VIO学习总结
VIO(visual-inertial odometry)即视觉惯性里程计,有时也叫视觉惯性系统(VINS,visual-inertial system),是融合相机和IMU数据实现SLAM的算法,根据融合框架的区别又分为紧耦合和松耦合,松耦合中视觉运动估计和惯导运动估计系统是两个独立的模块,将每个模块的输出结果进行融合,而紧耦合则是使用两个传感器的原始数据共同估计一组变量,传感器噪声也是相互影响的,紧耦合算法上比较复杂,但充分利用了传感器数据,可以实现更好的效果,是目前研究的重点。
单目视觉 SLAM 算法存在一些本身框架无法克服的缺陷,首先是尺度的问题 ,单目 SLAM 处理的图像帧丢失了环境的深度信息,即使通过对极约束和三角化恢复了空间路标点的三维信息,但是这个过程的深度恢复的刻度是任意的,并不是实际的物理尺度,导致的结果就是单目SLAM 估计出的运动轨迹即使形状吻合但是尺寸大小却不是实际轨迹尺寸;由于基于视觉特征点进行三角化的精度和帧间位移是有关系的,当相机进行近似旋转运动的时候,三角化算法会退化导致特征点跟踪丢失,同时视觉 SLAM 一般采取第一帧作为世界坐标系,这样估计出的位姿是相对于第一帧图像的位姿,而不是相对于地球水平面 (世界坐标系) 的位姿,后者却是导航中真正需要的位姿,换言之,视觉方法估计的位姿不能和重力方向对齐。

重力向量构建了视觉坐标系和世界坐标系的联系
通过引入 IMU 信息可以很好地解决上述问题,首先通过将 IMU 估计的位姿序列和相机估计的位姿序列对齐可以估计出相机轨迹的真实尺度,而且 IMU 可以很好地预测出图像帧的位姿以及上一时刻特征点在下帧图像的位置,提高特征跟踪算法匹配速度和应对快速旋转的算法鲁棒性,最后 IMU 中加速度计提供的重力向量可以将估计的位置转为实际导航需要的世界坐标系中。同时,智能手机等移动终端对 MEMS 器件和摄像头的大量需求大大降低了两种传感器的价格成本;硬件实现上, MEMS 器件也可以直接嵌入到摄像头电路板上。综合以上,融合 IMU 和视觉信息的 VINS 算法可以很大程度地提高单目 SLAM 算法性能,是一种低成本高性能的导航方案,在机器人、AR/VR 领域得到了很大的关注。
从另外一个角度理解视觉惯性融合的意义,我们一般采用运动方程和测量方程描述机器人的运动过程,具体到视觉惯性紧耦合运动估计问题,这里的第k 时刻的状态 为IMU的运动测量输入, 实现根据上一时刻估计的状态和k-1到k 过程中IMU的运动测量预测的当前时刻状态 ,由于测量噪声的存在,预测状态 和当前真实状态 的差异由噪声项 表示。测量方程中, 为k时刻可以观测到的所有3D路标点集,h在这里对应相机投影模型, 为k 时刻对路标点集 的观测,观测值为 ,观测噪声为 ,即k时刻3D路标点集 在相机图像上的投影点集为 。
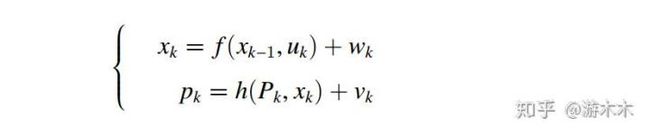
整个机器人的运动过程就是运动方程根据上一时刻状态和当前时刻运动输入 预测当前状态,利用传感器的测量方程作为矫正的过程,在纯视觉SLAM中,因为缺少运动输入,预测方程提供信息不足,我们是直接采用测量方程构建重投影误差进行运动优化估计,而引入IMU数据之后,用IMU作为运动输入 可以对状态进行很好的预测,VIO就是利用了运动预测和测量方程构建联合估计。具体来说,在假设噪声服从高斯分布,对非线性方程进行一阶近似的条件下,从最大后验估计的角度就可以推导出我们在VIO论文中看到的联合优化目标函数:

三、学习资源
3.1 书籍
入门书籍推荐高博的《SLAM十四讲》,这本书不仅涵盖了SLAM和状态估计相关的基本理论知识,而且高博给出了每个理论模块的编程实现,第一遍建议可以先不细推公式,把书浏览一遍了解主要内容,第二遍就可以动手跟着书一点点撸代码了。之后就可以学习目前主流的开源框架,在对SLAM有较深的了解和实践之后,建议读《state estimation for robotics》和《Multi View Geometry》,前者是介绍状态估计理论非常完备的一本书,举例来说,在非线性性非高斯章节中,作者从机器人的运动和测量方程出发,根据马尔科夫假设和贝叶斯公式,将目前主流的滤波(EKF,UKF,PF)方法统一在贝叶斯估计的框架下。后者涵盖了SLAM视觉几何的所有理论知识。
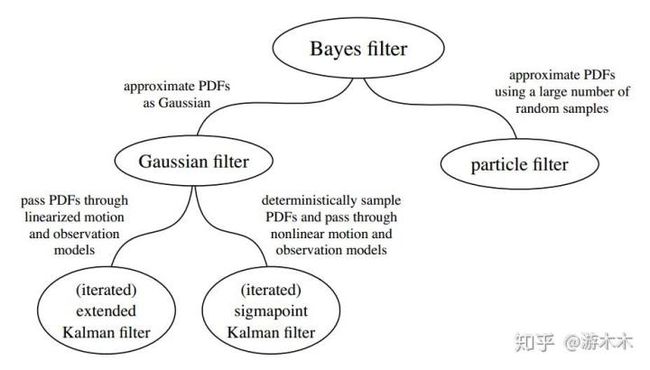
主流滤波方法统一在贝叶斯滤波框架下
对三维旋转的描述计算需要李群李代数的知识,高博的书和《state estimation for robotics》都有详细讲解,简单来说,使用旋转矩阵表示的旋转方便向量的坐标计算,但直接对其优化是有约束优化问题(9个参数3个自由度),解决思路就是在三维旋转群的正切空间上对用李代数表示的旋转误差量进行无约束优化,对正切空间的理解可以参考《Lie groups, Lie algebras, projective geometry and optimization
for 3D Geometry, Engineering and Computer Vision》。
推公式的时候发现矩阵白学了?宝宝不哭,这有一本《the Matrix CookBook》送给你。
3.2 VIO 开源框架
VIO目前实现比较好的有vinsmono,okvis,MSCKF。前两个是基于非线性优化的方案而且框架比较相似,后者是基于滤波优化的方案,也是Google Tango上使用的方法,MSCKF目前并没有开源,不过宾夕法尼亚的Kumar实验室18年有一个相似的工作,目前已经开源。此外还有ROVIO。值得注意的是,虽然在纯视觉SLAM中,学界已经公认基于非线性优化方法的SLAM方法效果要好于滤波的方法,但在VIO中,非线性优化和滤波方法目前还没有很明显的优劣之分。我的理解是结合相机和IMU两种传感器的信息,提供了对当前状态更多的观测,使得算法对历史观测之间约束信息的依赖降低,这也是为什么okvis、vinsmono采用滑动窗口法(global bundle adjustment和filter 的折中)也能取得很好效果的原因。
vinsmono的代码和论文比较一致,是目前大家学习参考比较多的开源框架。
VIO中,目前多采用流形空间上预积分的方法对IMU数据进行预处理,核心思路是在两帧之间计算IMU的帧间运动增量,在迭代优化时直接使用运动增量,提高计算效率。这部分参考论文《On-Manifold Preintegration for Real-Time
Visual-Inertial Odometry》,整篇论文推导的思路是先推导出流形空间上的运动状态的表达公式,然后为了能够整合到最大后验估计的优化框架里,分离出运动表达式中的噪声项,使其近似满足高斯分布,之后推导了在bias变化时的运动估计值的更新方法。
前面有提到VIO用到了以IMU作为控制输入的运动方程,Joan Sola 写的《Quaternion kinematics for the error-state Kalman filter》对以IMU测量值为运动输入的运动方程的误差递进形式进行了详细推导,如果在vinsmono和okvis的运动递进方程的雅克比矩阵推导遇到困难,或者对四元数方法进行运动描述不了解,可以仔细阅读下这篇文章。文章对坐标系的locally和globally的解释也让人印象深刻。
VIO的初始化是系统工作非常关键的部分,这部分可以参考vinsmono以及ORB作者写的的VIO文章《Visual-Inertial Monocular SLAM with Map Reuse》。两篇文章思路比较相似,先是通过单目运动估计的方法获取多帧图像的位姿,然后以此为运动参考估计其他参数,整个过程和相机IMU标定比较相似。初始化主要完成三部分工作:1. 为非线性估计系统提供一个运动初值 2. 估计尺度、IMUbias 3. 估计重力向量在视觉坐标系下的投影向量,以此将视觉坐标系对齐到世界坐标系下。
vinsmono的代码中协方差矩阵递进公式采用的是中值积分的方法,推导思路和Joan Sola文章中的一致,具体推导可以参考https://www.zhihu.com/question/64381223/answer/255818747,此外有篇博客也对vinsmono的整体框架做了整理总结https://blog.csdn.net/u012871872/article/details/78128087。
vonsmono代码中的融合部分是非常值得学习参考的,但是代码中的视觉处理部分多是直接使用OPENCV的函数,而且代码风格是C++/C 混合的。所以推荐看下ORBSLAM的代码,首先编程实现非常规范,对编程学习有很大的参考价值,而且整个代码对opencv的依赖较低,视觉部分的特征提取,视觉运动估计,都是作者自己编程实现的,对理解视觉几何的实现有很好的帮助,泡泡有篇公开课对ORBSLAM的代码进行了梳理(https://pan.baidu.com/s/1c1QOoHM 密码: xfjd)。网上相关的博客也很多。