机器学习项目(二) 人工智能辅助信息抽取(六)
传统方法解决NER问题
1.基于规则的专家系统:召回低,规则维护复杂,泛化能力差
2.基于特征的监督学习:需要大量特征工程,泛化能力一般
基于DL的NER模型成为主流,并取得了SOTA
深度学习的关键优势在于其强大的表示学习能力,通过向量表示和神经网络学习复杂的组合语义
深度学习可以通过对原始数据进行训练,自动发现分类或检测所需的语义表示
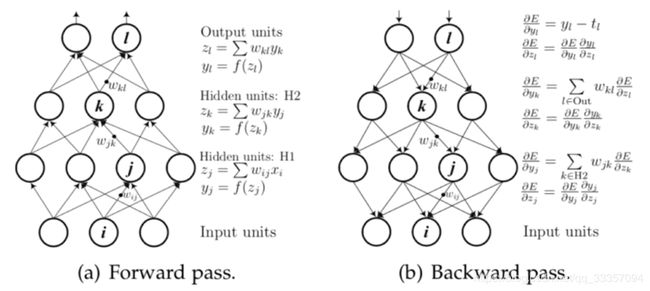
NLP监督任务
基本套路:
文本数据搜集合预处理
将文本进行编码和表征
设计模型解决具体问题
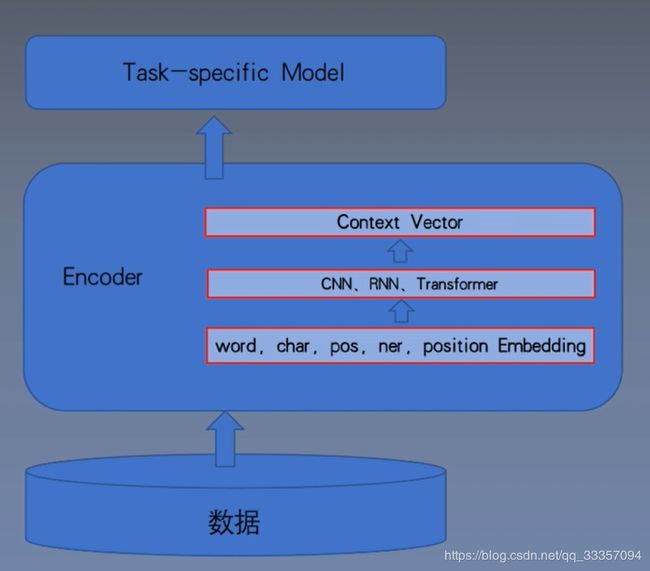
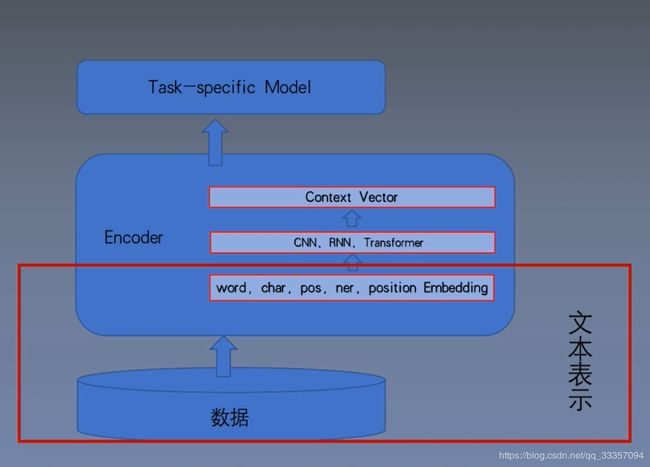
文本表示
文本表示是深度学习进行NLP任务的第一步,将自然语言转化为深度学习能处理的数据
词向量
将自然语言进行数学化
1.one-hot :
维度灾难,不能刻画词与词之间的相似性
2.Distributed:
将词映射成固定长度的短向量,构造词向量空间,通过距离刻画词之间的相似性。
语言模型
语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率
例如:
中国是世界上糖尿病患者最多的国家。
中国是世界上患者最多的国家糖尿病。
中国是师姐上最多的国家糖尿病患者。
给定一个长度为T的词的序列w1,w2,…,wt,语言模型将计算该序列的概率。
假设序列w1,w2,…,wt中的每个词是依次生成的,我们有
P ( w 1 , w 2 , . . . , w T ) = ∏ t = 1 n P ( w t ∣ w 1 , w 2 , . . . , w t − 1 ) P(w_1,w_2,...,w_T) = \prod_{t=1}^n P(w_t|w_1,w_2,...,w_{t-1}) P(w1,w2,...,wT)=t=1∏nP(wt∣w1,w2,...,wt−1)
例如,一段含有四个词的文本序列的概率:
P ( w 1 , w 2 , w 3 , w 4 ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) P ( w 4 ∣ w 1 , w 2 , w 3 ) P(w_1,w_2,w_3,w_4) = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)P(w_4|w_1,w_2,w_3) P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3)
P P ( W ) = P ( w 1 w 2 … w N ) − 1 N = 1 P ( w 1 w 2 … w N N P P(W)=P\left(w_{1} w_{2} \ldots w_{N}\right)^{-\frac{1}{N}}=\sqrt[N]{\frac{1}{P\left(w_{1} w_{2} \ldots w_{N}\right.}} PP(W)=P(w1w2…wN)−N1=NP(w1w2…wN1
N元语言模型
N元语言模型就是假设当前词出现概率只与它前面N-1个单词有关(马尔克夫假设)。而这些概率参数都是可以通过大规模语料库来计算。
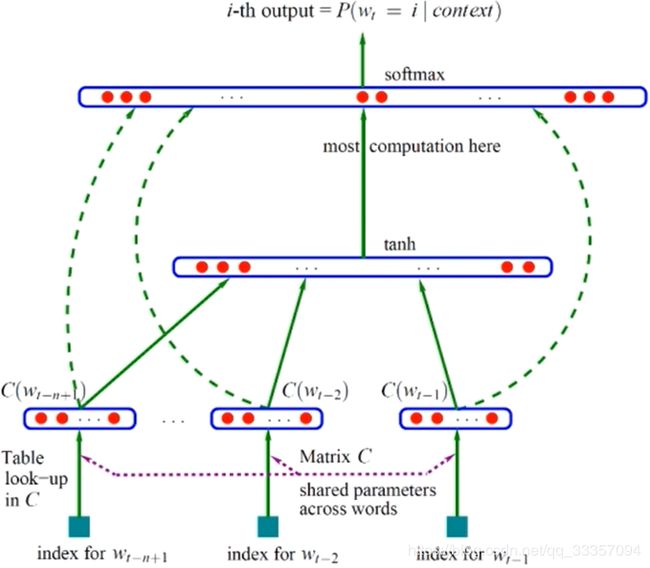
神经语言模型
神经网络语言模型是使用神经网络 来计算统计语言模型
输入层:将 C ( w t − n + 1 , . . . , C ( w t − 1 ) ) C(w_{t-n+1},...,C(w_{t-1})) C(wt−n+1,...,C(wt−1))这n-1个词向量收尾相接拼起来形成一个(n-1)m维的向量x。
隐藏层:输入 o = d + H x o = d+Hx o=d+Hx,d为h维的隐层偏置项,H为h*(n-1)m维的隐层参数:输出 a = t a n h ( o ) a = tanh(o) a=tanh(o)
输出层:用SoftMax做V分类,模型大部分计算都在这一层, y i y_i yi表示下一个词为i的未归一化log概率:
y = b + W x + U t a n h ( d + H x ) y = b+Wx+Utanh(d+Hx) y=b+Wx+Utanh(d+Hx)
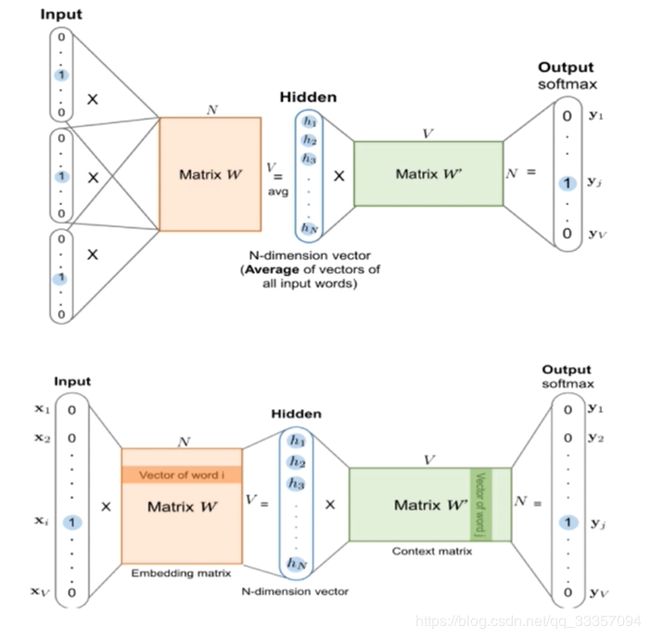
Word2Vec
两种训练方式:我 喜欢 吃 草莓 蛋糕
1.连续词袋模型(Continuous bag of words)
上下文预测中心词
(我,喜欢,吃,草莓,蛋糕) -> 吃
2.跳字模型(skip-gram)
中心词预测上下文
(我,吃),(喜欢,吃),(草莓,吃),(蛋糕,吃)
两种优化方式:
1.Hierarchical Softmax
将N个类别的softmax转化为logN个二分类
2.Negative Sampling
构造K个负样本,变成K+1分类
Glove
一个基于全局词频统计的词表征工具
1.根据语料库构建共现矩阵
2.训练词向量拟合共现概率
J = ∑ i , j = 1 V f ( X i j ) ( w i T w ~ j + b i + b ~ j − log ( X i j ) ) 2 J=\sum_{i, j=1}^{V} f\left(X_{i j}\right)\left(w_{i}^{T} \tilde{w}_{j}+b_{i}+\tilde{b}_{j}-\log \left(X_{i j}\right)\right)^{2} J=i,j=1∑Vf(Xij)(wiTw~j+bi+b~j−log(Xij))2
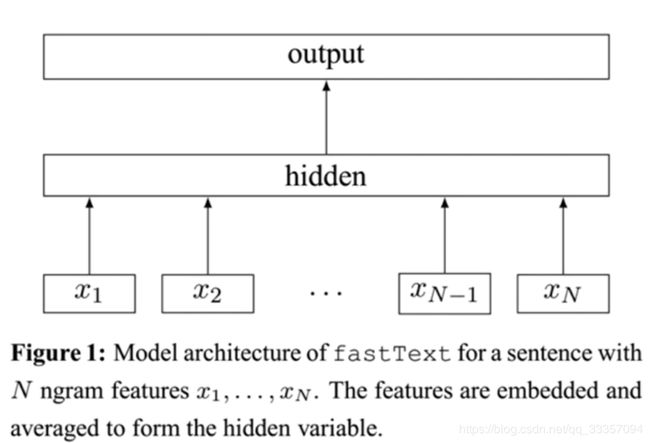
FastText
将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做Hierarchical Softmax多分类。
1.字符n-gram解决oov问题
2.分类效果好
# 训练字向量
import os
import re
import json
import codecs
json_data_folder = './json'
corpus_path = 'corpus.txt'
def read_text(path):
with codecs.open(path,'r',encoding='utf-8') as f :
text = f.read()
return text
def preprocess_text(text):
text = text.lower() #转为小写
text = re.sub('[^a-z^0-9^\u4e00-\u9fa5]','',text) #去除标点符号 只训练中英文字符
text = re.sub('[0-9]','0',text) # 将所有数字都转换为0
return text
total_sentences = []
json_files = [os.path.join(json_data_folder,file) for file in os.listdir(json_data_folder)]
for json_file in json_files:
json_text = read_text(json_file)
contexts = json.loads(json_text)
for context in contexts:
text = preprocess_text(context['text'])
sentence = ' '.join(text)
total_sentences.append(sentence)
print(len(total_sentences,),total_sentences[0])
with codecs.open(corpus_path,'w',encoding='utf-8') as f :
f.write('\n'.join(total_sentences))
from gensim.models.word2vec import Word2Vec
with codecs.open(corpus_path,'r',encoding='utf-8') as f:
sentence = [line.split(' ') for line in f.read().split('\n')]
print(sentence[0])
model = Word2Vec(
sentence,
sg=1,
size=100,
window=5,
min_count=1,
workers=10,
iter= 300
)
# 探索词向量
# 语义相近 距离相近
for word in ['头','痛','剂','病','好']:
result = model.wv.most_similar(word)
print(word)
print(result)
# 保存词向量
embedding_path = './w2v/sg_ns_100.txt'
model.wv.save_word2vec_format(embedding_path,binary=False)