Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
Peiliang Li、Tong Qin、沈劭劼
香港科技大学
摘要
我们提出一种基于立体相机的方法来追踪复杂自动驾驶环境中相机的运动和3D语义对象。取代了直接还原3D立体轮廓的端到端方法,我们提出使用简易标记的2D检测和离散视点分类与一个轻量级的语义推断方法一同去获得粗略的3D对象测量值。基于在复杂环境中鲁棒的半自动对象感知相机姿态追踪,结合我们新的动态对象集束调整方法去融合时间稀疏对应特征和3D语义测量方法,我们获得3D物体姿态,速度、动态点云估计和推断准确性和时间一致性。我们提出的方法在不同的场景中表现。与最先进的解决方案比较了自我运动估计和物体定位。
关键字:语义SLAM、3D物体定位、视觉里程计
1 介绍
定位运动对象和估计3D空间中相机运动是自动驾驶的关键任务。目前,这些目标都分别通过端到端3D对象检测方法和传统的视觉SLAM方法来探索。然而,很难直接在自动驾驶场景中使用这些方法。对于3D对象检测存在两个主要的问题:1、端到端的3D回归方法需要很多训练数据并且需要很大的工作量去精确的标记三维空间中所有对象3D盒子。2、例如3D检测产生与帧无关的结果,在连续感知的自动驾驶中的一致性会不够。为了克服这两个问题,我们提出了一个轻量级的仅以依赖2D物体检测和离散的观测点分类的语义3D盒子推断方法。相比于直接3D回归,2D检测和分类任务很容易去训练,并且训练数据可以很容易仅用2D图像去标记。然而,提出的3D盒子推断仍然与帧无关并且以实例2D检测精度为条件。另一方面,众所周知的SLAM方法由于精确的几何特征约束可以准确的追踪相机运动。受此启发,我们可以相似的利用稀疏特征关联对物体相关运动约束去增强时间一致性。但是,实例物体位姿不能没有语义先验单纯的从特征测量中获得。出于这个目的,由于语义和特征信息的互补性,我们集成我们的实例语义推断模型和时间特征相关性到一个紧耦合的优化框架,这样可以连续追踪3D对象并且用实例准确性和时间一致性来恢复动态稀疏点云。受益于对象范围感知属性,我们的系统可以鲁棒的估计相机位姿而不受动态物体的影响。多亏时间几何一致性,我们可以连续的追踪对象即使是在极端截断的情况下,就是在对象位姿很难进行实例推断。此外,我们使用运动学模型去检测车辆确保方向一致性和运动估计;对于特征观测较少的远距离车辆,也起到了很好的平滑作用。只依赖于一种成熟的2D检测和物体分类网络,我们的系统在鲁棒自身运动估计和多种场景下3D对象追踪有很好的表现能力。主要的贡献总结如下。
- 一个轻量级的只使用2D对象检测和推荐的观测点分类的3D盒推断方法,这样为目标特征提取提供了目标再投影轮廓和遮挡掩模。它也是后续优化的语义度量模型。
- 一种新的动态对象束调整方法,它将语义和特征度量紧密地结合在一起,连续跟踪实例对象状态精确性和时态一致性。
- 对不同的场景进行演示,以显示所建议的系统的实用性。
2 相关工作
本文综述了基于语义SLAM和基于学习图像的三维物体检测的相关工作。
语义SLAM
随着二维目标检测技术的发展,一些与语义理解有关的联合SLAM出现了,我们从三个方面来讨论。第一个是语义辅助定位:重点在于通过将仅为一维的目标度量大小纳入估计框架来纠正单目视觉里程计的的全局尺度。在这两个工作中,分别进行了室内小物体和室外实验。提出了一种对象数据关联方法,当重新观察以前的物体时在概率公式中显示了它的漂移校正能力。然而,通过将二维包围框视为点进行训练它忽略了目标的方向。在参考文献[10]中,作者通过计算一个永久矩阵仅从先验语义图中的对象观察来处理定位任务。第二种是SLAM辅助目标检测和重建。开发二维物体识别系统,在摄像机定位的帮助下,它对视点的变化具有很强的鲁棒性。而参考文献[12]则使用视觉惯性测量进行置信度增长的3d对象检测。参考文献[13,14]分别用单目和RGBD SLAM融合点云重建稠密的三维物体表面。最后,第三类是对相机和物体姿态的联合估计:用预编译的二进制词袋,定位数据集中的对象,并循环修正地图尺度。在参考文献[16,17]中,作者提出了一种语义SfM方法,同时考虑到相机、物体和场景组成的联合估计。然而,这些方法都没有展现出解决动态对象影响的能力,更没有充分利用二维边界框数据(中心、宽度和高度)和三维物体尺寸。也有一些现有的工作[18,19,20,21]建立稠密地图,并用语义标签分割。这些工作超出了本文的范围,因此我们将不进行详细讨论。
3D物体检测
通过深度学习的方法从图像中推断出物体的姿态,为三维物体的定位提供了一种替代的方法。参考文献[22,23]使用这个先验模型去解释3D对象位姿,其中分别采用稠密形状和线框模型。在参考文献[24]中,使用体素模型来检测具有可见特殊模型的对象三维姿态。类似于文献[6]中2D对象检测提出的方法,参考文献[1]提出利用从立体图像中计算出的深度信息生成3D模型,参考文献[2]利用地面假设和附加的分割特征生成三维候选;然后使用r-cnn进行候选评分和目标识别。这种提出的用于生成或模型拟合的高维特征对于训练和使用的计算都很复杂。取代直接生成3D包围盒的方法,参考文献[25]在不同的阶段复原对象方向和尺寸;然后2D-3D包围盒几何约束被用来计算3D对象位姿,在对象截断的情况下其表现受限于完全的依赖于2D包围框实例。
在本文中,我们研究了现有工作的优缺点,并提出了一种完整的自主驾驶感知解决方案,通过充分利用实例语义先验和精确特征时空关联来实现对相机和静态或动态对象在不同环境中的鲁棒和连续状态估计。
3 概览
我们的语义跟踪系统有三个主要模块,如图2所示。第一个模块执行2D对象检测和视点分类,根据2D包围框和3D包围盒顶点之间的约束,粗略地推断出物体所处的位置。第二个模块是特征提取与匹配,它将所有推断的3D包围盒投影到2D图像中,以获得目标轮廓和遮挡。然后引导特征匹配得到立体图像和时态图像的鲁棒特征关联。在第三个模块中我们整合了所有的语义信息、特征测量值到一个紧耦合的优化方法中。此外还将运动学模型应用于汽车以获得一致的运动估计。
4 观测点分类与3D包围盒推导
我们的语义测量包括2D对象包围框盒和观测点分类。在此基础上,可以大致实时推导出对象的近似位姿。
4.1 观测点分类
2D目标检测可以通过最先进的对象检测器来实现,如Faster R-cnn、yolo等。我们在系统中使用Faster R-cnn,因为它在小物体上表现良好。由于实时性要求,只使用左图像进行目标检测。网络架构如图2(a)所示。不像参考文献[6]中最初知识单纯的做对象分类,我们在最后的FC层中添加了子类别分类来表示对象的水平和垂直离散观测点。如图3(a)所示,我们将连续目标观测角划分为八个水平和两个垂直的观测点。共有16个水平和垂直视点分类组合,我们基于3D包围盒的重投影将与2D包围框紧密配合的假设,可以生成2D包围框中的边缘和3D包围盒顶点之间的关联。这些关联为建立四边-顶点的约束推导3D包围盒和构建我们的语义测量模型提供了基本条件。
与直接3D还原相比,发展完善的2D检测和分类网络在不同的场景下具有更强的鲁棒性。所提出的观测点分类任务易于训练,并且具有较高的精度,即使对于小的和极端遮挡对象也是如此。
基于观测点的3D包围盒推导
给出了通过在归一化图像平面[Umin,vmin,UMAX,Vmax]中用四边表示的二维包围框和分类观测点,我们目的是通过2D包围框的边和3D包围盒顶点之间的四个约束来推断对象的姿态,这是受到参考文献[25]的启发。一个3D包围盒可以用它的中心位置p=[px,py,pz]T跟与相机帧相关的水平方向θ和先验尺寸d=[dx,dy,dz]T来表示。例如,在图3(b)中表示的这样一个来自图3(a)中的16种观测点组合之一(表示为红色),四个顶点投影到2D边,相应的约束可构造为:
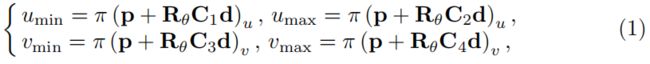
其中π是一个3D投影翘曲函数,定义为π§=[px/pz,py/pz]T,(·)u表示归一化图像平面中的u坐标。我们用Rθ表示由目标帧到相机帧的水平方向θ所表示的旋转参数。C1:4是四个对角线选择矩阵,用来描述对象中心与选定的四个顶点之间的关系,它们在得到分类的观测点点后才能确定。从图3(b)中定义的对象帧可以很容易地看出:

利用这四个方程,可以直观地求解四自由度物体的姿态,并给出先验尺寸。与对所有有效的边缘顶点配置进行彻底测试的参考文献[25]形成鲜明对比,这个求解过程的时间非常短。
我们将复杂的三维目标检测问题转化为二维检测问题,观测点分类,和直接封闭形式的计算。不可否认,求解的姿态是一种近似估计,它取决于2D包围框的实例“紧性”和对象的先验尺寸。同样对于一些顶视图的情况,3D包围盒的重投影并不完全适合2D包围框,这可以从图3(b)的顶部边缘观察到。然而,对于自动驾驶场景中几乎平行或俯视的视点来说,这个假设是合理的。需要注意我们的实例位姿推断仅用于生成对象投影轮廓和遮挡标记用于特征提取并作为最大后验(Map)估计的初始值。其中基于滑动窗口的特征相关和目标点云对齐将进一步优化3D目标轨迹。
5特征提取与匹配
我们将推导出的3D对象包围盒 投影到立体图像上来生成一个有效的轮廓。如图2(b)所示,我们使用不同的颜色标记来表示每个对象的可见部分(灰色背景)。对于遮挡对象,我们根据物体的2D重叠和3D深度关系,将被遮挡部分标记为不可见。对于小于四个有效边缘的截断对象,不能通过Sec.
4.2中的方法来推断,我们直接将左侧图像中检测到的2D包围框投影到右侧图像。我们在可见区域内为每个对象和背景同时提取左、右图像的ORB特征。
立体匹配通过极线搜索来实现。对象特征的深度范围是从推断的对象姿态中知道的,所以我们将搜索区域限制在一个较小的范围内,以实现鲁棒的特征匹配。对于时间匹配,我们首先通过2D包围框相似性评分投票将连续帧中的对象关联起来。在对摄像机旋转进行修正后,根据连续图像之间二维包围框的中心距离和形状相似度对相似度进行加权。如果该对象与前一帧中的所有对象的最大相似度分数小于一个阈值,则该对象被视为丢失。我们注意到有一些更复杂的关联方案,例如参考文献[9]中的概率数据关联,但是它相比于高度动态和无重复的自动驾驶场景,更适合于静态对象场景避免在重新访问时的决策困难。紧接着我们将相关对象和背景的ORB特性与上一帧匹配。极端值通过RANSAC和对每个目标和背景分别进行局部基本矩阵测试舍去。
6 自身运动和对象跟踪
从符号定义开始,我们用![]() 表示在时间t时第k个对象的语义测量,
表示在时间t时第k个对象的语义测量,![]()
![]()
是2D包围框的左上角和右下坐标的测量值,
![]()
是对象的类别标签
![]()
是在Sec. 4.2中定义的四个选择矩阵。对于固定在一个物体或背景上的稀疏特征的测量,我们使用![]()
表示在第k个对象上t时间处的第n次特征的立体观测值(K=0表示静态背景),![]()
分别是在归一化左右图像平面上的特征坐标。相机和第k个物体的状态分别表示为![]()
![]()
![]()
在这里使用
![]()
![]()
和
![]()
去表示世界、相机和对象帧。
![]()
表示世界帧中的位置。对于物体方位我们只对水平旋转![]() 建模而不是
建模而不是
![]()
旋转
![]()
相机自身。
![]()
是第k个对象的时间不变尺寸
![]()
是速度和转向角只用于车辆估计。
为一目了然,我们在图4中展示在时间t的测量和状态。
考虑一般的自动驾驶场景,我们的目标是连续估计车载相机从时间0到T
![]()
并跟踪3D对象的
![]() :
:
![]()
![]()
并恢复动态稀疏特征的3D位置:![]()
![]()
![]()
(这里使用![]()
表示第k个对象帧,其中的特征是相对静态的,K=0表示世界背景,其中特征是全局静态的)
给定语义测量值:![]()
![]()
![]()
和第k个物体上的稀疏特征观测:
![]()
![]()
![]()
![]()
我们将语义对象和摄像机自我运动跟踪从概率模型转化为一个非线性优化问题。
6.1 自身运动追踪
在静态背景特征观测的情况下,可以通过最大似然估计(MLE)来求解自我运动:
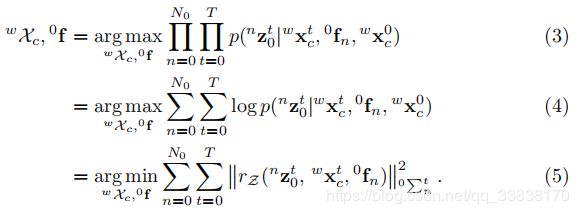
这是典型的SLAM或SfM方法。在第一状态下有条件地估计相机姿态和背景点云。如Eq.3所示测量残差的对数概率与其mahalanobis范数成正比
![]()
然后将MLE问题转化为一个非线性最小二乘问题,这个过程也被称为集束调整(BA)。
6.2 语义物体追踪
在求解相机机位姿后,基于先验尺寸和实例语义测量,可以求解每个时刻t的对象状态。我们假设物体是一个刚体,这意味着其中存在的特征是固定在对象帧上的。因此,如果有连续的对象特征观测,则对象的时间状态是有关联的。给定相机的姿态,不同物体的状态是条件独立的,这样我们就可以并行和独立地跟踪所有的物体。对于第k个对象,我们对于每个类别标签有尺寸先验分布![]() 我们假设每个对象在每一时刻的检测结果和特征测量是独立且高斯分布的,根据贝叶斯准则,我们有以下的最大后验(MAP)估计:
我们假设每个对象在每一时刻的检测结果和特征测量是独立且高斯分布的,根据贝叶斯准则,我们有以下的最大后验(MAP)估计: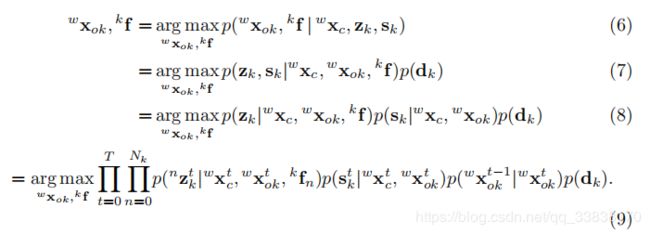
类似于Eq.3,我们将映射转化为一个非线性优化问题: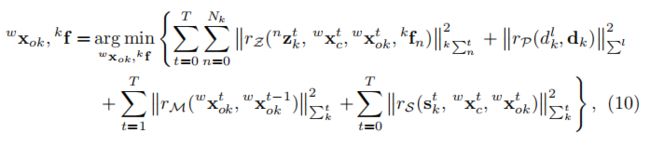
其中,我们使用rz、rp、rm和rs分别表示特征重投影、先验尺寸、对象运动模型和语义包围盒重新投影的残差。![]() 是每次测量对应的协方差矩阵。我们将3D对象追踪问题转化为一种动态对象BA方法,充分利用了目标的尺寸和运动的先验性,增强了时间一致性。最大后验估计可以通过最小化所有残差的Mahalanobis范数之和来实现。
是每次测量对应的协方差矩阵。我们将3D对象追踪问题转化为一种动态对象BA方法,充分利用了目标的尺寸和运动的先验性,增强了时间一致性。最大后验估计可以通过最小化所有残差的Mahalanobis范数之和来实现。
稀疏特征观测
我们将静态特征与相机位姿之间的射影几何扩展为动态特征和对象位姿。基于与目标帧相关的锚定相对静态特征,通过因子图可以将具有相同特征观测的物体姿态联系起来。对于每个特征观测,残差可以用预测的特征位置的重投影误差和左右图像上的实际特征观测来表示: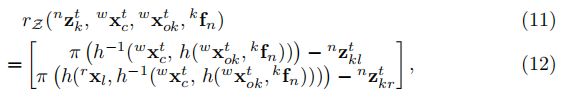 其中,我们使用h(x,p)来表示将3D刚体变换x变换到一个点p。例如
其中,我们使用h(x,p)来表示将3D刚体变换x变换到一个点p。例如![]() 将第n个特征点
将第n个特征点![]() 从对象帧转换为世界帧,
从对象帧转换为世界帧,![]() 是对应的逆变换。
是对应的逆变换。![]() 表示离线标定的立体相机的外部变换。
表示离线标定的立体相机的外部变换。
语义3D物体测量
受益于观测点的类别,我们可以了解2D包围框的边缘与3D包围盒的顶点之间的关系。假设2D包围框紧贴在物体边界上,每个边缘与一个重新投影的3D顶点相交。这些关系可以被确定为每个2D边的四个选择矩阵。语义残差可以用预测的具有检测到的2D包围框边缘和3D包围盒顶点的重投影误差来表示: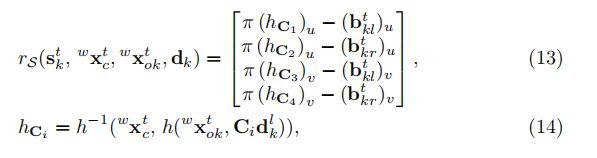
其中我们使用![]() 将由3D包围盒的相应选择矩阵
将由3D包围盒的相应选择矩阵![]() 指定的顶点投影到相机平面上。这个因素立即建立了物体姿态与其尺寸之间的联系。注意由于实时性的要求,我们只对左边的图像执行2D检测。
指定的顶点投影到相机平面上。这个因素立即建立了物体姿态与其尺寸之间的联系。注意由于实时性的要求,我们只对左边的图像执行2D检测。
车辆运动模型
为了实现车辆类别的运动和方向一致性估计,我们使用参考文献[28]中引入的运动学模型。时间t的车辆状态可以用t−1的状态来预测: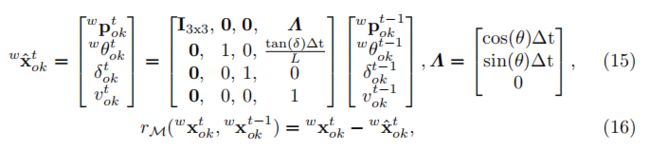
其中L是轴距的长度,它可以被尺寸参数化。车辆的的方向总是与运动方向平行的。为获得更多内容我们请读者阅读参考文献[28]。通过这种为自主驾驶和路径规划提供了丰富的信息运动学模型,我们可以连续地跟踪车辆的速度和方向。对于行人等其他类别,我们直接使用一个简单的恒速模型来提高平滑度。
点云对齐
在最小化所有残差后,我们得到了基于尺寸先验的目标位姿的最大后验估计。然而,由于对象的尺寸不同所估计的位姿可能会存在偏差。因此我们将3D包围盒对齐到恢复的点云,因为精确的立体外部校准,这是没有偏差的。我们最小化所有3D点到锚定的3D包围盒表面的距离: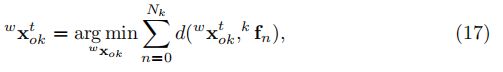
其中![]() 表示第k个特征与其相应的观测表面的距离。在将这些信息紧密融合在一起后,我们得到了对静态和动态目标的一致和准确的位姿估计。
表示第k个特征与其相应的观测表面的距离。在将这些信息紧密融合在一起后,我们得到了对静态和动态目标的一致和准确的位姿估计。