FPGA实现图像的空间滤波—Shit Register实现滤波模版
FPGA实现图像的空间滤波——Shit Register实现滤波模版
空间滤波是一种采用滤波处理的影像增强方法。其理论基础是空间卷积和空间相关。目的是改善影像质量,包括去除高频噪声与干扰,及影像边缘增强、线性增强以及去模糊等。分为低通滤波(平滑化)、高通滤波(锐化)和带通滤波。处理方法有计算机处理(数字滤波)和光学信息处理两种。
实现空间滤波的关键在于生成3x3或者其他的滤波模版。QII中有ip可以帮助我们实现3x3的阵列模版,下面我们来主要介绍IP核,Shift_RAM的使用方法,和生成滤波模版的仿真。
Shit Register使用方法
关于Shit Register的认识,首先可以从英文名字看出它就是一个移位寄存器,不过它可以实现行的移位,我们就是用它的这个特点实现3x3的阵列。具体关于IP核的介绍可以查看官方给的datasheet,里面的讲解很详细,举例也很明确。下面我简单介绍下它的用法。
官方数据手册链接: Shit Register.

第一个空白数字的含义是表示数据输入和输出的位宽,第二个表示是否生成行输出,和设置行输出的行数,第三个表示给一行的数据深度有多少。下面是生成一个时钟使能信号,生成一个清除信号了,选择生成RAM所使用的类型。
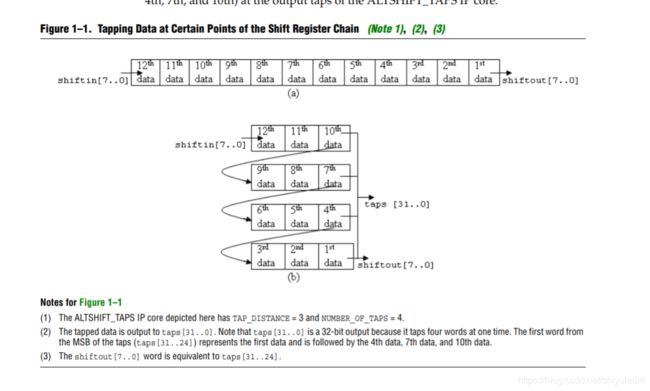
设置完参数后,对ip核使用要了解它工作的原理,才能使用的得心应手。从图示中可以看出来数据从shiftin进入然后从shiftout移出,在某行上的数据是由上一行的数据移下来的,每一行的第一个数据可以作为这一行的输出。下面我们来举一个简单的例子帮助我们理解。假设图像大小为3x4,
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 |
则它的第一个3x3矩阵输出应该是
| 1 | 2 | 3 |
|---|---|---|
| 5 | 6 | 7 |
| 9 | 10 | 11 |
我么设置的IP核参数为,每行4个数据一共两行,
当数据进入时
| 1 | |||
|---|---|---|---|
| 2 | 1 | ||
|---|---|---|---|
| 4 | 3 | 2 | 1 |
|---|---|---|---|
这时第一行会输出数据1,然后数据换行
| 5 | 4 | 3 | 2 |
|---|---|---|---|
| 1 |
| 8 | 7 | 6 | 5 |
|---|---|---|---|
| 4 | 3 | 2 | 1 |
这时第一行输出为5第二行输出为1。通过上面举例已经对它的工作模式有了清楚的认识。将输入的数据看做第三行,这时当第一行输出为5第二行输出为1,输入的数据应该是9。不难看出1,5,9正是滤波模版的第一列数据。
| 9 | 8 | 7 | 6 |
|---|---|---|---|
| 5 | 4 | 3 | 2 |
下个时钟三行输出的位2,6,10。然后再过一个时钟输出的为3,7,11。把这数据存到定义的3x3的存储单元中就构成的滤波模版。下面给出仿真的Verilog代码和防真图。
module shift_ram
(
//global clock
input clk, //cmos video pixel clock
input rst_n, //global reset
//Image data prepred to be processd
// input per_frame_vsync, //Prepared Image data vsync valid signal
// input per_frame_href, //Prepared Image data href vaild signal
// input per_frame_clken, //Prepared Image data output/capture enable clock
input [7:0] per_img_Y, //Prepared Image brightness input
//Image data has been processd
// output matrix_frame_vsync, //Prepared Image data vsync valid signal
// output matrix_frame_href, //Prepared Image data href vaild signal
// output matrix_frame_clken, //Prepared Image data output/capture enable clock
// output reg [7:0] matrix_p11, matrix_p12, matrix_p13, //3X3 Matrix output
// output reg [7:0] matrix_p21, matrix_p22, matrix_p23,
// output reg [7:0] matrix_p31, matrix_p32, matrix_p33
output [7:0] row2_data,row1_data,
output [23:0] matrix_row1,
output [23:0] matrix_row2,
output [23:0] matrix_row3
);
//Generate 3*3 matrix
//--------------------------------------------------------------------------
//--------------------------------------------------------------------------
//--------------------------------------------------------------------------
//sync row3_data with per_frame_clken & row1_data & raw2_data
//wire [7:0] row1_data; //frame data of the 1th row
//wire [7:0] row2_data; //frame data of the 2th row
reg [7:0] row3_data; //frame data of the 3th row
reg per_frame_vsync=1'd1;
reg per_frame_href=1'd1;
reg per_frame_clken=1'd1;
reg [7:0] matrix_p11,matrix_p12,matrix_p13,matrix_p21,matrix_p22,matrix_p23,matrix_p31,matrix_p32,matrix_p33;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
row3_data <= 0;
else
begin
if(per_frame_clken)
row3_data <= per_img_Y;
else
row3_data <= row3_data;
end
end
//---------------------------------------
//module of shift ram for raw data
wire shift_clk_en = per_frame_clken;
Line_Shift_RAM_8Bit u_Line_Shift_RAM_8Bit
(
.clock (clk),
.clken (shift_clk_en), //pixel enable clock
// .aclr (1'b0),
.shiftin (row3_data), //Current data input
.taps0x (row2_data), //Last row data
.taps1x (row1_data), //Up a row data
.shiftout ()
);
//------------------------------------------
//lag 2 clocks signal sync
reg [1:0] per_frame_vsync_r;
reg [1:0] per_frame_href_r;
reg [1:0] per_frame_clken_r;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
per_frame_vsync_r <= 0;
per_frame_href_r <= 0;
per_frame_clken_r <= 0;
end
else
begin
per_frame_vsync_r <= {per_frame_vsync_r[0], per_frame_vsync};
per_frame_href_r <= {per_frame_href_r[0], per_frame_href};
per_frame_clken_r <= {per_frame_clken_r[0], per_frame_clken};
end
end
//Give up the 1th and 2th row edge data caculate for simple process
//Give up the 1th and 2th point of 1 line for simple process
wire read_frame_href = per_frame_href_r[0]; //RAM read href sync signal
wire read_frame_clken = per_frame_clken_r[0]; //RAM read enable
//assign matrix_frame_vsync = per_frame_vsync_r[1];
//assign matrix_frame_href = per_frame_href_r[1];
//assign matrix_frame_clken = per_frame_clken_r[1];
//----------------------------------------------------------------------------
//----------------------------------------------------------------------------
/******************************************************************************
---------- Convert Matrix ----------
[ P31 -> P32 -> P33 -> ] ---> [ P11 P12 P13 ]
[ P21 -> P22 -> P23 -> ] ---> [ P21 P22 P23 ]
[ P11 -> P12 -> P11 -> ] ---> [ P31 P32 P33 ]
******************************************************************************/
//---------------------------------------------------------------------------
//---------------------------------------------------
/***********************************************
(1) Read data from Shift_RAM
(2) Caculate the Sobel
(3) Steady data after Sobel generate
************************************************/
assign matrix_row1 = {matrix_p11, matrix_p12, matrix_p13}; //Just for test
assign matrix_row2 = {matrix_p21, matrix_p22, matrix_p23};
assign matrix_row3 = {matrix_p31, matrix_p32, matrix_p33};
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'h0;
end
else if(read_frame_href)
begin
if(read_frame_clken) //Shift_RAM data read clock enable
begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data}; //1th shift input
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data}; //2th shift input
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data}; //3th shift input
end
else
begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
else
begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'h0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'h0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'h0;
end
end
endmodule
//仿真
`timescale 1 ns/ 1 ps
`define PERIOD_CLk 20
module shift_ram_vlg_tst();
// test vector input registers
reg clk;
reg [7:0] per_img_Y;
reg rst_n;
// wires
wire [23:0] matrix_row1;
wire [23:0] matrix_row2;
wire [23:0] matrix_row3;
wire [7:0] row2_data;
wire [7:0] row1_data;
// assign statements (if any)
shift_ram i1 (
// port map - connection between master ports and signals/registers
.clk(clk),
.matrix_row1(matrix_row1),
.matrix_row2(matrix_row2),
.matrix_row3(matrix_row3),
.row2_data(row2_data),
.row1_data(row1_data),
.per_img_Y(per_img_Y),
.rst_n(rst_n)
);
initial
begin
clk = 1'b0;
rst_n = 1'b0;
#(`PERIOD_CLk*20);
rst_n = 1'b1;
#(`PERIOD_CLk*20);
$stop;
end
always #(`PERIOD_CLk/2) clk = ~clk;
//always @(posedge clk oe negedge rst_n )begin
// if(!rst_n)
// clken <= 1'd0;
// else
// clken <= ~clken;
//
//
//end
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
per_img_Y <= 7'd0;
end
else begin
if(per_img_Y == 7'd12)
per_img_Y <= 7'd0;
else
per_img_Y <= per_img_Y + 10'd1;
end
end
endmodule
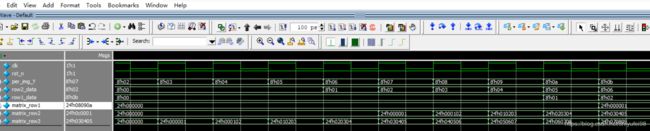 从仿真图上可以看出输入的数据要比输出数据提前一个时钟周期,所以要把输入当做第三行数据,要将输入数据先缓存一个时钟周期。
从仿真图上可以看出输入的数据要比输出数据提前一个时钟周期,所以要把输入当做第三行数据,要将输入数据先缓存一个时钟周期。
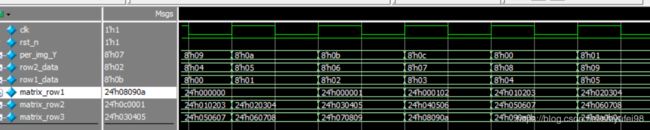
通过观察仿真图可以得出与我们推测的结果一致。但是这种方法进行滤波对第一行和最后一行的数据是没有进行滤波的。
本文引用了其他文章资料,如有侵权,联系本人会做出修改。版本1.0,2019.10.9 作者小飞。