支持向量机通俗导论(理解SVM的三层境界)
作者: July、pluskid ;致谢:白石、 jerrylead支持向量机通俗导论(理解SVM的三层境界)
此文章转自 http://blog.csdn.net/v_july_v/article/details/7624837
出处:结构之法算法之道 blog。
第一层、了解SVM
1.0、什么是支持向量机SVM
1.1.、线性分类
1.1.1、分类标准
1.1.2、1或-1分类标准的起源:logistic回归
1.1.3、形式化标示类
1.2、线性分类的一个例子
1.3、函数间隔Functional margin与几何间隔Geometrical margin
1.3.1、函数间隔Functional margin
1.3.2、点到超平面的距离定义:几何间隔Geometrical margin
1.4、最大间隔分类器Maximum Margin Classifier的定义
1.5、到底什么是Support Vector
第二层、深入SVM
2.1、从线性可分到线性不可分
2.1.1、从原始问题到对偶问题的求解
2.1.2、线性不可分的情况
2.2、核函数Kernel
2.2.1、如何处理非线性数据
2.2.2、特征空间的隐式映射:核函数
2.2.3、几个核函数
2.2.4、核函数的本质
2.3、使用松弛变量处理 outliers 方法
2.4、小结
第三层、证明SVM
3.1、线性学习器
3.1.1、感知机算法
3.1.2、松弛变量
3.2、最小二乘法
3.3、核函数特征空间
3.4、SMO算法
3.5、SVM的应用
3.5.1、文本分类
参考文献及推荐阅读
前言
动笔写这个支持向量机(support vector machine)是费了不少劲和困难的,从5月22日凌晨两点在微博上说我要写了,到此刻真正动笔要写此文,中间竟然隔了近半个月(而后你会发现,我写完此文得花一个半月,修改完善又得再花一个月,故前后加起来至8月底,写这个SVM便要花足足近3个月)。原因很简单,一者这个东西本身就并不好懂,要深入学习和研究下去需花费不少时间和精力,二者这个东西也不好讲清楚,尽管网上已经有朋友已经写得不错了(见文末参考链接),但在描述数学公式的时候还是显得不够。得益于同学白石的数学证明,我还是想尝试写一下,希望本文在兼顾通俗易懂的基础上,真真正正能足以成为一篇完整概括和介绍支持向量机的导论性的文章。
本文作为Top 10 Algorithms in Data Mining系列第二篇文章,将主要结合支持向量机导论、数据挖掘导论及网友Free Mind的支持向量机系列而写(于此,还是一篇学习笔记,只是加入了自己的理解,有任何不妥之处,还望海涵),宏观上整体认识支持向量机的概念和用处,微观上深究部分定理的来龙去脉,证明及原理细节,力求深入浅出 & 通俗易懂。
在本文中,你将看到,理解SVM分三层境界,
- 第一层、了解SVM(你只需要对SVM有个大致的了解,知道它是个什么东西便已足够);
- 第二层、深入SVM(你将跟我一起深入SVM的内部原理,通宵其各处脉络,以为将来运用它时游刃有余);
- 第三层、证明SVM(当你了解了所有的原理之后,你会有大笔一挥,尝试证明它的冲动);
以此逐层深入,从而照顾到水平深浅度不同的读者,在保证浅显直白的基础上尽可能深入,还读者一个较为透彻清晰的SVM。
同时,阅读本文之前,请读者注意以下两点:
- 若读者用
IE6浏览器阅读本文,将有大部分公式无法正常显示(显示一半或者完全无法显示),故若想正常的阅读本文请尽量使用chrome等浏览器,谢谢大家。 - 本文中出现了诸多公式,若想真正理解本文之内容,我希望读者,能拿张纸和笔出来,把本文所有定理.公式都亲自推导一遍或者直接打印下来,在文稿上演算(读本blog的最好办法便是直接把某一篇文章打印下来,随时随地思考.演算.讨论)。
Ok,还是那句原话,有任何问题,欢迎任何人随时不吝指正 & 赐教,感谢。
第一层、了解SVM
1.0、什么是支持向量机SVM
要明白什么是SVM,便得从分类说起。
分类作为数据挖掘领域中一项非常重要的任务,目前在商业上应用最多(比如分析型CRM里面的客户分类模型,客户流失模型,客户盈利等等,其本质上都属于分类问题)。而分类的目的则是学会一个分类函数或分类模型(或者叫做分类器),该模型能吧数据库中的数据项映射到给定类别中的某一个,从而可以用于预测未知类别。
其实,若叫分类,可能会有人产生误解,以为凡是分类就是把一些东西或样例按照类别给区分开来,实际上,分类方法是一个机器学习的方法,分类也成为模式识别,或者在概率统计中称为判别分析问题。
你甚至可以想当然的认为,分类就是恰如一个商场进了一批新的货物,你现在要根据这些货物的特征分门别类的摆放在相关的架子上,这一过程便可以理解为分类,只是它由训练有素的计算机程序来完成。
来举个例子,比如心脏病的确诊中,如果我要完全确诊某人得了心脏病,那么我必须要进行一些高级的手段,或者借助一些昂贵的机器,那么若我们没有那些高科技医疗机器,怎么判断某人是否得了心脏病呢?
当然了,古代中医是通过望、闻、问、切“四诊”,但除了这些,我们在现代医学里还是可以利用一些比较容易获得的临床指标进行推断某人是否得了心脏病。如作为一个医生,他可以根据他以往诊断的病例对很多个病人(假设是500个)进行彻底的临床检测之后,已经能够完全确定了哪些病人具有心脏病,哪些没有。因为,在这个诊断的过程中,医生理所当然的记录了他们的年龄,胆固醇等10多项病人的相关指标。那么,以后,医生可以根据这些临床资料,对后来新来的病人通过检测那10多项年龄、胆固醇等指标,以此就能推断或者判定病人是否有心脏病(虽说这个做法不能达到100%的标准,但也能达到80、90%的正确率),而这一根据以往临场病例指标分析来推断新来的病例的技术,即成为分类classification技术。
假定是否患有心脏病与病人的年龄和胆固醇水平密切相关,下表对应10个病人的临床数据(年龄用[x1]表示,胆固醇水平用[x2]表示):
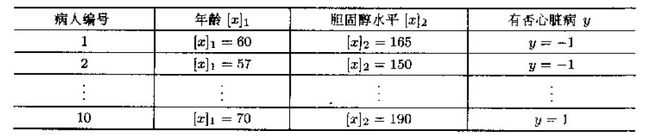
这样,问题就变成了一个在二维空间上的分类问题,可以在平面直角坐标系中描述如下:根据病人的两项指标和有无心脏病,把每个病人用一个样本点来表示,有心脏病者用“+”形点表示,无心脏病者用圆形点,如下图所示:
如此我们很明显的看到,是可以在平面上用一条直线把圆点和“+”分开来的。当然,事实上,还有很多线性不可分的情况,下文将会具体描述。

So,本文将要介绍的支持向量机SVM算法便是一种分类方法。
- 所谓支持向量机,顾名思义,分为两个部分了解,一什么是支持向量(简单来说,就是支持 or 支撑平面上把两类类别划分开来的超平面的向量点,下文将具体解释),二这里的“机”是什么意思。我先来回答第二点:这里的“机(machine,机器)”便是一个算法。在机器学习领域,常把一些算法看做是一个机器,如分类机(当然,也叫做分类器),而支持向量机本身便是一种监督式学习的方法(至于具体什么是监督学习与非监督学习,请参见此系列Machine L&Data Mining第一篇),它广泛的应用于统计分类以及回归分析中。
支持向量机(SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
对于不想深究SVM原理的同学(比如就只想看看SVM是干嘛的),那么,了解到这里便足够了,不需上层。而对于那些喜欢深入研究一个东西的同学,甚至究其本质的,咱们则还有很长的一段路要走,万里长征,咱们开始迈第一步吧(相信你能走完)。
1.1、线性分类
OK,在讲SVM之前,咱们必须先弄清楚一个概念:线性分类器(也可以叫做感知机,这里的机表示的还是一种算法,本文第三部分、证明SVM中会详细阐述)。
1.1.1、分类标准
这里我们考虑的是一个两类的分类问题,数据点用 x 来表示,这是一个 n 维向量,而类别用 y 来表示,可以取 1 或者 -1 ,分别代表两个不同的类。一个线性分类器就是要在 n 维的数据空间中找到一个超平面,其方程可以表示为:
上面给出了线性分类的定义描述,但或许读者没有想过:为何用y取1 或者 -1来表示两个不同的类别呢?其实,这个1或-1的分类标准起源于logistic回归,为了完整和过渡的自然性,咱们就再来看看这个logistic回归。
1.1.2、1或-1分类标准的起源:logistic回归

 的图像是
的图像是


 ,发现
,发现
 只和
只和
 有关,
有关,
 >0,那么
>0,那么
 ,g(z)只不过是用来映射,真实的类别决定权还在
,g(z)只不过是用来映射,真实的类别决定权还在
 。还有当
。还有当
 ,
,
 =1,反之
=1,反之



 。Logistic回归就是要学习得到
。Logistic回归就是要学习得到
 ,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。
,使得正例的特征远大于0,负例的特征远小于0,强调在全部训练实例上达到这个目标。
1.1.3、形式化标示
 替换成w和b。以前的
替换成w和b。以前的
 ,其中认为
,其中认为
 。现在我们替换
。现在我们替换
 为
为
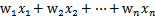
 )。这样,我们让
)。这样,我们让
 ,进一步
,进一步


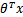 的正负问题,而不用关心g(z),因此我们这里将g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:
的正负问题,而不用关心g(z),因此我们这里将g(z)做一个简化,将其简单映射到y=-1和y=1上。映射关系如下:

1.2、线性分类的一个例子
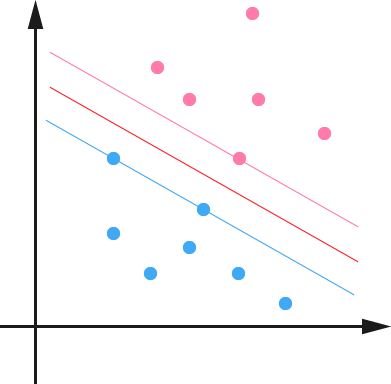
下面举个简单的例子,一个二维平面(一个超平面,在二维空间中的例子就是一条直线),如下图所示,平面上有两种不同的点,分别用两种不同的颜色表示,一种为红颜色的点,另一种则为蓝颜色的点,红颜色的线表示一个可行的超平面。
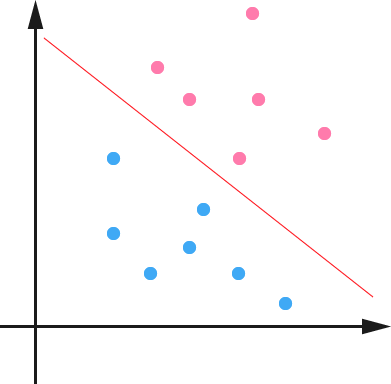
从上图中我们可以看出,这条红颜色的线把红颜色的点和蓝颜色的点分开来了。而这条红颜色的线就是我们上面所说的超平面,也就是说,这个所谓的超平面的的确确便把这两种不同颜色的数据点分隔开来,在超平面一边的数据点所对应的 y 全是 -1 ,而在另一边全是 1 。
接着,我们可以令分类函数(提醒:下文很大篇幅都在讨论着这个分类函数):
f(x)= wTx+b
显然,如果 f(x)=0 ,那么 x 是位于超平面上的点。我们不妨要求对于所有满足 f(x)<0 的点,其对应的 y 等于 -1 ,而 f(x)>0 则对应 y=1 的数据点。
(有一朋友飞狗来自Mare_Desiderii,看了上面的定义之后,问道:请教一下SVM functional margin 为 γˆ=y(wTx+b)=yf(x)中的Y是只取1和-1 吗?y的唯一作用就是确保functional margin的非负性?真是这样的么?当然不是,详情请见本文评论下第43楼)
当然,有些时候(或者说大部分时候)数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在(不过关于如何处理这样的问题我们后面会讲),这里先从最简单的情形开始推导,就假设数据都是线性可分的,亦即这样的超平面是存在的。更进一步,我们在进行分类的时候,将数据点 x 代入 f(x) 中,如果得到的结果小于 0 ,则赋予其类别 -1 ,如果大于 0 则赋予类别 1 。如果 f(x)=0 ,则很难办了,分到哪一类都不是。
请读者注意,下面的篇幅将按下述3点走:
- 咱们就要确定上述分类函数f(x) = w.x + b(w.x表示w与x的内积)中的两个参数w和b,通俗理解的话w是法向量,b是截距;
- 那如何确定w和b呢?答案是寻找两条边界端或极端划分直线中间的最大间隔(之所以要寻最大间隔是为了能更好的划分不同类的点,下文你将看到:为寻最大间隔,导出1/2||w||^2,继而引入拉格朗日函数和对偶变量a,化为对单一因数对偶变量a的求解,当然,这是后话);
- 进而把寻求分类函数f(x) = w.x + b的问题转化为对w,b的最优化问题。
总结成一句话即是:从最大间隔出发(目的本就是为了确定法向量w),转化为求对变量w和b的凸二次规划问题。亦或如下图所示(有点需要注意,如读者@酱爆小八爪所说:从最大分类间隔开始,就一直是凸优化问题):

1.3、函数间隔Functional margin与几何间隔Geometrical margin
一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。在超平面w*x+b=0确定的情况下,|w*x+b|能够相对的表示点x到距离超平面的远近,而w*x+b的符号与类标记y的符号是否一致表示分类是否正确,所以,可以用量y*(w*x+b)的正负性来判定或表示分类的正确性和确信度,于此,我们便引出了函数间隔functional margin的概念。
1.3.1、函数间隔Functional margin
我们定义函数间隔functional margin 为:
γˆ=y(wTx+b)=yf(x)
接着,我们定义超平面(w,b)关于训练数据集T的函数间隔为超平面(w,b)关于T中所有样本点(xi,yi)的函数间隔最小值,其中,x是特征,y是结果标签,i表示第i个样本,有:
γˆ=minγˆi (i=1,...n)
然与此同时,问题就出来了。上述定义的函数间隔虽然可以表示分类预测的正确性和确信度,但在选择分类超平面时,只有函数间隔还远远不够,因为如果成比例的改变w和b,如将他们改变为2w和2b,虽然此时超平面没有改变,但函数间隔的值f(x)却变成了原来的4倍。其实,我们可以对法向量w加些约束条件,使其表面上看起来规范化,如此,我们很快又将引出真正定义点到超平面的距离--几何间隔geometrical margin的概念。
1.3.2、点到超平面的距离定义:几何间隔Geometrical margin

在给出几何间隔的定义之前,咱们首先来看下,如上图所示,对于一个点 x ,令其垂直投影到超平面上的对应的为 x0 ,由于 w 是垂直于超平面的一个向量,我们有
(||w||表示的是范数,关于范数的概念参见:http://baike.baidu.com/view/637132.htm)
又由于 x0 是超平面上的点,满足 f(x0)=0 ,代入超平面的方程即可算出: γ
(有的书上会写成把||w|| 分开相除的形式,如本文参考文献及推荐阅读条目9,其中,||w||为w的二阶泛数)
不过,这里的 γ 是带符号的,我们需要的只是它的绝对值,因此类似地,也乘上对应的类别 y 即可,因此实际上我们定义 几何间隔geometrical margin 为(注:别忘了,上面ˆγ的定义,ˆγ=y(wTx+b)=yf(x)):
(代人相关式子可以得出:yi*(w/||w|| + b/||w||))
正如本文评论下读者popol1991留言:函数间隔y*(wx+b)=y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量;而几何间隔|f(x)|/||w||才是直观上的点到超平面距离。
想想二维空间里的点到直线公式:假设一条直线的方程为ax+by+c=0,点P的坐标是(x0,y0),则点到直线距离为|ax0+by0+c|/sqrt(a^2+b^2)。如下图所示:
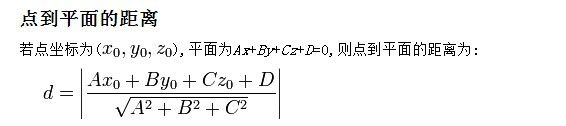
那么如果用向量表示,设w=(a,b),f(x)=wx+c,那么这个距离正是|f(p)|/||w||。
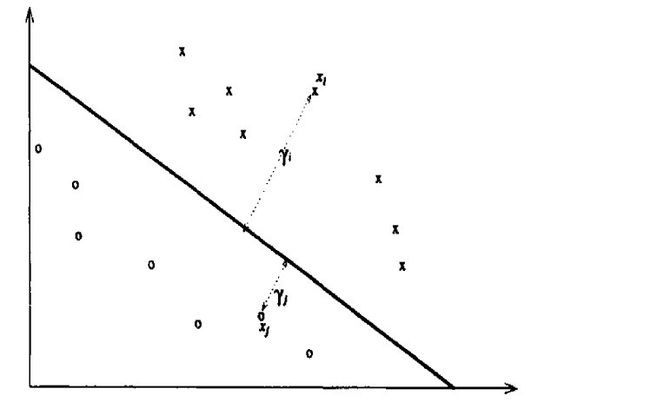
OK,下图中xi,和xj分别到超平面的距离:
1.4、最大间隔分类器Maximum Margin Classifier的定义
于此,我们已经很明显的看出,函数间隔functional margin 和 几何间隔geometrical margin 相差一个 ∥w∥ 的缩放因子。按照我们前面的分析,对一个数据点进行分类,当它的 margin 越大的时候,分类的 confidence 越大。对于一个包含 n 个点的数据集,我们可以很自然地定义它的 margin 为所有这 n 个点的 margin 值中最小的那个。于是,为了使得分类的 confidence 高,我们希望所选择的超平面hyper plane 能够最大化这个 margin 值。
通过上节,我们已经知道:
1、functional margin 明显是不太适合用来最大化的一个量,因为在 hyper plane 固定以后,我们可以等比例地缩放 w 的长度和 b 的值,这样可以使得 f(x)=wTx+b 的值任意大,亦即 functional margin γˆ 可以在 hyper plane 保持不变的情况下被取得任意大,
2、而 geometrical margin 则没有这个问题,因为除上了 ∥w∥ 这个分母,所以缩放 w 和 b 的时候 γ˜ 的值是不会改变的,它只随着 hyper plane 的变动而变动,因此,这是更加合适的一个 margin 。
这样一来,我们的 maximum margin classifier 的目标函数可以定义为:
当然,还需要满足一些条件,根据 margin 的定义,我们有

其中 γˆ=γ˜∥w∥ (等价于 ˜γ = ˆγ / ∥w∥,故有稍后的 γˆ =1 时, ˜γ = 1 / ||w||),处于方便推导和优化的目的,我们可以令 γˆ=1 (对目标函数的优化没有影响,至于为什么,请见本文评论下第42楼回复,貌似博客系统故障,原来评论在第42楼的回复现在第42+81楼,即第123楼显示) ,此时,上述的目标函数 ˜γ转化为(其中,s.t.,即subject to的意思,它导出的是约束条件):

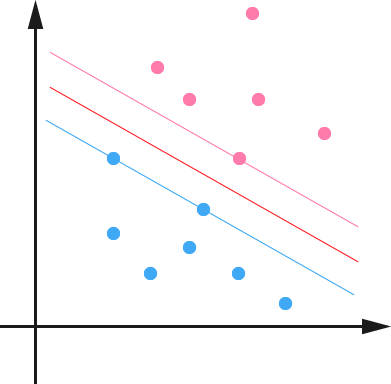
通过求解这个问题,我们就可以找到一个 margin 最大的 classifier ,如下图所示,中间的红色线条是 Optimal Hyper Plane ,另外两条线到红线的距离都是等于
γ˜ 的( γ˜ 便是上文所定义的geometrical margin,当令 γˆ=1 时, γ˜ 便为1/||w||,而我们上面得到的目标函数便是在相应的约束条件下,要最大化这个1/||w||值):
通过最大化 margin ,我们使得该分类器对数据进行分类时具有了最大的 confidence 。但,这个最大分类间隔器到底是用来干嘛的呢?很简单,SVM 通过使用最大分类间隙Maximum Margin Classifier 来设计决策最优分类超平面,而为何是最大间隔,却不是最小间隔呢?因为最大间隔能获得最大稳定性与区分的确信度,从而得到良好的推广能力(超平面之间的距离越大,分离器的推广能力越好,也就是预测精度越高,不过对于训练数据的误差不一定是最小的.2012.08.21updated)。
So,对于什么是Support Vector Machine ,我们可以先这样理解,如上图所示,我们可以看到 hyper plane 两边的那个 gap 分别对应的两条平行的线(在高维空间中也应该是两个 hyper plane)上有一些点,显然两个超平面hyper plane 上都会有点存在,否则我们就可以进一步扩大 gap ,也就是增大 γ˜ 的值了。这些点,就叫做 support vector。下文1.5节将更为具体描述。
1.5、到底什么是Support Vector
上节,我们介绍了Maximum Margin Classifier,但并没有具体阐述到底什么是Support Vector,本节,咱们来重点阐述这个概念。咱们不妨先来回忆一下上节1.4节最后一张图:
可以看到两个支撑着中间的 gap 的超平面,它们到中间的纯红线separating hyper plane 的距离相等,即我们所能得到的最大的 geometrical margin γ˜ 。而“支撑”这两个超平面的必定会有一些点,而这些“支撑”的点便叫做支持向量Support Vector。
很显然,由于这些 supporting vector 刚好在边界上,所以它们是满足 y(wTx+b)=1 (还记得我们把 functional margin 定为 1 了吗?上节中:“处于方便推导和优化的目的,我们可以令 γˆ=1 ”),而对于所有不是支持向量的点,也就是在“阵地后方”的点,则显然有 y(wTx+b)>1 。当然,通常除了 K-Nearest Neighbor 之类的 Memory-based Learning 算法,通常算法也都不会直接把所有的点记忆下来,并全部用来做后续 inference 中的计算。不过,如果算法使用了 Kernel 方法进行非线性化推广的话,就会遇到这个问题了。Kernel 方法在下文第二部分2.2节中介绍)。
OK,到此为止,算是了解到了SVM的第一层,对于那些只关心怎么用SVM的朋友便已足够,不必再更进一层深究其更深的原理。
第二层、深入SVM
2.1、从线性可分到线性不可分
2.1.1、从原始问题到对偶问题的求解
当然,除了在上文中所介绍的从几何直观上之外,支持向量的概念也可以从其优化过程的推导中得到。虽然上文1.4节给出了目标函数,却没有讲怎么来求解。现在就让我们来处理这个问题。回忆一下之前得到的目标函数(subject to导出的则是约束条件):

 的最大值相当于求
的最大值相当于求
 的最小值,所以上述问题等价于(w由分母变成分子,从而也有原来的max问题变为min问题,很明显,两者问题等价):
的最小值,所以上述问题等价于(w由分母变成分子,从而也有原来的max问题变为min问题,很明显,两者问题等价):

- 到这个形式以后,就可以很明显地看出来,它是一个凸优化问题,或者更具体地说,它是一个二次优化问题——目标函数是二次的,约束条件是线性的。这个问题可以用任何现成的 QP (Quadratic Programming) 的优化包进行求解;
- 虽然这个问题确实是一个标准的 QP 问题,但是它也有它的特殊结构,通过 Lagrange Duality 变换到对偶变量 (dual variable) 的优化问题之后,可以找到一种更加有效的方法来进行求解,而且通常情况下这种方法比直接使用通用的 QP 优化包进行优化要高效得多。
也就说,除了用解决QP问题的常规方法之外,还可以应用拉格朗日对偶性,通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。
ok,接下来,你将看到“对偶变量dual variable的优化问题”等类似的关键词频繁出现,便是解决此凸优化问题的第二种更为高效的解--对偶变量的优化求解。
至于上述提到,关于什么是Lagrange duality?简单地来说,通过给每一个约束条件加上一个 Lagrange multiplier(拉格朗日乘值),即引入拉格朗日对偶变量α,如此我们便可以通过拉格朗日函数将约束条件融和到目标函数里去(也就是说把条件融合到一个函数里头,现在只用一个函数表达式便能清楚的表达出我们的问题):
然后我们令

容易验证,当某个约束条件不满足时,例如 yi(wTxi+b)<1 ,那么我们显然有 θ(w)=∞ (只要令 αi=∞ 即可)。而当所有约束条件都满足时,则有 θ(w)=12∥w∥2 , 亦即我们最初要最小化的量。因此,在要求约束条件得到满足的情况下最小化 12∥w∥2 实际上等价于直接最小化 θ(w) (当然,这里也有约束条件,就是 αi≥0,i=1,…,n ) ,因为如果约束条件没有得到满足, θ(w) 会等于无穷大,自然不会是我们所要求的最小值。具体写出来,我们现在的目标函数变成了:

这里用 p∗ 表示这个问题的最优值,这个问题和我们最初的问题是等价的。不过,现在我们来把最小和最大的位置交换一下(稍后,你将看到,当下面式子满足了一定的条件之后,这个式子d 便是上式P 的对偶形式表示):

当然,交换以后的问题不再等价于原问题,这个新问题的最优值用 d∗ 来表示。并,我们有 d∗≤p∗ ,这在直观上也不难理解,最大值中最小的一个总也比最小值中最大的一个要大吧! 总之,第二个问题的最优值 d∗ 在这里提供了一个第一个问题的最优值 p∗ 的一个下界,在满足某些条件的情况下,这两者相等,这个时候我们就可以通过求解第二个问题来间接地求解第一个问题。
注:上段说“在满足某些条件的情况下”,这所谓的“满足某些条件”就是要先满足Slater's Condition,进而就满足KKT条件。理由如下3点所述(观点来自frestyle):
- 在convex problem中,d*和p*相同的条件是Slater's Condition,Slater's condition保证临界点saddle point存在。
- 至于KKT条件,首先原问题的最优值可以通过求Lagrangian的临界点saddle point(如果有的话)来得到,再者,KKT theorem里面进一步引入了更强的前提,也就是在满足Slater condition的同时(前面说了,Slater's condition保证临界点saddle point存在),f和gi都是可微的,这样saddle point不仅存在,而且能通过对Lagrangian求导得到,
- 所以KKT条件是一个点是最优解的条件,而不是d*=p*的条件,当然这个KKT条件对后边简化dual problem很关键。
那KKT条件的表现形式是什么呢?据维基百科:KKT 条件的介绍,一般地,一个最优化数学模型能够表示成下列标准形式:

所谓 Karush-Kuhn-Tucker 最优化条件,就是指上式的最小点 x* 必须满足下面的条件:

经过论证,我们这里的问题是满足 KKT 条件的(首先已经满足Slater condition,再者f和gi也都是可微的,即L对w和b都可导),因此现在我们便转化为求解第二个问题。也就是说,现在,咱们的原问题通过满足一定的条件,已经转化成了对偶问题。而求解这个对偶学习问题,分为3个步骤,首先要让L(w,b,a) 关于 w 和 b 最小化,然后求对α的极大,最后利用SMO算法求解对偶因子。
(1)、首先固定α,要让 L 关于 w 和 b 最小化,我们分别对w,b求偏导数,即令 ∂L/∂w 和 ∂L/∂b 等于零(对w求导结果的解释请看本文评论下第45楼回复,貌似博客系统故障,原来评论在第45楼的回复现在第45+81楼,即第126楼显示):
带回上述的 L:  ,得到:
,得到:

提醒:有读者可能会问上述推导过程如何而来?说实话,其具体推导过程是比较复杂的,如下图所示:
最后,得到:
如 jerrylead所说:“倒数第4步”推导到“倒数第3步”使用了线性代数的转置运算,由于ai和yi都是实数,因此转置后与自身一样。“倒数第3步”推导到“倒数第2步”使用了(a+b+c+…)(a+b+c+…)=aa+ab+ac+ba+bb+bc+…的乘法运算法则。最后一步是上一步的顺序调整。
从上面的最后一个式子,我们可以看出,此时的拉格朗日函数只包含了一个变量,那就是ai,然后下文的第2步,求出了ai便能求出w,和b,由此可见,上文第1.2节提出来的核心问题:分类函数w^T + b 也就可以轻而易举的求出来了。
由此看出,使用拉格朗日定理解凸最优化问题可以使用一个对偶变量表示,转换为对偶问题后,通常比原问题更容易处理,因为直接处理不等式约束是困难的,而对偶问题通过引入拉格朗日乘子(又称为对偶变量)来解。
(2)、求对α的极大,即是关于对偶变量dual variable α (下文将一直用粗体+下划线表示)的优化问题,从上面的式子得到:
(不得不提醒下读者:经过上面第一个步骤的求w和b,得到的拉格朗日函数式子已经没有了变量w,b,只有a,而反过来,求得的a将能导出w,b的解,最终得出分离超平面和分类决策函数。为何呢?因为如果求出了ai,根据
 ,
,即可求出w。然后通过
 ,即可求出b )
,即可求出b )

如前面所说,这个问题有更加高效的优化算法,即我们常说的SMO算法。
(3)、序列最小最优化SMO算法。细心的读者读至上节末尾处,怎么求对偶变量α的值可能依然心存疑惑,虽然在本文文末的参考文献的条目6和11中都有提到关于a的求解过程,但我还是觉得有必要简要简单介绍下。
实际上,此处对偶函数最后的优化问题:
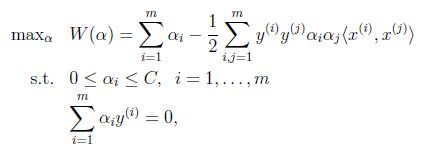

 和
和

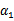 以外的所有参数,然后在
以外的所有参数,然后在
 上求极值。等一下,这个思路有问题,因为如果固定
上求极值。等一下,这个思路有问题,因为如果固定
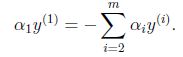
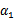 和
和
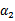 可以由
和其他参数表示出来。这样回带到W中,W就只是关于
可以由
和其他参数表示出来。这样回带到W中,W就只是关于

- 第一步选取一对

和
 ,选取方法使用启发式方法;
,选取方法使用启发式方法; - 第二步,固定除
和
之外的其他参数,确定W极值条件下的,
由表示。
2.1.2、线性不可分的情况
OK,为过渡到下节2.2节所介绍的核函数,让我们再来看看上述推导过程中得到的一些有趣的形式。首先就是关于我们的 hyper plane ,对于一个数据点 x 进行分类,实际上是通过把 x 带入到 f(x)=wTx+b 算出结果然后根据其正负号来进行类别划分的。而前面的推导中我们得到
w=∑ni=1αiyixi ,
因此分类函数为:

这里的形式的有趣之处在于,对于新点 x的预测,只需要计算它与训练数据点的内积即可(⋅,⋅表示向量内积),这一点至关重要,是之后使用 Kernel 进行非线性推广的基本前提。此外,所谓 Supporting Vector 也在这里显示出来——事实上,所有非 Supporting Vector 所对应的系数 α 都是等于零的,因此对于新点的内积计算实际上只要针对少量的“支持向量”而不是所有的训练数据即可。
为什么非支持向量对应的 α 等于零呢?直观上来理解的话,就是这些“后方”的点——正如我们之前分析过的一样,对超平面是没有影响的,由于分类完全有超平面决定,所以这些无关的点并不会参与分类问题的计算,因而也就不会产生任何影响了。
回忆一下我们2.1.1节中通过 Lagrange multiplier得到的目标函数:

注意到如果 xi 是支持向量的话,上式中红颜色的部分是等于 0 的(因为支持向量的 functional margin 等于 1 ),而对于非支持向量来说,functional margin 会大于 1 ,因此红颜色部分是大于零的,而 αi 又是非负的,为了满足最大化, αi 必须等于 0 。这也就是这些非 Supporting Vector 的点的局限性。
从1.5节到上述所有这些东西,便得到了一个maximum margin hyper plane classifier,这就是所谓的支持向量机(Support Vector Machine)。当然,到目前为止,我们的 SVM 还比较弱,只能处理线性的情况,不过,在得到了对偶dual 形式之后,通过 Kernel 推广到非线性的情况就变成了一件非常容易的事情了(相信,你还记得本节开头所说的:通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题)。
2.2、核函数Kernel
咱们首先给出核函数的来头:
- 在上文中,我们已经了解到了SVM处理线性可分的情况,而对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。由于核函数的优良品质,这样的非线性扩展在计算量上并没有比原来复杂多少,这一点是非常难得的。当然,这要归功于核方法——除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
也就是说,Minsky和Papert早就在20世纪60年代就已经明确指出线性学习器计算能力有限。为什么呢?因为总体上来讲,现实世界复杂的应用需要有比线性函数更富有表达能力的假设空间,也就是说,目标概念通常不能由给定属性的简单线性函数组合产生,而是应该一般地寻找待研究数据的更为一般化的抽象特征。
而下文我们将具体介绍的核函数则提供了此种问题的解决途径,从下文你将看到,核函数通过把数据映射到高维空间来增加第一节所述的线性学习器的能力,使得线性学习器对偶空间的表达方式让分类操作更具灵活性和可操作性。我们知道,训练样例一般是不会独立出现的,它们总是以成对样例的内积形式出现,而用对偶形式表示学习器的优势在为在该表示中可调参数的个数不依赖输入属性的个数,通过使用恰当的核函数来替代内积,可以隐式得将非线性的训练数据映射到高维空间,而不增加可调参数的个数(当然,前提是核函数能够计算对应着两个输入特征向量的内积)。
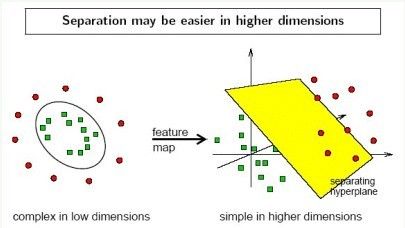


- 首先使用一个非线性映射将数据变换到一个特征空间F,
- 然后在特征空间使用线性学习器分类。

 ,这里φ是从X到内积特征空间F的映射。
,这里φ是从X到内积特征空间F的映射。
2.2.1、如何处理非线性数据
在2.1节中我们介绍了线性情况下的支持向量机,它通过寻找一个线性的超平面来达到对数据进行分类的目的。不过,由于是线性方法,所以对非线性的数据就没有办法处理了。举个例子来说,则是如下图所示的两类数据,分别分布为两个圆圈的形状,这样的数据本身就是线性不可分的,你准备如何把这两类数据分开呢(下文将会有一个相应的三维空间图)?

上图所述的这个数据集,就是用两个半径不同的圆圈加上了少量的噪音生成得到的,所以,一个理想的分界应该是一个“圆圈”而不是一条线(超平面)。如果用 X1 和 X2 来表示这个二维平面的两个坐标的话,我们知道一条二次曲线(圆圈是二次曲线的一种特殊情况)的方程可以写作这样的形式:
注意上面的形式,如果我们构造另外一个五维的空间,其中五个坐标的值分别为 Z1=X1 , Z2=X21 , Z3=X2 , Z4=X22 , Z5=X1X2 ,那么显然,上面的方程在新的坐标系下可以写作:
关于新的坐标 Z ,这正是一个 hyper plane 的方程!也就是说,如果我们做一个映射 ϕ:R2→R5 ,将 X 按照上面的规则映射为 Z ,那么在新的空间中原来的数据将变成线性可分的,从而使用之前我们推导的线性分类算法就可以进行处理了。这正是 Kernel 方法处理非线性问题的基本思想。
2.2.2、特征空间的隐式映射:核函数
再进一步描述 Kernel 的细节之前,不妨再来看看这个例子映射过后的直观例子。当然,你我可能无法把 5 维空间画出来,不过由于我这里生成数据的时候就是用了特殊的情形,具体来说,我这里的超平面实际的方程是这个样子(圆心在 X2 轴上的一个正圆):
因此我只需要把它映射到 Z1=X21 , Z2=X22 , Z3=X2 这样一个三维空间中即可,下图即是映射之后的结果,将坐标轴经过适当的旋转,就可以很明显地看出,数据是可以通过一个平面来分开的(pluskid:下面的gif 动画,先用 Matlab 画出一张张图片,再用 Imagemagick 拼贴成):

现在让我们再回到 SVM 的情形,假设原始的数据时非线性的,我们通过一个映射 ϕ(⋅) 将其映射到一个高维空间中,数据变得线性可分了,这个时候,我们就可以使用原来的推导来进行计算,只是所有的推导现在是在新的空间,而不是原始空间中进行。当然,推导过程也并不是可以简单地直接类比的,例如,原本我们要求超平面的法向量 w ,但是如果映射之后得到的新空间的维度是无穷维的(确实会出现这样的情况,比如后面会提到的 高斯核Gaussian Kernel ),要表示一个无穷维的向量描述起来就比较麻烦。于是我们不妨先忽略过这些细节,直接从最终的结论来分析,回忆一下,我们上一次2.1节中得到的最终的分类函数是这样的:

现在则是在映射过后的空间,即:

而其中的 α 也是通过求解如下 dual 问题而得到的:

这样一来问题就解决了吗?似乎是的:拿到非线性数据,就找一个映射 


 ,然后一股脑把原来的数据映射到新空间中,再做线性 SVM 即可。不过事实上没有这么简单!其实刚才的方法稍想一下就会发现有问题:在最初的例子里,我们对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了五个维度;如果原始空间是三维,那么我们会得到 19 维的新空间,这个数目是呈爆炸性增长的,这给 的计算带来了非常大的困难,而且如果遇到无穷维的情况,就根本无从计算了。所以就需要 Kernel 出马了。
,然后一股脑把原来的数据映射到新空间中,再做线性 SVM 即可。不过事实上没有这么简单!其实刚才的方法稍想一下就会发现有问题:在最初的例子里,我们对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了五个维度;如果原始空间是三维,那么我们会得到 19 维的新空间,这个数目是呈爆炸性增长的,这给 的计算带来了非常大的困难,而且如果遇到无穷维的情况,就根本无从计算了。所以就需要 Kernel 出马了。
不妨还是从最开始的简单例子出发,设两个向量 和
和 ,而
,而 即是到前面2.2.1节说的五维空间的映射,因此映射过后的内积为:
即是到前面2.2.1节说的五维空间的映射,因此映射过后的内积为:

(公式说明:上面的这两个推导过程中,所说的前面的五维空间的映射,这里说的前面便是文中2.2.1节的所述的映射方式,仔细看下2.2.1节的映射规则,再看那第一个推导,其实就是计算x1,x2各自的内积,然后相乘相加即可,第二个推导则是直接平方,去掉括号,也很容易推出来)
另外,我们又注意到:

二者有很多相似的地方,实际上,我们只要把某几个维度线性缩放一下,然后再加上一个常数维度,具体来说,上面这个式子的计算结果实际上和映射

之后的内积 的结果是相等的,那么区别在于什么地方呢?
的结果是相等的,那么区别在于什么地方呢?
- 一个是映射到高维空间中,然后再根据内积的公式进行计算;
- 而另一个则直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果。
(公式说明:上面之中,最后的两个式子,第一个算式,是带内积的完全平方式,可以拆开,然后,通过凑一个得到,第二个算式,也是根据第一个算式凑出来的)
回忆刚才提到的映射的维度爆炸,在前一种方法已经无法计算的情况下,后一种方法却依旧能从容处理,甚至是无穷维度的情况也没有问题。
我们把这里的计算两个向量在隐式映射过后的空间中的内积的函数叫做核函数 (Kernel Function) ,例如,在刚才的例子中,我们的核函数为:

核函数能简化映射空间中的内积运算——刚好“碰巧”的是,在我们的 SVM 里需要计算的地方数据向量总是以内积的形式出现的。对比刚才我们上面写出来的式子,现在我们的分类函数为:

其中  由如下 dual 问题计算而得:
由如下 dual 问题计算而得:

这样一来计算的问题就算解决了,避开了直接在高维空间中进行计算,而结果却是等价的!当然,因为我们这里的例子非常简单,所以我可以手工构造出对应于的核函数出来,如果对于任意一个映射,想要构造出对应的核函数就很困难了。
2.2.3、几个核函数
最理想的情况下,我们希望知道数据的具体形状和分布,从而得到一个刚好可以将数据映射成线性可分的,然后通过这个得出对应的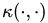 进行内积计算。然而,第二步通常是非常困难甚至完全没法做的。不过,由于第一步也是几乎无法做到,因为对于任意的数据分析其形状找到合适的映射本身就不是什么容易的事情,所以,人们通常都是“胡乱”选择映射的,所以,根本没有必要精确地找出对应于映射的那个核函数,而只需要“胡乱”选择一个核函数即可——我们知道它对应了某个映射,虽然我们不知道这个映射具体是什么。由于我们的计算只需要核函数即可,所以我们也并不关心也没有必要求出所对应的映射的具体形式。
进行内积计算。然而,第二步通常是非常困难甚至完全没法做的。不过,由于第一步也是几乎无法做到,因为对于任意的数据分析其形状找到合适的映射本身就不是什么容易的事情,所以,人们通常都是“胡乱”选择映射的,所以,根本没有必要精确地找出对应于映射的那个核函数,而只需要“胡乱”选择一个核函数即可——我们知道它对应了某个映射,虽然我们不知道这个映射具体是什么。由于我们的计算只需要核函数即可,所以我们也并不关心也没有必要求出所对应的映射的具体形式。
当然,也并不是任意的二元函数都可以作为核函数,所以除非某些特殊的应用中可能会构造一些特殊的核(例如用于文本分析的文本核,注意其实使用了 Kernel 进行计算之后,其实完全可以去掉原始空间是一个向量空间的假设了,只要核函数支持,原始数据可以是任意的“对象”——比如文本字符串),通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:
- 多项式核
,显然刚才我们举的例子是这里多项式核的一个特例(R = 1,d = 2)。虽然比较麻烦,而且没有必要,不过这个核所对应的映射实际上是可以写出来的,该空间的维度是
 ,其中
,其中  是原始空间的维度。
是原始空间的维度。 - 高斯核
 ,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果
,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间: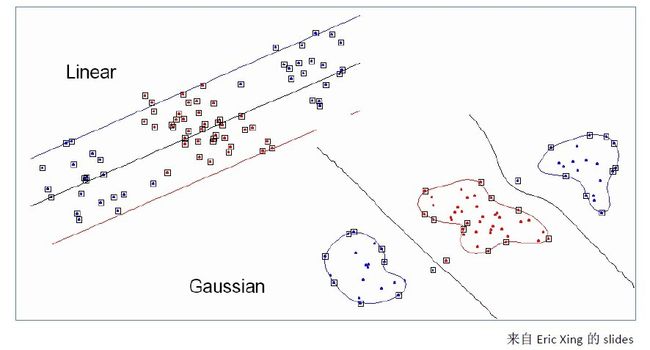
- 线性核
 ,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
2.2.4、核函数的本质
- 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如上文2.2节最开始的那幅图所示,映射到高维空间后,相关特征便被分开了,也就达到了分类的目的);
- 但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的(如上文中19维乃至无穷维的例子)。那咋办呢?
- 此时,核函数就隆重登场了,核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
z5qh8%7D9.jpg)
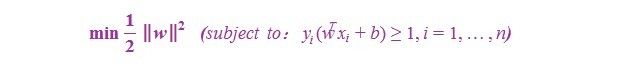



第二步、对α求极大如下所示:


2.3、使用松弛变量处理 outliers 方法
在本文第一节最开始讨论支持向量机的时候,我们就假定,数据是线性可分的,亦即我们可以找到一个可行的超平面将数据完全分开。后来为了处理非线性数据,在上文2.2节使用 Kernel 方法对原来的线性 SVM 进行了推广,使得非线性的的情况也能处理。虽然通过映射 将原始数据映射到高维空间之后,能够线性分隔的概率大大增加,但是对于某些情况还是很难处理。例如可能并不是因为数据本身是非线性结构的,而只是因为数据有噪音。对于这种偏离正常位置很远的数据点,我们称之为 outlier ,在我们原来的 SVM 模型里,outlier 的存在有可能造成很大的影响,因为超平面本身就是只有少数几个 support vector 组成的,如果这些 support vector 里又存在 outlier 的话,其影响就很大了。例如下图:

用黑圈圈起来的那个蓝点是一个 outlier ,它偏离了自己原本所应该在的那个半空间,如果直接忽略掉它的话,原来的分隔超平面还是挺好的,但是由于这个 outlier 的出现,导致分隔超平面不得不被挤歪了,变成途中黑色虚线所示(这只是一个示意图,并没有严格计算精确坐标),同时 margin 也相应变小了。当然,更严重的情况是,如果这个 outlier 再往右上移动一些距离的话,我们将无法构造出能将数据分开的超平面来。
为了处理这种情况,SVM 允许数据点在一定程度上偏离一下超平面。例如上图中,黑色实线所对应的距离,就是该 outlier 偏离的距离,如果把它移动回来,就刚好落在原来的超平面上,而不会使得超平面发生变形了。具体来说,原来的约束条件

现在变成

其中 称为松弛变量 (slack variable) ,对应数据点
称为松弛变量 (slack variable) ,对应数据点 允许偏离的 functional margin 的量。当然,如果我们运行
允许偏离的 functional margin 的量。当然,如果我们运行 任意大的话,那任意的超平面都是符合条件的了。所以,我们在原来的目标函数后面加上一项,使得这些的总和也要最小:
任意大的话,那任意的超平面都是符合条件的了。所以,我们在原来的目标函数后面加上一项,使得这些的总和也要最小:

其中  是一个参数,用于控制目标函数中两项(“寻找 margin 最大的超平面”和“保证数据点偏差量最小”)之间的权重。注意,其中
是一个参数,用于控制目标函数中两项(“寻找 margin 最大的超平面”和“保证数据点偏差量最小”)之间的权重。注意,其中  是需要优化的变量(之一),而 是一个事先确定好的常量。完整地写出来是这个样子:
是需要优化的变量(之一),而 是一个事先确定好的常量。完整地写出来是这个样子:


分析方法和前面一样,转换为另一个问题之后,我们先让 针对
针对 、
、  和
和 最小化:
最小化:

将  带回
带回  并化简,得到和原来一样的目标函数:
并化简,得到和原来一样的目标函数:

不过,由于我们得到 而又有
而又有 (作为 Lagrange multiplier 的条件),因此有
(作为 Lagrange multiplier 的条件),因此有 ,所以整个 dual 问题现在写作:
,所以整个 dual 问题现在写作:
和之前的结果对比一下,可以看到唯一的区别就是现在 dual variable
多了一个上限
。而 Kernel 化的非线性形式也是一样的,只要把
 换成
换成
 即可。这样一来,一个完整的,可以处理线性和非线性并能容忍噪音和 outliers 的支持向量机才终于介绍完毕了。继续深入请阅读参考文献及推荐阅读的条目
6。
即可。这样一来,一个完整的,可以处理线性和非线性并能容忍噪音和 outliers 的支持向量机才终于介绍完毕了。继续深入请阅读参考文献及推荐阅读的条目
6。
2.4、小结
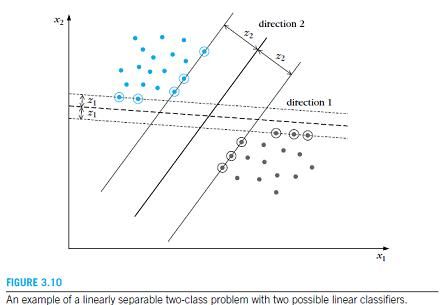
综上所述,对于一个线性可分的两类问题,我们可以通过g(x)=w^T*x+w0=0确定一个分类面把这两类分开。我们的目的是为了建立一个这样的分类面,事实上这样的分类面不是唯一确定的。在感知器里我们通过梯度下降法优化出一个分类器初始值的选择、迭代步长等的不同得到的分类器也不同。那么我们需要在这些分离器里找一个最好的。
如图所示,我们可以认为direction2的分类效果要比 direction1的分类效果要好,因为direction2的裕量比direction1大。我们需要在这各个分类器中选择一个最优的。SVM是根据统计学习理论依照结构风险最小化的原则提出的,要求实现两个目的:1)两类问题能够分开(经验风险最小)2)margin最大化(风险上界最小)既是在保证风险最小的子集中选择经验风险最小的函数。
把样本到分类面的距离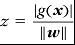
进行归一化处理后我们得到里分类面最近的样本g(x) = 1。
这样我们就有边界margin: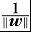 ,这里满足这样条件的样本点就是我们所谓的支持向量。
,这里满足这样条件的样本点就是我们所谓的支持向量。
这样我们就转化为一个优化问题Sergios Theodoridis:

建立拉格朗日方程并引入KKT条件得到:
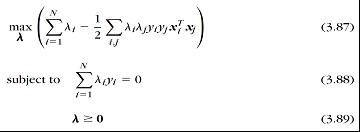
由上式得到判别函数式:
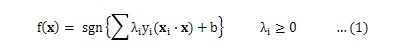
对于不是线性可分的问题,我们可以通过加入松弛子C来解决:
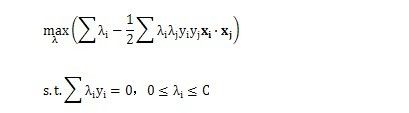
由以上讨论我们得到判别函数只与向量的內积有关,因此我们可以选择一个非线性变换将x映射到高维空间,在低维空间不可分的问题映射到高维空间后就有可能是线性可分的。这里我们不需要知道是什么形式的只需要关注內积运算即可。由此,可以通过构造核函数实现:
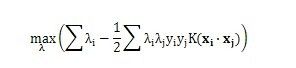
这里的核函数的选择没有特别的方式,在Chih-Wei Hsu中推荐使用径向基函数。
故不准确的说,SVM它本质上即是一个分类方法,用w^T+b定义分类函数,于是求w、b,为寻最大间隔,引出1/2||w||^2,继而引入拉格朗日因子,化为对单一因数对偶变量a的求解(求解过程中会涉及到一系列最优化或凸二次规划等问题),如此,求w.b与求a等价,而求a的解法即为SMO,至于核函数,是为处理非线性情况,若直接映射到高维计算恐维度爆炸,故在低维计算,等效高维表现。
OK,理解到这第二层,已经能满足绝大部分人一窥SVM原理的好奇心,然对于那些想在证明层面理解SVM的则还很不够,但进入第三层理解境界之前,你必须要有比较好的数理基础和逻辑证明能力,不然你会跟我一样,吃不少苦头的。
第三层、证明SVM
说实话,凡是涉及到要证明的东西.理论,便一般不是怎么好惹的东西。绝大部分时候,看懂一个东西不难,但证明一个东西则需要点数学功底,进一步,证明一个东西也不是特别难,难的是从零开始发明创造这个东西的时候,则显艰难(因为任何时代,大部分人的研究所得都不过是基于前人的研究成果,前人所做的是开创性工作,而这往往是最艰难最有价值的,他们被称为真正的先驱。牛顿也曾说过,他不过是站在巨人的肩上。你,我则更是如此)。
正如陈希孺院士在他的著作「数理统计学简史」的第4章、最小二乘法中所讲:在科研上诸多观念的革新和突破是有着很多的不易的,或许某个定理在某个时期由某个人点破了,现在的我们看来一切都是理所当然,但在一切没有发现之前,可能许许多多的顶级学者毕其功于一役,耗尽一生,努力了几十年最终也是无功而返。
OK,以下内容基本属于自己在看支持向量机导论一书的理解,包括自己对一些证明的理解,还是读书笔记。
本部分导述
- 3.1节线性学习器一部分中,主要阐述3个东西,感知机算法,松弛变量,及最小二乘理论,同时,基本上是贴的用相机拍的照片(为什么?懒);
- 3.2节、核函数特征空间;
- 3.3节、SMO算法;
- 3.4节、简略谈谈SVM的应用。
3.1、线性学习器
3.1.1、感知机算法


3.1.2、松弛变量


针对上面左图的说明:我们知道,当分类出现了误差,要么就是被误分,要么就是没有以正常的间隔被分开:
- 被误分。如上面左图所示,如果一切正常的话,那么xi出现的位置不该是那里,而是该左图中左边那个箭头所示,被“拉回去”,而既然出现在了这个不正常的位置,那么有什么后果内,这就导致了所谓的被误分,使得最终的松弛变量>0;同理,oj也不该出现在那个位置,而应该被“拉回去”。
- 没有以正常的间隔被分开。还是如上面所示左图,xk显然没有被以正常的间隔分开,而是过于靠近超平面。
当然,还需要满足一些条件,根据 margin 的定义,我们有
3.2、最小二乘法
既然本节开始之前提到了最小二乘法,那么下面稍微简单阐述下。
我们口头中经常说:一般来说,平均来说。如平均来说,不吸烟的健康优于吸烟者,之所以要加“平均”二字,是因为凡事皆有例外,总存在某个特别的人他吸烟但由于经常锻炼所以他的健康状况可能会优于他身边不吸烟的朋友。而最小二乘法的一个最简单的例子便是算术平均。
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。用函数表示为:

使误差「所谓误差,当然是观察值与实际真实值的差量」平方和达到最小以寻求估计值的方法,就叫做最小二乘法,用最小二乘法得到的估计,叫做最小二乘估计。当然,取平方和作为目标函数只是众多可取的方法之一。
最小二乘法的一般形式可表示为:

有效的最小二乘法是勒让德在 1805 年发表的,基本思想就是认为测量中有误差,所以所有方程的累积误差为
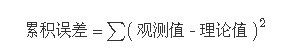
我们求解出导致累积误差最小的参数即可。
勒让德在论文中对最小二乘法的优良性做了几点说明:
- 最小二乘使得误差平方和最小,并在各个方程的误差之间建立了一种平衡,从而防止某一个极端误差取得支配地位
- 计算中只要求偏导后求解线性方程组,计算过程明确便捷
- 最小二乘可以导出算术平均值作为估计值
对于最后一点,从统计学的角度来看是很重要的一个性质。推理如下:假设真值为 θ , x1,⋯,xn 为n次测量值, 每次测量的误差为 ei=xi−θ ,按最小二乘法,误差累积为
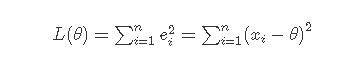
求解 θ 使得 L(θ) 达到最小,正好是算术平均 xˉ=∑ni=1xin 。
由于算术平均是一个历经考验的方法,而以上的推理说明,算术平均是最小二乘的一个特例,所以从另一个角度说明了最小二乘方法的优良性,使我们对最小二乘法更加有信心。
最小二乘法发表之后很快得到了大家的认可接受,并迅速的在数据分析实践中被广泛使用。不过历史上又有人把最小二乘法的发明归功于高斯,这又是怎么一回事呢。高斯在1809年也发表了最小二乘法,并且声称自己已经使用这个方法多年。高斯发明了小行星定位的数学方法,并在数据分析中使用最小二乘方法进行计算,准确的预测了谷神星的位置。
OK,更多请参看陈希孺院士的「数理统计学简史」的第4章、最小二乘法。
3.3、核函数特征空间
经过前面第一、二部分,我们已经知道,当把内积就变成之后,求将有两种方法:
1、先找到这种映射,然后将输入空间中的样本映射到新的空间中,最后在新空间中去求内积。以多项式 为例,对其进行变换,,,,,得到:,也就是说通过把输入空间从二维向四维映射后,样本由线性不可分变成了线性可分,但是这种转化带来的直接问题是维度变高了,这意味着,首先可能导致后续计算变复杂,其次可能出现维度之咒,对于学习器而言就是:特征空间维数可能最终无法计算,而它的泛化能力(学习器对训练样本以外数据的适应性)会随着维度的增长而大大降低,这也违反了“奥坎姆的剃刀”,最终可能会使得内积无法求出,于是也就失去了这种转化的优势了;
2、或者是找到某种方法,它不需要显式的将输入空间中的样本映射到新的空间中而能够在输入空间中直接计算出内积。它其实是对输入空间向高维空间的一种隐式映射,它不需要显式的给出那个映射,在输入空间就可以计算,这就是传说中的核函数方法。
OK, 不再做过多介绍了,对核函数有进一步兴趣的,还可以看看此文:http://www.cnblogs.com/vivounicorn/archive/2010/12/13/1904720.html。3.4、SMO算法
SMO算法是<
上文2.1.1节已经提到过,SMO算法不过是为了解决对偶问题中对偶因子α的求解问题,这两篇文章:http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html,http://www.cnblogs.com/vivounicorn/archive/2011/06/01/2067496.html,已经介绍的相当详尽,包括算法思想及其实现,此处不再赘述。
3.5、SVM的应用
或许我们已经听到过,SVM在很多诸如文本分类,图像分类,生物序列分析和生物数据挖掘,手写字符识别等领域有很多的应用,但或许你并没强烈的意识到,SVM可以成功应用的领域远远超出现在已经在开发应用了的领域。
3.5.1、文本分类
一个文本分类系统不仅是一个自然语言处理系统,也是一个典型的模式识别系统,系统的输入是需要进行分类处理的文本,系统的输出则是与文本关联的类别。由于篇幅所限,其它更具体内容本文将不再详述。
OK,本节虽取标题为证明SVM,但聪明的读者们想必早已看出,其实本部分并无多少证明部分(特此致歉),怎么办呢?可以参阅支持向量机导论一书,此书精简而有趣。
最后,非常感谢pluskid及诸多朋友&牛人们的文章及著作,让我有机会在其基础上总结、深入,本文基本成型。谢谢。
参考文献及推荐阅读
- 《支持向量机导论》,[美] Nello Cristianini / John Shawe-Taylor 著;
- 支持向量机导论一书的支持网站:http://www.support-vector.net/;
- 《数据挖掘导论》,[美] Pang-Ning Tan / Michael Steinbach / Vipin Kumar 著;
- 《数据挖掘:概念与技术》,(加)Jiawei Han;Micheline Kamber 著;
- 《数据挖掘中的新方法:支持向量机》,邓乃扬 田英杰 著;
- 《支持向量机--理论、算法和扩展》,邓乃扬 田英杰 著;
- 支持向量机系列,pluskid:http://blog.pluskid.org/?page_id=683;
- http://www.360doc.com/content/07/0716/23/11966_615252.shtml;
- 数据挖掘十大经典算法初探;
- 《模式识别支持向量机指南》,C.J.C Burges 著;
- 《统计学习方法》,李航著(第7章有不少内容参考自支持向量机导论一书,不过,可以翻翻看看);
- 《统计自然语言处理》,宗成庆编著,第十二章、文本分类;
- SVM入门系列,Jasper:http://www.blogjava.net/zhenandaci/category/31868.html;
- 最近邻决策和SVM数字识别的实现和比较,作者不详;
- 斯坦福大学机器学习课程原始讲义:http://www.cnblogs.com/jerrylead/archive/2012/05/08/2489725.html;
- 斯坦福机器学习课程笔记:http://www.cnblogs.com/jerrylead/tag/Machine%20Learning/;
- http://www.cnblogs.com/jerrylead/archive/2011/03/13/1982639.html;
- http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html;
- 数据挖掘掘中所需的概率论与数理统计知识、上;
- 关于机器学习方面的文章,可以读读:http://www.cnblogs.com/vivounicorn/category/289453.html;
- 数学系教材推荐:http://blog.sina.com.cn/s/blog_5e638d950100dswh.html;
- 《神经网络与机器学习(原书第三版)》,[加] Simon Haykin 著;
- 正态分布的前世今生:http://t.cn/zlH3Ygc;
- 《数理统计学简史》,陈希孺院士著;
- 《最优化理论与算法(第2版)》,陈宝林编著。
- 顶
- 101
- 踩
- 4
- 100楼 cdlh31415_1 2013-07-11 12:24发表 [回复]
-

- 顶礼膜拜 啊, 受教了!!!!!!!!!!
- 99楼 wangcong0755 2013-06-28 16:17发表 [回复]
-

-
楼主你好,请问你对SVM的研究是出于理论上的研究还是编程实现过呢?如果编程实现过,使用的是什么语言呢?
- Re: v_JULY_v 昨天 23:50发表 [回复]
-

-
回复wangcong0755:给你看看微博上@余凯_西二旗民工 贴的matlab伪代码:
- yp=x*w;
- idx=find(yp*y<1);
- e=yp(idx)-y(idx);
- df=2(x(idx,:)'*e+c*w);
- f=e'*e+c*w*w;
5行代码算完f和df, 把俩扔进lbfgs,完毕:-)
- 98楼 zhangen00 2013-06-25 17:58发表 [回复]
-

-
我这边刷新无数次,小图片全挂了,实在打不开,能不能发份pdf给我。非常感谢。邮箱 [email protected]
- Re: v_JULY_v 2013-06-25 21:43发表 [回复]
-
-
回复zhangen00:你好,是用的chrome浏览器么?
如果仍然无法正常显示图片的话,可以到这里找到链接:http://weibo.com/1580904460/zBhJiaknB,下载到截止2013年6月12日前,本博客内所有博文集锦的PDF文档:-)- Re: zhangen00 2013-06-25 23:04发表 [回复]
-
- 回复v_JULY_v:谢谢
- 97楼 LucienDuan 2013-06-24 13:05发表 [回复]
-

- 谢谢,写得很好!!
- 96楼 Bikong2 2013-06-08 16:32发表 [回复]
-

- 高水平博文,非常感谢...
- 95楼 陈江-V 2013-06-05 15:21发表 [回复]
-

-
简单的问题,如何确认一个分类需求是否是线性可分的?是否使用svm?
- Re: 月光海苔 2013-07-05 17:25发表 [回复]
-

- 回复ChenJiangV:假设集合A与集合B两类,将集合A,B的所有点都扩展一个维度即(X,1),形成一个新的集合A1与B1,令集合D=A1∪(-B1).由集合D1构成的凸闭包S,如果S不包含原点则线性可分否则不可分
- 94楼 陈江-V 2013-06-04 18:38发表 [回复]
-
- 问个问题,我拿到一个分类需求时候,如何确定是不是线性可分的呢?
- 93楼 sharling_lin 2013-05-30 22:14发表 [回复]
-

-
这个SVM的介绍写得确实很好,看了很受启发。有个问题想跟博主请教下。
对于outlier,假设第k个样本是outlier,那么优化带松弛因子的拉格朗日函数后,一定会得到第k个松弛因子不为0,而由kkt条件rk=0;那么可以得到alpha_k=C。想问的是分类函数,这个alpha_k,以及对应的xk是不是舍弃了,也就是虽然alpha_k = C;但是和其他非支撑向量一样对最后的分类函数不起作用?
- 92楼 zyawf810 2013-05-18 16:42发表 [回复]
-

-
楼主,您好。看了您的文章后,有些地方想请教您。1.支持向量机在划分为多类的情况下效果如何?2.划分为两类的时候,结果标签用-1 和1 来表示,如果到划分多类的情况下,该如何表示呢?多类的情况下,是两两组合进行划分还是直接划分?3.对于分好的每一类,是否能找到一个平面使该类数据都在这个平面上么?期待大神的解答~谢谢~
- Re: v_JULY_v 2013-05-19 12:06发表 [回复]
-
-
回复zyawf810:你好,关于将SVM用于多类分类的情况,具体你可以看下这篇文章:http://www.blogjava.net/zhenandaci/archive/2009/03/26/262113.html。
- Re: zyawf810 2013-05-19 20:30发表 [回复]
-
- 回复v_JULY_v:谢谢~受益匪浅\(^o^)/~
- 91楼 cuimiao_1990 2013-04-28 08:57发表 [回复]
-

-
您好,不知道您对mercer定理的证明有没有去证明一下,就《支持向量机导论》您推荐书目的3.3.1 中证明特征值非负的那段,关于特征空间中的点:z的表示是怎么得出来的?其实就一个式子不太懂。。。。向大神请教。。。。
- Re: v_JULY_v 2013-04-28 10:14发表 [回复]
-
- 回复fubannian:你好,回头我看下《支持向量机导论》,尽快给你答复:-)
- 90楼 xiaofuchang 2013-04-20 12:37发表 [回复]
-

- 你好,请问lz 在SVM 深入第二层的讲解中,关于b* 的解法,是怎么推导出来的;另外有没有可能求解出的支持向量,只存在一部分,例如只有正例的某些支持向量点满足,yi(wxi+b-1)=0,其中yi=1,而在负类中找不到这样的点,使得其成为支持向量。这个怎样从公式的角度来理解。多谢。
- 89楼 ImgHJK 2013-04-09 21:48发表 [回复]
-

-
想和您私聊下关于匹配的算法,谢谢
- Re: v_JULY_v 2013-04-09 22:00发表 [回复]
-
- 回复hjkhjk007:你好,咱们可以在微博上http://weibo.com/julyweibo,用私信聊:-)
- 88楼 miluzhiyu 2013-04-09 20:25发表 [回复]
-

-
请问在几何间隔那一块,直线方程应该是wx+b-y = 0,而不是wx+b = 0(这个是一条平行于x轴的直线啊),这样的话,带入点到直线公式不就不对了么。。。
- Re: 夏青 2013-04-15 22:39发表 [回复]
-

-
回复miluzhiyu:1.3.2章节刚开始看也不太懂,也想问下博主在二维中:ax+by+c=0 中的y是否考虑为向量中的一个,比如二维向量我们用(x,y)表示,也可以用(x0,x1)表示,在ax+by+c/sqrt(a*a+b*b) 表示为ax0+bx1+c/sqrt(a*a+b*b) ,这样的话 r= wTx+b / //w//也就好理解了,即X=(x,y) 也等价于X=(x0,x1) 了,这样理解可以不?
- Re: v_JULY_v 2013-04-20 20:34发表 [回复]
-
-
回复WishLifeHappy:可以,上文本来就是这样说的嘛:“假设一条直线的方程为ax+by+c=0,点P的坐标是(x0,y0),则点到直线距离为|ax0+by0+c|/sqrt(a^2+b^2)。”
- Re: 夏青 2013-04-21 15:42发表 [回复]
-
- 回复v_JULY_v:嗯,谢谢啦!
- Re: miluzhiyu 2013-04-09 20:30发表 [回复]
-
-
回复miluzhiyu:补充一下,在直线上的概念应该也就是ax+by+c = 0呀。。。我开始糊涂了。。。
- Re: miluzhiyu 2013-04-09 20:43发表 [回复]
-
-
回复miluzhiyu:是不是因为X = (x,y)!!!我貌似想通了!
- Re: v_JULY_v 2013-04-20 20:41发表 [回复]
-
- 回复miluzhiyu:Yeah,You got it!
- 87楼 frestyle 2013-04-03 05:22发表 [回复]
-

-
大赞楼主的文章,不过<这所谓的“满足某些条件”就是要满足KKT条件>—— 我觉得楼主这里搞错了KKT的角色,在convex problem中,d*和p*相同的条件是Slater's Condition。至于KKT条件:首先原问题的最优值可以通过求Lagrangian的saddle point(如果有的话)来得到,而Slater's condition保证saddle point存在;KKT theorem里面进一步引入了更强的前提,也就是在满足Slater condition的同时,f和gi都是可微的,这样saddle point不仅存在,而且能通过对Lagrangian求导得到。所以KKT条件是一个点是最优解的条件,而不是d*=p*的条件。当然这个KKT条件对后边简化dual problem很关键。
- Re: v_JULY_v 2013-04-04 00:53发表 [回复]
-
-
回复frestyle:非常赞!很细心,谢谢你,我改动下。
- Re: frestyle 2013-04-04 04:23发表 [回复]
-
- 回复v_JULY_v:不客气,我才疏学浅,希望多交流!
- 86楼 miluzhiyu 2013-03-30 20:49发表 [回复]
-
-
不能查看所有评论是怎么回事。。。请问。。。
- Re: v_JULY_v 2013-04-04 00:53发表 [回复]
-
-
回复miluzhiyu:现在可以看了么?我这边显示正常。
- Re: miluzhiyu 2013-04-04 18:32发表 [回复]
-
-
回复v_JULY_v:貌似还是不行~查看更多评论只能按一次。。。然后也没有翻页。。。
- Re: v_JULY_v 2013-04-04 20:58发表 [回复]
-
-
回复miluzhiyu:恩,我仔细看了下,虽然我这边能显示也能查看更多评论,但实际上本文的评论标号是从第81楼开始标示的,即按常理应该是第1楼、第2楼、第3楼..
但可能是博客系统的故障,评论显示直接是第81楼、第82楼、第83楼..
之前是显示正常的,包括原来的第45楼,现在变成了第45+81=126楼..- Re: miluzhiyu 2013-04-08 16:55发表 [回复]
-
-
回复v_JULY_v:作者好细心!谢谢!灰常感动~
话说我有一个地方木有很懂,就是关于离群点,如果要编程,如何得到离群点到原来群的间隔平面的距离呢?我怎么就知道它是离群点呢?在得到分类超平面之前我也不知道平面上面是哪个类,平面下面是哪个类啊。。。有种搞混了的赶脚。。。- Re: v_JULY_v 2013-04-08 17:07发表 [回复]
-
-
回复miluzhiyu:离群点是在已经得到分类超平面的情况下后,那个偏离正常位置很远的数据点,我们称之为离群点或outlier 。
如上文2.3节所述,“黑圈圈起来的那个蓝点是一个 outlier ,它偏离了自己原本所应该在的那个半空间”,也就是说每个点的位置其实在寻找分类超平面之前早就已经固定,只是根据从众原则,那些孤立的点,离大众比较偏远的点,我们称之为离群点,至于偏离的距离则是至少大于它离support vector的距离。- Re: miluzhiyu 2013-04-08 20:15发表 [回复]
-
-
回复v_JULY_v:那就是在计算超平面的时候,也是有这些离群点存在的?那也就是说离群点也有可能会影响到超平面的确定?
- Re: v_JULY_v 2013-04-08 21:00发表 [回复]
-
-
回复miluzhiyu:是的。
- Re: miluzhiyu 2013-04-09 17:04发表 [回复]
-
-
回复v_JULY_v:好的~十分感谢~我在看的时候这些细节都没注意到。。。老师提问的时候一下子就被问住了。。。
- Re: v_JULY_v 2013-04-09 17:18发表 [回复]
-
-
回复miluzhiyu:你后来有反问你老师么?他怎么回答你的呢..
- Re: miluzhiyu 2013-04-09 17:27发表 [回复]
-
- 回复v_JULY_v:木有。。。他也不太懂这个方面,就只会用。。。喊我学习一下在讨论会上,然后大家共同学习。。。
- 85楼 neiblegy 2013-03-27 15:22发表 [回复]
-

-
从2.2.2我这里公式图片加载失败,是我个人网络问题么?楼主有word版的没?谢谢分享 学习
- Re: v_JULY_v 2013-04-08 17:08发表 [回复]
-
- 回复neiblegy:你好,我已经处理好了,现在图片加载应该显示正常了:-)
- Re: real007fei 2013-03-27 17:14发表 [回复]
-

-
回复neiblegy:目测是加载 blog.pluskid.org上的图片时,出了错误。
楼主能否提供word或者pdf版本呢?
谢谢额- Re: v_JULY_v 2013-03-28 10:52发表 [回复]
-
-
回复real007fei:非常非常感谢你的反馈,我这两天紧急处理下,在此之前你可以试着:
1、尽量用有线网络,图片显示的情况好于无线网络;
2、在这里下载本blog全部博文集锦的第7期CHM文件:http://download.csdn.net/download/v_july_v/4463100。
我一定尽快处理好,再谢。
- Re: yongli2011 2013-03-27 16:08发表 [回复]
-

-
回复neiblegy:我也遇到这个问题了,不知道怎么回事
- Re: real007fei 2013-03-27 17:12发表 [回复]
-
-
回复yongli2011:对,我也是,很多公式的图片加载不了。
全部是空白,郁闷死了。- Re: v_JULY_v 2013-04-03 13:00发表 [回复]
-
- 回复real007fei:Hi,朋友,上文中大部图片我都已经全部重新上传了,现在可以正常显示,感谢你的反馈。
- 84楼 zhulinniao 2013-03-26 13:07发表 [回复]
-

- 楼主 可有随机森林的相关算法介绍啊 或者是程序啊????????
- 83楼 chenfeilong101 2013-03-22 22:38发表 [回复]
-

- 博主辛苦了。。。。谢谢你提供的资料。
- 82楼 lailai1990 2013-03-22 09:11发表 [回复]
-

-
42楼呢?
- Re: v_JULY_v 2013-04-04 21:13发表 [回复]
-
-
回复lailai1990:你好,貌似博客本身系统故障,原来评论在第42楼的回复现在第42+81楼,即第123楼显示了!故,请直接查找第123楼的回复。
感谢反馈,谅解。
- 81楼 real007fei 2013-03-20 21:28发表 [回复]
-
- 真不错,收藏了!
- 80楼 o60514207 2013-03-16 22:50发表 [回复]
-

-
还有就是2.1中很长的那段推导,为什么最后就把含b的那项给消去了?
因为ai*yi=0 ^.^- Re: v_JULY_v 2013-04-04 21:20发表 [回复]
-
-
回复o60514207:你好,因为aiyi = 0,故b∑αiyi=0,所以,才把含b的项给消除了呢。
具体来说是,在2.1节那,首先固定α,要让 L 关于 w 和 b 最小化,我们分别对w,b求偏导数,即令 ∂L/∂w 和 ∂L/∂b 等于零,∑αiyi=0,同时,还特地补充了那段推导的详细过程,你可以再看看。
- 79楼 o60514207 2013-03-16 22:46发表 [回复]
-
-
容易验证,当某个约束条件不满足时,例如 yi(wTxi+b)<1,那么我们显然有 θ(w)=∞(只要令 αi=∞ 即可)
这里我没看懂……
还有就是2.1中很长的那段推导,为什么最后就把含b的那项给消去了?
- 78楼 铁兵 2013-03-11 22:29发表 [回复]
-

- 楼主好人,辛苦了。。
- 77楼 Emilywohappy 2013-02-26 15:49发表 [回复]
-

-
请问博主,支持向量机导论这本书您在哪里买的?我找了很多网上卖书的地方都说缺货
- Re: v_JULY_v 2013-02-26 16:13发表 [回复]
-
- 回复Emilywohappy:你好,支持向量机导论这本书网上卖的地方的确应该不好找了,不过,你可以找到它的电子版PDF,然后打印之,细细品读呢。
- 76楼 gogo00007 2013-02-25 16:15发表 [回复]
-

-
---正如本文评论下读者popol1991留言:函数间隔y*(wx+b)=y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量。
这个准确么?因为(wx+b)不一定跟y同号啊,如果是分类错误的情况下。
- 75楼 lijil168 2013-01-20 13:08发表 [回复]
-

-
昨天花了半天时间才看明白Mercer定理的证明。不知道作者为什么把vti s.t.i=1:n 记作特征矩阵V的第t列,即特征向量Vt,
我习惯vit s.t.i=1:n 记作特征向量Vt,用matlab描述就是v(:,t),更自然些,对Vit,i表示行,t表示列。
- 74楼 ljb1672 2013-01-20 11:38发表 [回复]
-

- 感谢博主的无私的精神,博主是否能将博文制作成.pdf以方便我等拜读
- 73楼 lijil168 2013-01-19 00:50发表 [回复]
-
- 楼主真厉。我花了几天看完两章,总算对机器学习有点点了解了。也照样子做出了核函数多类分类程序,并画出原始点的分界线。但到后面的理论就看不懂了了。不知楼主怎么学的?我很想知道msv在控制系统的应用案例,
- 72楼 kehaar0028 2013-01-18 11:20发表 [回复]
-

-
你好,、2.2.2里面这一段(等式没有粘贴过来)
”不妨还是从最开始的简单例子出发,设两个向量 和 ,而 即是到前面2.2.1节说的五维空间的映射,因此映射过后的内积为:
。。。
二者有很多相似的地方,实际上,我们只要把某几个维度线性缩放一下,然后再加上一个常数维度“
这个缩放对于最后的结果有影响吗?常数维度要怎么理解?
还有2.3处理outlier里面第一个图下面讲
“例如上图中,黑色实线所对应的距离,就是该 outlier 偏离的距离,如果把它移动回来,就刚好落在原来的超平面上,而不会使得超平面发生变形了”
如果按黑色实线移动回来是落在蓝色的线上么(有支持向量的线上)?超平面我认为是中间红色的线,这里怎么理解?
谢谢你!你写的东西对我入门起到很大作用,我读了BURGES的向量机识别指南和Nello的向量机导论还是不如这篇文章浅显有这样一个一环扣一环的逻辑。十分感谢你!
- 71楼 star_twinkle 2013-01-09 23:38发表 [回复]
-

- 楼主,牛逼啊,很感谢你的文章!!!
- 70楼 ga6840 2013-01-03 16:36发表 [回复]
-

-
“ 带回上述的 L”那个式子用 一个∑去表示两个嵌套的∑,有这样的表示习惯吗?
- Re: v_JULY_v 2013-01-04 15:00发表 [回复]
-
- 回复ga6840:你好,的确不可以,择日修改下,谢谢你。
- 69楼 kele86838437 2012-12-21 14:15发表 [回复]
-

- 弱弱的建议一下,γ˜=yγ=γˆ∥w∥虽然可以这样写,但是不细看γ˜,γˆ还是挺容易弄混的。
- 68楼 dyf2886136 2012-12-20 16:43发表 [回复]
-

-
花了一下午看了lz的这篇文章,有几点疑问的地方希望能解答写,万分感激:
1.关于C(惩罚因子)在你的文章里好像只是用来确定ai的上届,而且是事先提供给机器,那个C的选择有什么原则?还有我理解的C应该是迭代变化的
2.虽然最终其分类作用的是支持向量,但是我感觉如果向量位数特别高也是会影响计算效果的
3.还有一点不明白的地方,高维空间内积运算一定可以转换(或存在)为低维的核函数吗?
谢谢,同时也祝你的一切都顺利^_^
- 67楼 dd919909544 2012-12-17 16:48发表 [回复]
-

- 我想请问支持向量机的数学表达式 怎么求??
- 66楼 zxy605555294 2012-12-05 10:36发表 [回复]
-

- 谢谢~
- 65楼 zxy605555294 2012-12-03 10:22发表 [回复]
-
-
统计学习方法的 电子书 哪里可以下载到呢?看到你截图了里面的许多内容,应该是由电子书的了,分享下啊?
- Re: v_JULY_v 2012-12-03 10:32发表 [回复]
-
-
回复zxy605555294:你好,原文只截取了统计学习方法一书仅一张图,在原文1.1节。
到这里可以下载前3章的电子书:http://vdisk.weibo.com/s/fPfxQ。
- 64楼 Noadvanceistogoback 2012-11-30 18:51发表 [回复]
-

-
膜拜下高手。是硕士吗。
- Re: v_JULY_v 2012-11-30 19:17发表 [回复]
-
- 回复Noadvanceistogoback:不是的,朋友,未读研未读硕。
- 63楼 CanaanShen 2012-11-25 12:15发表 [回复]
-

- 非常感谢,学习了,向楼主学习!~
- 62楼 我要学技术 2012-11-20 11:35发表 [回复]
-

- nice,还只到了第二层,补补数学再来升第三层!楼主给力!
- 61楼 hack_net 2012-11-06 20:04发表 [回复]
-

- 楼主,请问您构造的五维空间(2.2.1)中,五维空间中的五个维度并不是相互独立的,这样在五维向量运算时会不会有问题??
- 60楼 hack_net 2012-10-30 15:31发表 [回复]
-
-
如果wT不是单位法向量的话,那楼主您1.1的图中标示的,b为原点到超平面的距离是不是有问题???如果wT本身便是单位法向量那么,还用引入几何距离这个概念吗??
- Re: hack_net 2012-10-30 20:57发表 [回复]
-
-
回复shuaiccs:但是楼主您在1.1介绍中,图中标示的b,不就是距离吗???
- Re: v_JULY_v 2012-10-30 21:23发表 [回复]
-
-
回复shuaiccs:图1.1中的b 只是零点(0,0)到超平面的垂直距离,也就是所谓的截距,非具体的点(x,y) 到超平面的距离。
你可以再仔细看下原文第1.3节,或许能启示你。- Re: hack_net 2012-10-31 18:09发表 [回复]
-
- 回复v_JULY_v:谢谢楼主
- Re: v_JULY_v 2012-10-30 16:09发表 [回复]
-
- 回复shuaiccs:w是超平面的法向量,b是超平面的截距(注:这个截距,不等同于点到超平面的距离--几何间隔geometrical margin的概念)。
- 59楼 hack_net 2012-10-30 15:25发表 [回复]
-
- 楼主,请问1.1中的wTx+b = 0中wT是单位法向量吗???
- 58楼 小班得瑞 2012-10-23 11:04发表 [回复]
-

-
楼主您好,
又来打扰你了,呵呵。我对于SVMs中使用核函数技术如何加快训练过程这个地方还是不太明白。就拿你文中所说的2.2.2节那个从2维映射到5维的例子来说。如果不用核函数,先将x1,x2映射到5维,然后做内积。另一种是在原始二维平面直接计算。我看不出差别...
能不能举个非常intuitive的例子,谢谢!
感谢你看我的留言,祝你开心每一天~- Re: v_JULY_v 2012-10-23 11:23发表 [回复]
-
-
回复a130098300:"我们对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了五个维度;如果原始空间是三维,那么我们会得到 19 维的新空间,这个数目是呈爆炸性增长的,这给 的计算带来了非常大的困难,而且如果遇到无穷维的情况,就根本无从计算了。所以就需要 Kernel 出马了。"
"回忆刚才提到的映射的维度爆炸,在前一种方法已经无法计算的情况下,后一种方法却依旧能从容处理,甚至是无穷维度的情况也没有问题。
我们把这里的计算两个向量在隐式映射过后的空间中的内积的函数叫做核函数 (Kernel Function) "
现在,相信你已经明白如果不用核函数,先将x1,x2映射到5维,然后做内积的话,会出现维度爆炸,甚至无法计算的情况。
例子就是上文中的例子:“我们对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了五个维度;如果原始空间是三维,那么我们会得到 19 维的新空间,这个数目是呈爆炸性增长的,这给 的计算带来了非常大的困难,而且如果遇到无穷维的情况,就根本无从计算了”
你可以再仔细体会下核函数的意义!
- 57楼 linluyisb 2012-10-21 20:48发表 [回复]
-

- 把我一些没弄懂的地方,搞清楚了,感谢楼主。下次来推导一遍。
- 56楼 小班得瑞 2012-10-21 11:10发表 [回复]
-
-
楼主你好,
我想问一下,在用SVMs进行分类的时候,RBF核的参数确定有什么好的方法吗,如果有的话,请说一下,或者文章什么的- Re: v_JULY_v 2012-10-21 11:20发表 [回复]
-
-
回复a130098300:你看下这篇文章,看是否有无帮助:http://wenku.baidu.com/view/bcd74974f46527d3240ce038.html
- Re: 小班得瑞 2012-10-22 09:26发表 [回复]
-
- 回复v_JULY_v:非常感谢
- 55楼 奇异果 2012-10-20 13:33发表 [回复]
-

-
w是向量的话,||w||是向量的模吗?w=[4,5,6],则||w||=sqrt(4*4+5*5+6*6)
- Re: v_JULY_v 2012-10-20 13:50发表 [回复]
-
- 回复liukang0618:||w||表示的是范数,关于范数的概念参见:http://baike.baidu.com/view/637132.htm。
- 54楼 奇异果 2012-10-19 13:33发表 [回复]
-
-
1.3、函数间隔Functional margin与几何间隔Geometrical margin
一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。在超平面w*x+b=0确定的情况下,|w*x+b|能够相对的表示点x到距离超平面的远近。
这句不懂,为什么|w*x+b|能够相对的表示点x到距离超平面的远近?- Re: v_JULY_v 2012-10-20 09:55发表 [回复]
-
-
回复liukang0618:基本的点到平面的距离公式拉
- Re: 奇异果 2012-10-21 22:08发表 [回复]
-
-
回复v_JULY_v:点到直线的距离公式应该是分子|ax+by+c|分母sqrt(a方+b方) 嘛 只有分子一项我就不懂了。
- Re: v_JULY_v 2012-10-25 14:20发表 [回复]
-
-
回复liukang0618:引用文中原话回复你:
"正如本文评论下读者popol1991留言:函数间隔y*(wx+b)=y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量;而几何间隔|f(x)|/||w||才是直观上的点到超平面距离。
想想二维空间里的点到直线公式:假设一条直线的方程为ax+by+c=0,点P的坐标是(x0,y0),则点到直线距离为|ax0+by0+c|/sqrt(a^2+b^2)。 那么如果用向量表示,设w=(a,b),f(x)=wx+c,那么这个距离不正是|f(p)|/||w||么?"
- 53楼 Doubling 2012-10-17 06:27发表 [回复]
-

- 作为一个SVM入门,这个说的不错。不过证明SVM什么的还是换个说法吧。SMO不过是优化SVM QP目标函数的方法,和svm本身理论没啥关系。另外,关于kernel的讨论过于自信了,表示成kernel形式和用基函数phi本质上都一样,并不是说kernel就能避免phi函数造成的维度灾难。你对错误界的理解有点问题。还有,目前的状况是kernel虽然在数学上很elegant, 可是这个形式下根本不适合大规模数据。这就是为啥工业界这么多年都在做primal的原因。
- 52楼 y718739404 2012-10-10 12:43发表 [回复]
-

-
有一个问题没想明白,为什么引入松弛变量之后,目标函数要加入-∑ri εi?请博主解答!谢谢!
- Re: v_JULY_v 2012-10-10 22:47发表 [回复]
-
-
回复y718739404:原来的目标函数中并没有这一项,这一项是拉格朗日函数里面加的,
而之所以加入这一项是因为要求互补松弛变量大于等于零 。
- 51楼 少年行 2012-09-03 19:22发表 [回复]
-

- 多谢分享了!
- 50楼 beikeali 2012-08-25 11:50发表 [回复]
-

-
楼主,可以推荐几本文本分类的书吗?谢谢
- Re: v_JULY_v 2012-08-25 14:32发表 [回复]
-
- 回复beikeali:同第18楼回复:“这个系列第一篇和第二篇的参考文献”
- 49楼 xdyang 2012-08-24 13:58发表 [回复]
-

-
博主出个pdf版的吧
- Re: v_JULY_v 2012-08-24 15:05发表 [回复]
-
-
回复dcraw:哈,可以考虑
- Re: xdyang 2012-08-24 17:07发表 [回复]
-
-
回复v_JULY_v:期待中,pdf版的比网页版的看起来舒服多了
- Re: v_JULY_v 2012-08-24 17:27发表 [回复]
-
- 回复dcraw:EN,不过网页是适时更新的,且评论亦精彩O
- 48楼 victor0535 2012-08-24 01:58发表 [回复]
-
“如果原始空间是三维,那么我们会得到 19 维的新空间”
我算着怎么是29呢? 4的平方+3的平方+2的平方+1的平方-1=29
(x1+……+xn)的n次方 项数为: (n+1)的n-1方 + n的n-1方+ n-2的n-1方 +……- Re: victor0535 2012-08-24 02:48发表 [回复]
- 回复victor0535:我好像计算错了 呵呵
- 47楼 victor0535 2012-08-23 19:58发表 [回复]
-
“我们知道,训练样例一般是不会独立出现的,它们总是以成对样例的内积形式出现,而用对偶形式表示学习器的优势在为在该表示中可调参数的个数不依赖输入属性的个数,通过使用恰当的核函数来替代内积,可以隐式得将非线性的训练数据映射到高维空间,而不增加可调参数的个数(当然,前提是核函数能够计算对应着两个输入特征向量的内积)。”
0 ”在为“ 是不是 ”在于“ 啊?
1 “训练样例一般是不会独立出现的,它们总是以成对样例的内积形式出现” 是什么意思? 出现是指在“公式中”以内积形式出现吗? 还是现实中这样的样本成对出现?
2 这个 “对偶形式” 是什么意思? 是指你上次解释的”对偶问题“吗 还是指公式中内积的”成对“ 形式?
3 ”可调参数的个数不依赖输入属性的个数“ 可调参数 是指α吗? ”不依赖输入属性的个数“ 改成 ”不依赖 样本点的维数(即样本的特征数目)“ 更好些,是这个意思吧?
可调参数的数目,与维数无关,应与样本数有关吧,更准确说与支持向量的数目有关吧?- Re: v_JULY_v 2012-08-24 09:54发表 [回复]
-
-
回复victor0535:问题越多,代表你思考的越多,挺好的。
还有什么问题没?你先都提出来吧。
(若是一些概念性的问题可看看相关书籍,如本文参考文献里面的支持向量机导论一书)
- 46楼 victor0535 2012-08-23 12:55发表 [回复]
-
“ 使用拉格朗日定理解凸最优化问题可以使用一个对偶变量表示,用对偶问题表示之后,通常比原问题更容易处理,因为直接处理不等式约束是困难的。对偶问题通过引入又称为对偶变量的拉格朗日乘子来解。”
最后一句话,我怎么感觉不怎么通顺,不知道是什么意思?
另外,什么是对偶问题, 能给个准确有定义吗? 谢谢- Re: v_JULY_v 2012-08-23 13:59发表 [回复]
-
-
回复victor0535:1.改成这样,你就明白了:“对偶问题通过引入拉格朗日乘子(又称为对偶变量)来解”。
2.若一个模型为目标求极大 约束为小于等于的不等式,则它的对偶模型为目标求极小 约束为极大的不等式,即 “MAX,〈=” ,与 “MIN,〉=”相对应。- Re: victor0535 2012-08-23 19:41发表 [回复]
-
回复v_JULY_v:能不能麻烦再说明一下 原来的问题是什么? 转换成的对偶问题又是什么? 我还是没对应起来
再就是为什么要令 αi >=0 难道仅是为了让θ(w)=w2/2 ??
在用拉格朗日定理引入的系数 求极值时 , 是要对所有的变量一起求导数的(包括系数)………… 这个αi 可以随便给范围 不影响 L 函数 和 ||w|| 的极值吗? 理解很混乱啊我 谢谢- Re: victor0535 2012-08-23 20:05发表 [回复]
-
回复victor0535:我再补充一下我的问题, L=f(x,y)-λg(x,y) 求f的极值, 我记得课本里,是要对x , y λ 都求偏导的 求极值的 这样λ会能求出一个定值来吧, 为什么α可以人为的让它>=0 不影响我们最后求的结果吗?
- Re: v_JULY_v 2012-08-24 11:36发表 [回复]
-
-
回复victor0535:1.请看2.1节,“具体写出来,我们现在的目标函数变成了:
minw,bθ(w)=minw,bmaxαi≥0L(w,b,α)=p∗”,
这个P就是原形式,
而稍后给出的“maxαi≥0minw,bL(w,b,α)=d∗”,
这个d满足了KKT条件之后,便是对偶形式,
这样,对应起来了么?
2.对偶变量a为什么要>=0,你要先明白为什么要引入这个变量,请仔细看2.1节开头处,
"至于上述提到,关于什么是Lagrange duality,简单地来说,通过给每一个约束条件加上一个 Lagrange multiplier(拉格朗日乘值):α,我们可以将约束条件融和到目标函数里去(也就是说把条件融合到一个函数里头,现在只用一个函数表达式便能清楚的表达出我们的问题):
L(w,b,α)=12∥w∥2−∑i=1nαi(yi(wTxi+b)−1)
然后我们令
θ(w)=maxαi≥0L(w,b,α)"
而接下来,我们便要求L(w,b,a)的最小值,当然只能令这个对偶变量为非负了.
3."L=f(x,y)-λg(x,y) 求f的极值, 我记得课本里,是要对x , y λ 都求偏导的 求极值的 这样λ会能求出一个定值来."
本文不就是这么做的么?
"而求解这个对偶学习问题,分为两个步骤,首先要让L(w,b,a) 关于 w 和 b 最小化,然后求对α的极大。
(1)、要让 L 关于 w 和 b 最小化,我们分别对w,b求偏导数,即令 ∂L/∂w 和 ∂L/∂b 等于零(对w求导结果的解释请看本文评论下第45楼回复):"
(评论里无法编辑公式,所以公式无法正常显示,见谅)
- 45楼 victor0535 2012-08-23 12:08发表 [回复]
-
"(1)、要让 L 关于 w 和 b 最小化,我们分别对w,b求偏导数……“
对 1/2 ||w||2 求导 为什么是变成一个向量 w ??
是不是我哪个知识面欠缺? 谢谢- Re: v_JULY_v 2012-08-23 14:17发表 [回复]
-
-
回复victor0535:很简单的,L(w,b,a)对w求偏导,∂L/∂w = w - ∑αiyixi(i=1...n) = 0,故推出w=∑αiyixi(i=1...n)= 0。
- Re: v_JULY_v 2012-08-23 14:54发表 [回复]
-
-
回复v_JULY_v:白石补充说明:为什么 对 1/2||w||^2 求偏导之后,是 w,而不是 ||w||?
1.简单的,设w=(w1,w2),x1=(1,2),y1=-1,则\\W\\^2=w1^2+w2^2,w *x1=w1+2*w2
L=1/2(||w||^2)-a1(y1(w*x1)=1/2(w1^2+w2^2)+a1(w1+2*w2)
将L对w1求偏导得到
w1+a1=0
对w2求偏导得到
w2+2a2=0
合在一起就是(w1,w2)+a1(1,2)=0,而这个不就是w-a1*y1*x1=0
2.比如,w=(x,y,z),
1/2 ||w||^2=1/2(x^2+y^2+z^2),对w求导就是分别对x,y,z求导,对x求得的偏导等于x,对y的等于y,对z的等于z。这三个放在一起就是一个向量,(x,y,z) ,一个多元函数,对各个变量求偏导,得到的不是一个数,而只能是一个向量。这个向量的各分分量就是对应的偏导数。
- 44楼 zlj4700 2012-08-21 20:09发表 [回复]
-

-
楼主好,这个帖子看已经看了好多遍了,受益匪浅。理论上是明白了,但实际的问题好像不容易解决,例如,在不清楚自变量(10个)与因变量具体关系的情况下得到了100组数据样本,想通过随机选取90组做训练样本,利用支持向量机对剩余的10组数据进行预测,结果每次运行都发现误差都很大,请问支持向量机的训练样本有什么选择的原则吗?
- Re: v_JULY_v 2012-08-21 21:20发表 [回复]
-
-
回复zlj4700:实际中,算法是服务于应用的,而不是去让样本去适应算法,每一个算法都有各自应用的场景和优势,建议针对样本的特点选择合适的算法。
同时,提醒下你,对于SVM来说,超平面之间的距离越大,分离器的推广能力越好,也就是预测精度越高,但对于训练数据的误差不一定能有效缩小。
所以,总而言之,还是需要看你样本的特点及反复实践多种算法,以比较甄选。- Re: zlj4700 2012-08-21 22:28发表 [回复]
-
-
回复v_JULY_v:不知道这样考虑对不对,根据经验,尽量选择能表现因变量特性的典型数据,避免大量相似,重复的数据做样本(因为重复近似的样本太多的话就算再怎么随机,得到的模型泛化能力都不会好)。有一个实例,需要用模型来做预测,用BP试过效果也不好,数据容易获得,可能关键是样本的选择。
- Re: v_JULY_v 2012-08-21 23:01发表 [回复]
-
- 回复zlj4700:sorry,之前看错了,你的意思是要:通过随机选取90组做训练样本训练你的支持向量机模型,然后利用其对剩余的10组数据进行预测,那么,便正如你所说,关键在于训练样本的选取(质量,及合适与否)。若你发现了别的好的经验,欢迎回馈给我。
- 43楼 v_JULY_v 2012-08-21 18:49发表 [回复]
-
-
读者答疑
有一个问题必须阐述下,在本文1.2节中,有:“接着,我们可以令分类函数
f(x)=wTx+b ,
显然,如果 f(x)=0 ,那么 x 是位于超平面上的点。我们不妨要求对于所有满足 f(x)<0 的点,其对应的 y 等于 -1 ,而 f(x)>0 则对应 y=1 的数据点。”
有一朋友飞狗来自Mare_Desiderii,看了上面的定义之后,问道:请教一下SVM functional margin 为 γˆ=y(wTx+b)=yf(x)中的Y是只取1和-1 吗?y的唯一作用就是确保functional margin的非负性?
与白石讨论后,我来具体回答下这个问题:你把问题搞混了。y是个分类标签,二分时y就取两个值,而刚好取了-1和1,只是因为用超平面分类时,不同的类中的点函数值刚好有不同的符号,所以就用符号来进行分类。
具体阐述如下:1.对于二类问题,因为y只取两个值,这两个是可以任意取的,只要是取两个值就行;2.支持向量机去求解二类问题,目标是求一个特征空间的超平面,而超平面分开的两类对应于超平面的函数值的符号是刚好相反的;3.基于上述两种考虑,为了使问题足够简单,我们取y的值为1和-1;4.在取定分类标签y为-1和1之后,那么,一个平面正确分类样本数据,就相当于用这个平面计算的那个y*f(x)>0; 5、而且这样一来,y*f(x)有明确的几何含义;
总而言之:你要明白,二类问题的标签y是可以取任意两个值的,不管取怎样的值对于相同的样本点,只要分类相同,所有的y的不同取值都是等价的,之所以取某些特殊的值,只是因为这样一来计算会变得方便,理解变得容易。
正如朋友张磊所言,svm中y取1或-1的历史原因是因为感知器最初的定义,实际取值可以任意,总能明确表示输入样本是否被误分,但是用+1、-1可以起码可以是问题描述简单化、式子表示简洁化、几何意义明确化。
举个例子,如你要是取y为1和2,比如原来取-1的现在取1,原来取1的现在取2 , 这样一来,分类正确的判定标准变为(y-1.5)*f(X)>0 , 故取1和-1只是为了计算简单方便,没有实质变化,更非一定必须取一正一负。
- 42楼 victor0535 2012-08-21 11:04发表 [回复]
-
“我们可以令 γˆ=1 (对目标函数的优化没有影响) ” 为什么没有影响 这么做的依据是什么?
问了好多人(包括在你群里),也看了网上别的资料,都是一笔代过,我自己也思考了很久 始终不明白 f(x)/||W|| 他子里也包含了向量W 并且是哪个点最近也不知道 怎么可能没有影响呢??
在我们平时就一个简单函数时 f(x)/||x|| 分子分母都包含 一个变量 怎么可以为了“求的方便” 就反分子变成1呢?? 不理解!!
应该怎么解释? 能给个让人信服的解释吗?? 还是有漏洞? 谢谢!!- Re: v_JULY_v 2012-08-21 16:18发表 [回复]
-
-
回复victor0535:1.对于一个线性可分问题,任意给定一个分类正确的超平面,都有一个最小函数间隔,为了方便书写,记做r^,这个r^,是方向向量w和截距b的函数,因为分类的点是给定的;
2.也就是说r~=r^ (w,b),而求最大几何间隔的问题就是要求出一组w,b使得r^ /||w||,最大。此时约束的条件是任意给定的一个点的函数间隔大于等于r^,也就是yi(w xi+b)>=r^ ;
3.下面做一个变量替换,用w’ = w/r^,和b' = b/r^代替上面的w和b,这样的新变量仍旧是w和b的函数,所以最大化仍然可以进行。于是,把这两个新的变量代入到原来的约束最大化问题中,就变成了,在yi(w' xi+b')>=1的条件下,求使得1/||w'||最大化的w,b。
4.这样一来,通过一个变量替换,关于w和b的问题等价地换成了w',b' 的问题,这就是支持向量机所采用的形式。- Re: v_JULY_v 2012-08-21 16:23发表 [回复]
-
-
回复v_JULY_v:关于第3点补充说明两个问题:
3.1.
问:为什么要做那两个变换,"下面做一个变量替换,用w’ = w/r^,和b' = b/r^代替上面的w和b,".
答:为了让读者能够看得更明白,才做的这样的变换。不然,大可以直接说因为函数间隔可以任意伸缩,因此将最小函数间隔任意扩大或者缩小一定倍数是不影响问题的,从而可以直接令最小值为1 .
3.2
问:关于第3点中的"1"是怎么来的?
答:yi(w xi+b)>=r^这个条件是任意求解的时候需要满足的,换个元,令w'= w/r^,和b' = b/r^,也就是w=w'r^,b=b'r^代入上面的式子,不就出来yi(w' xi+b')>=1 了么?
(多谢白石指导)- Re: v_JULY_v 2012-08-22 10:26发表 [回复]
-
- 回复v_JULY_v:3.1中所谓的等量变换:"下面做一个变量替换,用w’ = w/r^,和b' = b/r^代替上面的w和b,",其实不过是在不等式的两边同时除以一个因子:r^(当然,这个因子是 > 0的)。即:yi(w xi+b)>=r^ =》 yi(w/r^ xi+b/r^)>=r^/r^,而得到yi(w' xi+b')>=1。
- Re: victor0535 2012-08-21 23:39发表 [回复]
-
回复v_JULY_v:解释的很好,非常感谢,谢谢!! 这次算是彻底明白了。 呵呵
但我想再替你补充一下 , 要想说明替换后问题等价,还有一点要说明 即原来的 ~r=^r / ||w|| 也能替换过去才算等价—— ~r=^r / ||w|| =1 / (||w|| /^r) =1/ ||w /^r|| =1/||w'|| ——这样就相当于原问题只是换了下字母而已了 彻底造价了
希望能以后多跟你请教 探讨学习~~~~~
另外,也叹服群主的回帖速度和研究的认真程度- Re: v_JULY_v 2012-08-22 10:24发表 [回复]
-
-
回复victor0535:Good Job!
共同学习。:-)
- 41楼 victor0535 2012-08-21 10:55发表 [回复]
-
" 当然,还需要满足一些条件,根据 margin 的定义,我们有
yi(wTxi+b)=γˆi≥γˆ,i=1,…,n
其中 γˆ=γ˜∥w∥ ,处于方便推导和优化的目的,我们可以令 γˆ=1 (对目标函数的优化没有影响) ,此时, "
中的 γˆ=γ˜∥w∥ γˆ 与 γ˜是不是写反了??- Re: v_JULY_v 2012-08-21 11:30发表 [回复]
-
- 回复victor0535:没有写反,原式 γˆ=γ˜∥w∥,等价于 γ˜ = γˆ / ∥w∥,当令γˆ =1 时, γ˜ = 1 / ||w||
- 40楼 beikeali 2012-08-20 09:57发表 [回复]
-
-
博主,非支持向量的a等于零,那支持向量的a如何呢?有对应的证明过程吗?
- Re: v_JULY_v 2012-08-20 11:13发表 [回复]
-
- 回复beikeali:同第21楼回复:“是的,SMO-序列最小最优化算法,在本文文末的参考文献及推荐阅读的条目9:统计学习方法,李航著中的第7章,7.4节内有较详细的介绍。这上面,提到了关于a的求解”。
- 39楼 v_JULY_v 2012-08-09 00:33发表 [回复]
-
- 本文最后分享了几个近期还算不错的3个资源的0积分下载地址。
- 38楼 shiyuzh2007 2012-08-08 18:50发表 [回复]
-

- 太牛,期待更多好文!持续关注!
- 37楼 LI84806367 2012-08-06 20:31发表 [回复]
-

- 1
- 36楼 agilezing 2012-08-05 23:02发表 [回复]
-

-
太谦虚了,我就在Machine Learning & Data Minin 这个群里,上次你组织的nlp学习,我还参加了,就是坐在你身边的那位,没来得及请教,惭愧,svm的源程序你实现过了吗?
- Re: v_JULY_v 2012-08-05 23:07发表 [回复]
-
- 回复agilezing:奥,呵呵。最近工作实在忙,以后有机会再实现,:-)
- 35楼 agilezing 2012-08-05 20:29发表 [回复]
-
-
我是你群里的,见过作者你,真是厉害。
- Re: v_JULY_v 2012-08-05 20:55发表 [回复]
-
-
回复agilezing:抬举了。你是哪个群的,在哪见过我? :-)
- Re: real007fei 2013-03-21 17:02发表 [回复]
-
- 回复v_JULY_v:楼主,核函数那里的网页显示都是乱码,换了四五个浏览器都不行,您方便提供下文章的pdf版本吗?非常感谢
- 34楼 agilezing 2012-08-05 20:29发表 [回复]
-
- 很强大,非常强大,我数学基础不好,很羡慕作者啊。
- 33楼 citylove 2012-08-03 09:23发表 [回复]
-

- 好文章,先收藏~~~
- 32楼 v_JULY_v 2012-07-31 23:10发表 [回复]
-
- OK,断断续续,历时近两个月,本文终于基本成型了,哈哈
- 31楼 Rachel-Zhang 2012-07-29 19:19发表 [回复]
-

-
受益匪浅,热切等待neuron network的篇章,看andrew的讲解感觉稍微有点儿乱……
- Re: v_JULY_v 2012-07-29 21:41发表 [回复]
-
-
回复abcjennifer:谢谢,我之前到你blog内看过。EN,尽量早日动笔写network。原谅我的见识浅陋,andrew是?
- Re: Rachel-Zhang 2012-07-30 08:37发表 [回复]
-
-
回复v_JULY_v:Andrew Ng是斯坦福教ML的老师,今年很火的16000台机器进行无监督学习完成识别就是他做的,我在他的公开课上学的ML,感觉neuron network的知识架构比较清楚,但是讲的不够细,我的blog里也谢了一些课程追踪的东西,看到你这里很有条理,希望你能写出更详细的内容,期待!(*^__^*)
- Re: v_JULY_v 2012-07-30 11:43发表 [回复]
-
- 回复abcjennifer:我这写得还很糙,EN,好的,谢谢
- 30楼 zlj4700 2012-07-24 23:45发表 [回复]
-
- 谁清楚,请讲一下吧,谢谢了
- 29楼 xzw_123 2012-07-24 15:45发表 [回复]
-

- 明了易懂,非常感谢LZ
- 28楼 zlj4700 2012-07-23 22:44发表 [回复]
-
- 看了一晚上 很不错
- 27楼 zlj4700 2012-07-23 22:44发表 [回复]
-
-
请教楼主 2.2.2 最后一个2个X1,X2的内积映射是怎么得到的?
- Re: v_JULY_v 2012-08-02 21:36发表 [回复]
-
-
回复zlj4700:第一个算式,就是那个带内积的完全平方式,可以拆开
然后,凑一个就行
第二个算式,是根据第一个算式凑出来的- Re: zlj4700 2012-08-21 19:59发表 [回复]
-
- 回复v_JULY_v:非常感谢楼主 看明白了
- 26楼 v_JULY_v 2012-07-19 19:28发表 [回复]
-
- 由于文章篇幅长,做了个目录,以为阅读方便
- 25楼 randomnet 2012-07-18 20:02发表 [回复]
-

- 拜读
- 24楼 popol1991 2012-07-18 15:29发表 [回复]
-

-
讲函数间隔与几何间隔那里有个小问题。
July你说函数间隔就是直观上点到超平面的距离是不对的,实际上几何间隔才是。
函数间隔y*(wx+b)=y*f(x)实际上就是|f(x)|,只是人为定义的一个间隔度量;而几何间隔|f(x)|/||w||才是直观上的点到超平面距离。
想想二维空间里的点到直线公式:假设一条直线的方程为ax+by+c=0,点P的坐标是(x0,y0),则点到直线距离为|ax0+by0+c|/sqrt(a^2+b^2)。 那么如果用向量表示,设w=(a,b),f(x)=wx+c,那么这个距离不正是|f(p)|/||w||么~- Re: v_JULY_v 2012-07-19 13:37发表 [回复]
-
- 回复popol1991:嗯,是的,感谢指正,修订到原文之中,再次谢谢你
- 23楼 broler 2012-07-17 20:45发表 [回复]
-

-
svm啊。。。又爱又恨。。。。。
- Re: v_JULY_v 2012-07-18 07:05发表 [回复]
-
- 回复ljy1988123:何爱何恨?
- 22楼 broler 2012-07-11 15:09发表 [回复]
-
- 和某楼同意见,严重希望博主读研读博。真心的。不读太可惜了。
- 21楼 xuanhun 2012-07-11 15:06发表 [回复]
-

-
我今天看到资料好像是有个SMO的方法 回复v_JULY_v:
- Re: v_JULY_v 2012-07-11 15:23发表 [回复]
-
- 回复xuanhun:是的,SMO-序列最小最优化算法,在本文文末的参考文献及推荐阅读的条目9:统计学习方法,李航著中的第7章,7.4节内有较详细的介绍。这上面,提到了关于a的求解。
- 20楼 baily1 2012-07-10 20:30发表 [回复]
-

- 转换成求maxL(w,b,α)后怎么求α的值呢
- 19楼 xdyang 2012-06-29 10:20发表 [回复]
-
-
个人觉得博主应该去读个研,然后硕博连读,5年把博士读出来。这么年轻,这么喜欢算法,不读博士可惜了。
- Re: v_JULY_v 2012-06-30 23:46发表 [回复]
-
- 回复dcraw:-_-
- 18楼 iii_9 2012-06-27 04:19发表 [回复]
-

-
博主,我关注你的博客很久了,最近放假,准备系统研究下machine learning。你有什么推荐的书吗?我正在看PRML,但感觉过于理论,看起来也费尽。《AI,a modern approach》似乎不错,但还没看,你觉得呢?
- Re: v_JULY_v 2012-06-29 00:34发表 [回复]
-
- 回复iii_9:这个系列第一篇和第二篇的参考文献
- 17楼 v_JULY_v 2012-06-18 16:14发表 [回复]
-
- http://www.cnblogs.com/jerrylead/archive/2012/05/08/2489725.html
- 16楼 wmlong1988 2012-06-12 15:33发表 [回复]
-

-
我提一个意见,公式可以用公式编辑器写了再发上来 :)
- Re: v_JULY_v 2012-06-13 13:21发表 [回复]
-
- 回复wmlong1988:EN,下次注意
- 15楼 steel_de_lee 2012-06-12 12:55发表 [回复]
-

-
刚浏览了英国人写的那本《支持向量机》,也下了libSVM代码看了看,感觉LZ的“通俗导论”立意还可以,只是这个东东离大部分程序员的实际需求还是太远了,如果从纯研究角度来看很不错,实际使用上就有些“卖弄”了,不如讨论一下更简单的最小二乘理论什么的更实际。
- Re: v_JULY_v 2012-06-12 13:09发表 [回复]
-
-
回复steel_de_lee:好,后续更新中,讨论下最小二乘的理论,-_-
- Re: 第二不及 2012-07-15 14:42发表 [回复]
-

-
回复v_JULY_v:看到这里就笑喷了
- Re: v_JULY_v 2012-07-15 17:15发表 [回复]
-
- 回复twowind:哦,就算是装傻充嫩博君一笑也来尝不可,呵呵
- 14楼 wanggp_2007 2012-06-12 11:27发表 [回复]
-

- 期待中...
- 13楼 beikeali 2012-06-08 09:38发表 [回复]
-
-
不妨还是从最开始的简单例子出发,设两个向量 和 ,而 即是到前面说的五维空间的映射,因此映射过后的内积为:
博主:
这里没咋看懂,能不能给个细点的推导过程,为啥那两是一样的。另外,我们又注意到:
二者有很多相似的地方,实际上,我们只要把某几个维度线性缩放一下,然后再加上一个常数维度,具体来说,上面这个式子的计算结果实际上和映射
之后的内积 的结果是相等的(自己验算一下)。区别在于什么地方呢?- Re: v_JULY_v 2012-06-08 10:36发表 [回复]
-
- 回复beikeali:好的,今晚我把推导过程写上去。谢谢你的建议
- Re: beikeali 2012-06-08 09:41发表 [回复]
-
-
回复beikeali:这个地方的公式没有看懂,是如何带入的,博主~
- Re: v_JULY_v 2012-06-08 23:45发表 [回复]
-
-
回复beikeali:回来晚了,再给我一两天时间,打算把其它公式也要好好说明下
- Re: beikeali 2012-06-09 08:15发表 [回复]
-
-
回复v_JULY_v:ok,楼主很守信,昨天等着看你的来的,看到你去听讲座了,期待你的更新!
- Re: v_JULY_v 2012-06-10 00:52发表 [回复]
-
- 回复beikeali:sorry,由于csdn blog的烂系统,文章一直无法修改。你说的那两个推导过程中,前面说的五维空间的映射,这里指的前面便是文中2.2.1节的所述的映射方式,你再仔细看下它的映射规则,再看那第一个推导,其实就是计算x1,x2各自的内积,然后相乘相加即可,第二个推导则是直接平方,去掉括号,也很容易推出来。
- 12楼 javalhl 2012-06-06 20:52发表 [回复]
-

-
这篇文章解了我几个疑问,但是数学公式太多了,难看懂
- Re: v_JULY_v 2012-06-06 22:35发表 [回复]
-
- 回复javalhl:买看懂的几个公式可以提出来,后续会慢慢增加阐释
- 11楼 cjboy1984 2012-06-06 16:53发表 [回复]
-

-
一个优秀的程序员,是多么的难,懂数学,懂医学,.....凡是电子的东西,都是我们设计实现的,医生只是看看仪器,从而得出结论..有时却发现,我们程序员的付出与回报,差的太元了!!!哪些官二代,富二代,会鸡毛...但是却便用着,我们造出来的东西...
- Re: quanben 2012-07-30 14:32发表 [回复]
-

- 回复cjboy1984:.... 这是个难题。
- Re: v_JULY_v 2012-06-06 22:34发表 [回复]
-
- 回复cjboy1984:EN,是事实
- 10楼 晚安苏州 2012-06-06 16:42发表 [回复]
-

- 额,记得当时的毕业论文做的也是这个SVM,差点没过…
- 9楼 扯淡 2012-06-06 15:14发表 [回复]
-

- 好文章,已收藏,期待下文。 感谢作者!
- 8楼 beikeali 2012-06-06 13:51发表 [回复]
-
- 期待下面的内容!
- 7楼 郗晓勇 2012-06-05 20:23发表 [回复]
-

- 支持!
- 6楼 hellmonky 2012-06-03 21:24发表 [回复]
-

- 很不错的文章,支持!
- 5楼 zhzhl202 2012-06-03 21:06发表 [回复]
-

-
真心希望作者很认真看看Pluskid的文章和Jasper写的SVM入门,这些都是关于SVM写的非常好的系列,如果再能看看libsvm和svmlight的源码,理论和实践结合起来就非常好了。
- Re: v_JULY_v 2012-06-03 21:13发表 [回复]
-
- 回复zhzhl202:EN,一定会的,等我写完,相信我