HashMap和ConcurrentMap(JDK1.7)源码解析
HashMap和ConcurrentHashMap它们一直陪伴在我所做的工程里,这次我想把它弄明白让自己更清楚它存在的意义,源码是基于JDK1.7版本。
HashMap
先介绍一下HashMap吧,这是官方JDK对于HashMap的解释。(JDK API链接:https://docs.oracle.com/javase/8/docs/api/)

从官方文档可以看出,HashMap基于HashTable实现的Map接口。HashMap提供了所有Map接口的功能实现,HashMap和HashTable差不多,除了HashMap它不是同步的并且允许为空,也不能保证是有序的。
其实下面还有很多的介绍,介绍了HashMap的优点和不足,比如它相对于HashTable是线程不安全的(hash碰撞、扩容),在不需要多线程的情况下HashMap比HashTable的性能要好,因为不需要同步锁。
下面说一下HashMap的原理吧,先介绍一下它的一些属性。
/**
* The default initial capacity - MUST be a power of two.
* 初始容量是16,必须是2的次方。后面会说为什么要求是2的次方。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 最大容量是2的30次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 默认的负载因子是0.75,我们知道初始容量是16,而负载因子是0.75,当HashMap中的entry大于等于
* 16 * 0.75 = 12时,就需要扩容。
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* An empty table instance to share when the table is not inflated.
* 我们put的(key, value)会转换成一个entry对象,这里就是创建一个空的entry数组。
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
* 扩容的时候会用到它
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* The number of key-value mappings contained in this map.
* 用于记录key-value的数量
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
* @serial
* 这个就是 容量 * 负载因子的值
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
* 用于记录hashMap结构被修改的次数,这里说明的是HashMap使用的是fail-fast迭代器,
* 当在进行迭代的时候,如果有其他线程修改了hashMap的结构比如remove方法,就会抛出
* concurrentModificationException,这是java的检错机制,当有这种情况发生的时候就会
* 停止迭代。
*/
transient int modCount;
/**
* The default threshold of map capacity above which alternative hashing is
* used for String keys. Alternative hashing reduces the incidence of
* collisions due to weak hash code calculation for String keys.
*
* This value may be overridden by defining the system property
* {@code jdk.map.althashing.threshold}. A property value of {@code 1}
* forces alternative hashing to be used at all times whereas
* {@code -1} value ensures that alternative hashing is never used.
*/
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
了解了这些属性,说一下它的数据结构和工作原理。
我们都知道,HashMap是由数组和链表组成的。

我们知道链表插入数据最快的方法就是在头部插入,如果在尾部插入会遍历整个链表。
接下来看一下当我们new HashMap的时候,它的构造方法是怎样的。
//当new HashMap的时候可以指定初始容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
//如果初始容量小于0,就会报异常。这个没啥说的
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//如果传入的初始容量大于最大的容量值,就设置为阈值。也就是2的30次方。
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子必须得大于0.要不就抛异常。isNaN不用搭理它。。。。
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
//new HashMap的时候如果仅指定了初始容量,则会使用默认的负载因子0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//new HashMap的时候什么参数都没有写,则使用默认的容量和负载因子
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
接下来就是最花时间精力的部分了,HashMap的put操作,它到底都做了什么?
---------------看源码-----------------
public V put(K key, V value) {
//如果table是个空的,它就会做初始化,
//这个方法保证了,创建的table容量肯定是2的次方
//逻辑就是 (table.length-1) << 1
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果我们put的是一个null,它会遍历table找有没有entry为null的元素
//如果有的话就替换掉,这么做的目的就是不会有多个null值
if (key == null)
return putForNullKey(value);
//我们传入的key,在这里会计算hash(下面详细介绍)
int hash = hash(key);
//根据计算出的hash来得出应该把元素存在哪个位置
int i = indexFor(hash, table.length);
//根据算出来的索引,来进行遍历,查找这个值之前存在不存在,要是存在的话就把值刷新,把之前的值返回。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//这个上面已经介绍过了
modCount++;
//在这里就是添加操作
addEntry(hash, key, value, i);
return null;
}
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
我们思考一个问题,从put操作来看,它是怎么计算出数组的索引,把entry插入的位置的。
从代码来看有一个hash()和indexFor()方法我们来看一下这两个方法都干了什么,点击查看方法进入源码。
final int hash(Object k) {
//transient int hashSeed = 0;
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
// h = h ^ k.hashCode()
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
// 这么多的异或运算和位运算,是为了让高位也参与运算得出不同的hashcode。
// 异或运算:相同为true,不同为false
// >>>运算:无符号逻辑右移,高位补0
// 详细运算逻辑就不写了。。。。。。
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
我们终于得到了一个与众不同的hashCode,然后进入indexFor()方法
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
h & (length-1)的原因是length是2的次方数,所以不管怎么&(与)运算,得出的结果都是一样的,所以有个减一的操作。
接下来看它的addEntry方法都做了什么。我们只看重点的方法,一个resize方法和transfer方法。
void addEntry(int hash, K key, V value, int bucketIndex) {
//前面说到size是记录元素的数量,threshold是初始容量*负载因子
//如果元素的数量大于threshold了,而且插入的索引位置元素不为空
//那么就会执行resize方法,我们看下面它做了什么
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
//新建一个entry数组用来把之前的table存起来
Entry[] oldTable = table;
//创建一个变量存储之前的table的长度
int oldCapacity = oldTable.length;
//如果之前的容量已经是最大的容量值了,就使用Integer.MAX_VALUE其实也是个数,16进制的一个数。
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建一个新的table,容量是最新的,是之前的容量的两倍。
Entry[] newTable = new Entry[newCapacity];
//然后看这个方法
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
//获取新的容量值
int newCapacity = newTable.length;
//这里的逻辑是遍历之前的table
//然后把元素重新计算hash值和索引插入到新的table里。
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
总结一下:
为什么说HashMap是线程不安全的,hash冲突(碰撞),发生的原因是因为两个key的hash值相同,两个不同的key但是经过hash()方法后hash值相同,另外一个不安全的原因是多线程扩容导致的transfer()死循环。
ConcurrentHashMap
我们知道HashMap和ConcurrentHashMap的区别在于ConcurrentHashMap是线程安全的。
ConcurrentHashMap引入了分段锁(Segment)的概念,它和属性和HashMap差不多只是多了几个属性。
/**
* The default concurrency level for this table, used when not
* otherwise specified in a constructor.
* 默认的并发级别很抽象,举个例子
* 默认的table初始容量是16
* 如果并发级别是16,那么每个entry都有一把锁
* 如果并发级别是8,那么每两个entry公用一把锁
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/**
* The minimum capacity for per-segment tables. Must be a power
* of two, at least two to avoid immediate resizing on next use
* after lazy construction.
* 每个segment容量最小是2,这样是为了避免下次使用调整结构。
*/
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
/**
* The maximum number of segments to allow; used to bound
* constructor arguments. Must be power of two less than 1 << 24.
* segments最大的数量
*/
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
/**
* Number of unsynchronized retries in size and containsValue
* methods before resorting to locking. This is used to avoid
* unbounded retries if tables undergo continuous modification
* which would make it impossible to obtain an accurate result.
*/
static final int RETRIES_BEFORE_LOCK = 2;
接下来我们看一下它的构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//如果小于0就抛异常
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//如果并发级别大于最大的segments数量就设置为segments最大值
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
//这里我们假设concurrentLevel是4
//sshift=3
//ssize=1000
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1; //=>sssize = ssize << 1 左移1位低位补0
}
this.segmentShift = 32 - sshift; // 17
this.segmentMask = ssize - 1; //0111
//这个你懂的~
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize; //0
if (c * ssize < initialCapacity)
++c; // c = 1
int cap = MIN_SEGMENT_TABLE_CAPACITY; 2
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]); //这个HashEntry其实就是HashMap里面的entry只是换了一个名字,也就是说这个s0其实就是entry
//初始化一个segments数组容量为8
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//我们点进去发现是个native方法,是用C语言实现的。
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
这就是一个完整的concurrentHashMap初始化的过程。
接下来看put方法是怎么实现的,为什么说它是线程安全的。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//获取锁,如果没有可用的锁,则while循环直到获取锁位置,线程非阻塞
//reentrantLock 的tryLock方法特性:
//当获取锁的时候,只有当锁资源没有被其他线程持有才可以获取,并返回true
//获取锁的时候,当前线程已经获取锁,并且锁资源可用,返回true
//如果其他资源已经获取锁,没有可以用的锁资源,则返回false,线程此时非阻塞。
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
//旧值
V oldValue;
try {
//新建一个entry数组
HashEntry<K,V>[] tab = table;
//获取索引,不多说上面已经讲过了,道理差不多,但是concurrentHashMap的hash()和
//HashMap有些不同,但是都是为了
//能够防止hash冲突
int index = (tab.length - 1) & hash;
//从类型值和命名来看,是得到一个entry。
HashEntry<K,V> first = entryAt(tab, index);
//在这里开始遍历
for (HashEntry<K,V> e = first;;) {
//entry不为空的话
if (e != null) {
K k;
//如果key值相同的话,更新值
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
//如果onlyIfAbsent为false的话,则替换为新value,否则不修改(一般传false)
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
//entry指向下一个entry
e = e.next;
}
else {
//如果put 的是新值,则进入这里的逻辑
if (node != null)
//把node插在first的前面
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//这个count相当于hashMap里面的size,就是记录元素的个数
//如果大于threshold那么就会扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//其实这个注释已经解释的很清楚了,主要就是因为扩展是按照2的幂次方
//进行扩展的,所以扩展前在同一个桶中的元素,现在要么还是在原来的
//序号的桶里,或者就是原来的序号再加上一个2的幂次方,就这两种选择。
//所以原桶里的元素只有一部分需要移动,其余的都不要移动。该函数为了
//提高效率,就是找到最后一个不在原桶序号的元素,那么连接到该元素后面
//的子链表中的元素的序号都是与找到的这个不在原序号的元素的序号是一样的
//那么就只需要把最后一个不在原序号的元素移到新桶里,那么后面跟的一串
//子元素自然也就连接上了,而且序号还是相同的。在找到的最后一个不在
//原桶序号的元素之前的元素就需要逐个的去遍历,加到和原桶序号相同的新桶上
//或者加到偏移2的幂次方的序号的新桶上。这个都是新创建的元素,因为
//只能在表头插入元素。这个原因可以参考
//《探索 ConcurrentHashMap 高并发性的实现机制》中的讲解
//rehash这里,我口才不好就从网上找答案,我觉得这个答案实在是太标准了。。。
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
下面用图来解释一下segment
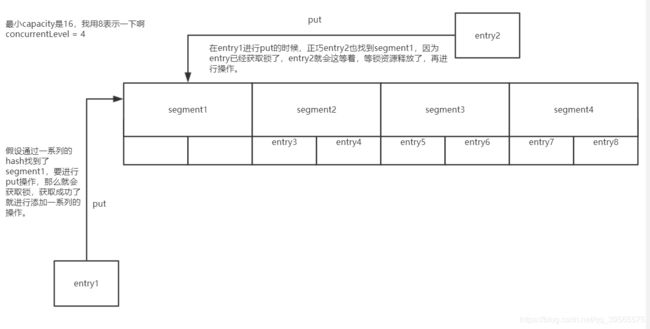
JDK1.8HashMap引入了红黑树等新特性,以后找个时间再总结一版JDK8的。
本博客文章皆出于学习目的,个人总结或摘抄整理自网络。引用参考部分在文章中都有原文链接,如疏忽未给出请联系本人。另外,如文章内容有错误,欢迎各方大神指导交流。