数字集成电路设计-19-pipeline的写法
引言
之前,我们介绍了数字设计中一些基本组合逻辑的写法(http://blog.csdn.net/rill_zhen/article/details/39586191)以及状态机的写法(http://blog.csdn.net/rill_zhen/article/details/39585367),本小节我们通过一个小实验来熟悉一下pipeline的写法。
在多数的资料和教课书中提到pipeline时,大多只是解释概念,很少介绍其具体RTL实现的,给人一种高达上的感觉。有的资料中会提到具体写法,但大多采用pipe_ready、pipe_hold信号来控制流水线的暂停和继续。
那种写法在流水线较简单时还比较容易,一旦流水线变得复杂,尤其是有些stage还包含子流水线时,pipe_ready/pipe_hold的逻辑就变得很杂乱,以致容易出错。本小节我们介绍另外一种写法,将valid/ready协议和pipeline结合在一起。
关于valid/ready协议,我们之前已经介绍过了,请参考(http://blog.csdn.net/rill_zhen/article/details/44219593)。
将每个stage都解耦合,认为是独立的逻辑单元,所有stage只和自己的上一级和下一级交互,并且采用valid/ready握手协议进一步解耦合。这样设计的pipeline,不仅界限清晰,而且接口简单,耦合度低。便于以后的扩展,debug起来也很容易定位问题。
1,代码清单
下面我们设计一个3级全流水模块,采用上述思路进行编码。
pipeline.v:
/*
* pipeline example
* Rill 2015-05-11
*/
module Mpipeline
(
input clk,
input rst_n,
input en_i,
input [7:0] data_i,
output en_o,
output [7:0] data_o,
output idle
);
wire rdy_pb2pa;
wire vld_pa2pb;
wire [7:0] data_pa2pb;
wire rdy_pc2pb;
wire vld_pb2pc;
wire [7:0] data_pb2pc;
wire rdy_pa;
Mpa pa
(
.clk (clk),
.rst_n (rst_n),
.valid_i (en_i),
.data_i (data_i),
.ready_i (rdy_pb2pa),
.ready_o (rdy_pa),
.valid_o (vld_pa2pb),
.data_o (data_pa2pb)
);
Mpb pb
(
.clk (clk),
.rst_n (rst_n),
.valid_i (vld_pa2pb),
.data_i (data_pa2pb),
.ready_i (rdy_pc2pb),
.ready_o (rdy_pb2pa),
.valid_o (vld_pb2pc),
.data_o (data_pb2pc)
);
Mpc pc
(
.clk (clk),
.rst_n (rst_n),
.valid_i (vld_pb2pc),
.data_i (data_pb2pc),
.ready_i (1'b1),
.ready_o (rdy_pc2pb),
.valid_o (en_o),
.data_o (data_o)
);
assign idle = ~vld_pa2pb & ~vld_pb2pc & ~en_o;
endmodule
module Mpa
(
input clk,
input rst_n,
input valid_i, //from pre-stage
input [7:0] data_i, //from pre-stage
input ready_i, //from post-stage
output ready_o,//to pre-stage
output valid_o, //to post-stage
output [7:0] data_o //to post-stage
);
reg valid_o_r;
reg [7:0] data_o_r;
wire [7:0] calc;
assign calc = data_i + 1'b1;
always @(posedge clk)
if(~rst_n)
valid_o_r <= 1'b0;
else if(valid_i)
valid_o_r <= 1'b1;
else if(~valid_i)
valid_o_r <= 1'b0;
always @(posedge clk)
if(~rst_n)
data_o_r <= 8'b0;
else if(valid_i)
data_o_r <= calc;
assign ready_o = ready_i;
assign valid_o = valid_o_r;
assign data_o = data_o_r;
endmodule
module Mpb
(
input clk,
input rst_n,
input valid_i, //from pre-stage
input [7:0] data_i, //from pre-stage
input ready_i, //from post-stage
output ready_o,//to pre-stage
output valid_o, //to post-stage
output [7:0] data_o //to post-stage
);
reg valid_o_r;
reg [7:0] data_o_r;
wire [7:0] calc;
assign calc = data_i << 1'b1;
always @(posedge clk)
if(~rst_n)
valid_o_r <= 1'b0;
else if(valid_i)
valid_o_r <= 1'b1;
else if(~valid_i)
valid_o_r <= 1'b0;
always @(posedge clk)
if(~rst_n)
data_o_r <= 8'b0;
else if(valid_i)
data_o_r <= calc;
assign ready_o = ready_i;
assign valid_o = valid_o_r;
assign data_o = data_o_r;
endmodule
module Mpc
(
input clk,
input rst_n,
input valid_i, //from pre-stage
input [7:0] data_i, //from pre-stage
input ready_i, //from post-stage
output ready_o,//to pre-stage
output valid_o, //to post-stage
output [7:0] data_o //to post-stage
);
reg valid_o_r;
reg [7:0] data_o_r;
wire [7:0] calc;
assign calc = data_i - 1'b1;
always @(posedge clk)
if(~rst_n)
valid_o_r <= 1'b0;
else if(valid_i)
valid_o_r <= 1'b1;
else if(~valid_i)
valid_o_r <= 1'b0;
always @(posedge clk)
if(~rst_n)
data_o_r <= 8'b0;
else if(valid_i)
data_o_r <= calc;
assign ready_o = ready_i;
assign valid_o = valid_o_r;
assign data_o = data_o_r;
endmoduletb.v:
/*
* pipeline example
* Rill 2015-05-11
*/
module Ttb;
reg clk;
reg rst_n;
reg en_i_r;
reg [7:0] data_i_r;
wire en_o;
wire [7:0] data_o;
wire idle;
Mpipeline pipeline
(
.clk (clk),
.rst_n (rst_n),
.en_i (en_i_r),
.data_i (data_i_r),
.en_o (en_o),
.data_o (data_o),
.idle (idle)
);
initial
begin
clk = 1'b0;
rst_n = 1'b0;
en_i_r = 1'b0;
data_i_r = 8'b0;
fork
forever #5 clk = ~clk;
join_none
repeat(10) @(posedge clk);
rst_n = 1'b1;
repeat(10) @(posedge clk);
@(posedge clk);
en_i_r <= 1'b1;
data_i_r <= 8'h1;
@(posedge clk);
en_i_r <= 1'b1;
data_i_r <= 8'h2;
@(posedge clk);
en_i_r <= 1'b1;
data_i_r <= 8'h3;
@(posedge clk);
en_i_r <= 1'b1;
data_i_r <= 8'h4;
@(posedge clk);
en_i_r <= 1'b0;
data_i_r <= 8'h0;
repeat(10) @(posedge clk);
$finish();
end
endmodule
2,脚本
pp.sh
#! /bin/bash
#
# pp.sh
# usage: ./pp.sh c/w/r
# Rill create 2014-09-03
#
TOP_MODULE=Ttb
export SRC_DIR=$(pwd)
tcl_file=run.tcl
if [ $# != 1 ];then
echo "args must be c/w/r"
exit 0
fi
if [ $1 == "c" ]; then
echo "compile lib..."
ncvlog -f ./vflist -sv -update -LINEDEBUG;
ncelab -delay_mode zero -access +rwc -timescale 1ns/10ps ${TOP_MODULE}
exit 0
fi
if [ -e ${tcl_file} ];then
rm ${tcl_file} -f
fi
touch ${tcl_file}
if [ $1 == "w" ];then
echo "open wave..."
echo "database -open waves -into waves.shm -default;" >> ${tcl_file}
echo "probe -shm -variable -all -depth all;" >> ${tcl_file}
echo "run" >> ${tcl_file}
echo "exit" >> ${tcl_file}
fi
if [ $1 == "w" -o $1 == "r" ];then
echo "sim start..."
ncsim ${TOP_MODULE} -input ${tcl_file}
fi
echo "$(date) sim done!"
vflist:
-incdir ${SRC_DIR}
${SRC_DIR}/pipeline.v
${SRC_DIR}/tb.v
3,仿真结果
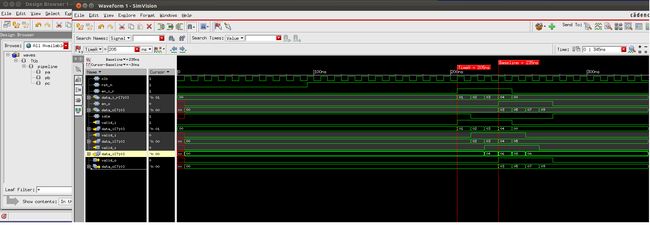
4,扩展
上面是一个全流水pipeline,所以所有stage的valid只要有输入就会拉高,ready信号只要下一stage的ready有效就拉高(能接收新数据)。
在实际的工作中,将calc信号换成组合逻辑云,正确处理valid_o和ready_o,即可。
5,小结
不知道pipeline还有没有更好的写法。