,链接 https://arxiv.org/abs/1605.05396),GANs根据输入的信息产生了相关图像,。
也就是说,生成器里输入的不仅是随机噪声,还有一些特定的语句信息。所以判别器不仅要区分样本是否是真实的,还要判定其是否与输入的语句信息相符。
这里是他们的实验结果,左上角的图里有一些鸟,鸟的胸脯和鸟冠是是粉色,主羽和次羽是黑色,与所给语句描述的信息相符。

但是我们也看到,仍然存在“模型崩溃”问题,在右下角的黄白花里,确实产生了白色花瓣和黄色花蕊的花朵,但它们多少看起来是在同一个方向上映射出来的同一朵花,它们的花瓣数和尺寸几乎相同。
所以,模型在输出的多样性方面还有些问题,这需要解决。但可喜的地方在于,输入的语句信息都比较好的映射到产生的图像样本中。
2、有趣的GANs 图像生成应用
在Indico和Facebook发布了他们自己的DCGAN代码之后,很多人开发出他们自己的、有趣的GANs应用。有的生成新的花朵图像,还有新动漫角色。我个人最喜欢的,是一个能生成新品种精灵宝可梦的应用。

在一个 Youtube 视频,你会看到学习过程:生成器被迫去学习怎么骗过判别器,图像逐渐变得更真实。有些生成的宝可梦,虽然它们是全新的品种,看上去就像真的一样。这些图像的真实感并没有一些专业学术论文里面的那么强,但对于现在的生成模型来说,不经过任何额外处理就能得到这样的结果,已经非常不错了。
3、超分辨率
一篇最近发表的论文,描述怎么利用GANs进行超分辨率重建(Super-Resolution)。我不确定这能否在本视频中体现出来,因为视频清晰度的限制。基本思想是,你可以在有条件的GANs里,输入低分辨率图像,然后输出高分版本。使用生成模型的原因在于,这是一个约束不足(underconstrained)的问题:对于任何一个低分辨率图像,有无数种可能的高分辨率版本。相比其他生成模型,GANs特别适用超分辨率应用。因为GANs的专长就是创建极有真实感的样本。它们并不特别擅长做概率函数密度的估测,但在超分辨率应用中,我们最终关心的是输出高分图像,而不是概率分布。

(从左到右分别为:图1、2、3、4)
上面展示的四幅图像中,最左边的是原始高分图像(图1),剩下的其余三张图片都是通过对图片的降采样(Down Sample)生成的。我们把降采样得到的图片用不同的方法进行放大,以期得到跟原始图像同样的品质。
这些方法有很多种,比如我们用双三次插值(Bicubic Interpolation)方式,生成的图像(图2)看起来很模糊,且对比度很低。另一个深度学习方法SRResNet(图3)的效果更好,图片已经干净了很多。但若采用GANs重建的图片(图4),有着比其它两种方式更低的信噪比。虽然我们直观上觉得图3看起来更清晰,事实上它的信噪比更高一些。GANs在量化矩阵(Quantitative Matrix)和人眼清晰度感知两方面,都有很好的表现。
六、TensorFlow源码(生成手写字体)
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
from skimage.io import imsave
import os
import shutil
img_height = 28
img_width = 28
img_size = img_height * img_width
to_train = True
to_restore = False
output_path = "output"
# 总迭代次数500
max_epoch = 500
h1_size = 150
h2_size = 300
z_size = 100
batch_size = 256
# generate (model 1)
def build_generator(z_prior):
w1 = tf.Variable(tf.truncated_normal([z_size, h1_size], stddev=0.1), name="g_w1", dtype=tf.float32)
b1 = tf.Variable(tf.zeros([h1_size]), name="g_b1", dtype=tf.float32)
h1 = tf.nn.relu(tf.matmul(z_prior, w1) + b1)
w2 = tf.Variable(tf.truncated_normal([h1_size, h2_size], stddev=0.1), name="g_w2", dtype=tf.float32)
b2 = tf.Variable(tf.zeros([h2_size]), name="g_b2", dtype=tf.float32)
h2 = tf.nn.relu(tf.matmul(h1, w2) + b2)
w3 = tf.Variable(tf.truncated_normal([h2_size, img_size], stddev=0.1), name="g_w3", dtype=tf.float32)
b3 = tf.Variable(tf.zeros([img_size]), name="g_b3", dtype=tf.float32)
h3 = tf.matmul(h2, w3) + b3
x_generate = tf.nn.tanh(h3)
g_params = [w1, b1, w2, b2, w3, b3]
return x_generate, g_params
# discriminator (model 2)
def build_discriminator(x_data, x_generated, keep_prob):
# tf.concat
x_in = tf.concat([x_data, x_generated],0)
w1 = tf.Variable(tf.truncated_normal([img_size, h2_size], stddev=0.1), name="d_w1", dtype=tf.float32)
b1 = tf.Variable(tf.zeros([h2_size]), name="d_b1", dtype=tf.float32)
h1 = tf.nn.dropout(tf.nn.relu(tf.matmul(x_in, w1) + b1), keep_prob)
w2 = tf.Variable(tf.truncated_normal([h2_size, h1_size], stddev=0.1), name="d_w2", dtype=tf.float32)
b2 = tf.Variable(tf.zeros([h1_size]), name="d_b2", dtype=tf.float32)
h2 = tf.nn.dropout(tf.nn.relu(tf.matmul(h1, w2) + b2), keep_prob)
w3 = tf.Variable(tf.truncated_normal([h1_size, 1], stddev=0.1), name="d_w3", dtype=tf.float32)
b3 = tf.Variable(tf.zeros([1]), name="d_b3", dtype=tf.float32)
h3 = tf.matmul(h2, w3) + b3
y_data = tf.nn.sigmoid(tf.slice(h3, [0, 0], [batch_size, -1], name=None))
y_generated = tf.nn.sigmoid(tf.slice(h3, [batch_size, 0], [-1, -1], name=None))
d_params = [w1, b1, w2, b2, w3, b3]
return y_data, y_generated, d_params
#
def show_result(batch_res, fname, grid_size=(8, 8), grid_pad=5):
batch_res = 0.5 * batch_res.reshape((batch_res.shape[0], img_height, img_width)) + 0.5
img_h, img_w = batch_res.shape[1], batch_res.shape[2]
grid_h = img_h * grid_size[0] + grid_pad * (grid_size[0] - 1)
grid_w = img_w * grid_size[1] + grid_pad * (grid_size[1] - 1)
img_grid = np.zeros((grid_h, grid_w), dtype=np.uint8)
for i, res in enumerate(batch_res):
if i >= grid_size[0] * grid_size[1]:
break
img = (res) * 255
img = img.astype(np.uint8)
row = (i // grid_size[0]) * (img_h + grid_pad)
col = (i % grid_size[1]) * (img_w + grid_pad)
img_grid[row:row + img_h, col:col + img_w] = img
imsave(fname, img_grid)
def train():
# load data(mnist手写数据集)
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
x_data = tf.placeholder(tf.float32, [batch_size, img_size], name="x_data")
z_prior = tf.placeholder(tf.float32, [batch_size, z_size], name="z_prior")
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
global_step = tf.Variable(0, name="global_step", trainable=False)
# 创建生成模型
x_generated, g_params = build_generator(z_prior)
# 创建判别模型
y_data, y_generated, d_params = build_discriminator(x_data, x_generated, keep_prob)
# 损失函数的设置
d_loss = - (tf.log(y_data) + tf.log(1 - y_generated))
g_loss = - tf.log(y_generated)
optimizer = tf.train.AdamOptimizer(0.0001)
# 两个模型的优化函数
d_trainer = optimizer.minimize(d_loss, var_list=d_params)
g_trainer = optimizer.minimize(g_loss, var_list=g_params)
init = tf.initialize_all_variables()
saver = tf.train.Saver()
# 启动默认图
sess = tf.Session()
# 初始化
sess.run(init)
if to_restore:
chkpt_fname = tf.train.latest_checkpoint(output_path)
saver.restore(sess, chkpt_fname)
else:
if os.path.exists(output_path):
shutil.rmtree(output_path)
os.mkdir(output_path)
z_sample_val = np.random.normal(0, 1, size=(batch_size, z_size)).astype(np.float32)
steps = 60000 / batch_size
for i in range(sess.run(global_step), max_epoch):
for j in np.arange(steps):
# for j in range(steps):
print("epoch:%s, iter:%s" % (i, j))
# 每一步迭代,我们都会加载256个训练样本,然后执行一次train_step
x_value, _ = mnist.train.next_batch(batch_size)
x_value = 2 * x_value.astype(np.float32) - 1
z_value = np.random.normal(0, 1, size=(batch_size, z_size)).astype(np.float32)
# 执行生成
sess.run(d_trainer,
feed_dict={x_data: x_value, z_prior: z_value, keep_prob: np.sum(0.7).astype(np.float32)})
# 执行判别
if j % 1 == 0:
sess.run(g_trainer,
feed_dict={x_data: x_value, z_prior: z_value, keep_prob: np.sum(0.7).astype(np.float32)})
x_gen_val = sess.run(x_generated, feed_dict={z_prior: z_sample_val})
show_result(x_gen_val, "output/sample{0}.jpg".format(i))
z_random_sample_val = np.random.normal(0, 1, size=(batch_size, z_size)).astype(np.float32)
x_gen_val = sess.run(x_generated, feed_dict={z_prior: z_random_sample_val})
show_result(x_gen_val, "output/random_sample{0}.jpg".format(i))
sess.run(tf.assign(global_step, i + 1))
saver.save(sess, os.path.join(output_path, "model"), global_step=global_step)
def test():
z_prior = tf.placeholder(tf.float32, [batch_size, z_size], name="z_prior")
x_generated, _ = build_generator(z_prior)
chkpt_fname = tf.train.latest_checkpoint(output_path)
init = tf.initialize_all_variables()
sess = tf.Session()
saver = tf.train.Saver()
sess.run(init)
saver.restore(sess, chkpt_fname)
z_test_value = np.random.normal(0, 1, size=(batch_size, z_size)).astype(np.float32)
x_gen_val = sess.run(x_generated, feed_dict={z_prior: z_test_value})
show_result(x_gen_val, "output/test_result.jpg")
if __name__ == '__main__':
if to_train:
train()
else:
test()
参考文献
http://blog.csdn.net/solomon1558/article/details/52549409
http://www.leiphone.com/news/201612/eAOGpvFl60EgFSwS.html
http://www.itwendao.com/article/detail/403491.html