目标检测 | Facebook开源新思路!DETR:用Transformers来进行端到端的目标检测
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

论文地址:https://arxiv.org/pdf/2005.12872.pdf
代码地址:https://github.com/facebookresearch/detr
本文已提交至ECCV 2020,作者团队:Facebook AI Research。FAIR提出DETR:基于Transformers的端到端目标检测,没有NMS后处理步骤、真正的没有anchor,直接对标且超越Faster R-CNN,代码刚刚开源!
简介
本文提出了一种将目标检测视为direct set直接集合预测问题的新方法。我们的方法简化了检测流程,有效地消除了对许多手工设计的组件的需求,例如非最大抑制程序或锚点生成,这些组件明确编码了我们对任务的先验知识。
这种称为Detection Transformer或DETR的新框架的主要组成部分是基于集合的全局损失函数,该损失函数通过二分匹配和transformer编码器-解码器体系结构强制进行唯一的预测。给定一个固定的学习对象查询的小集合,DETR会考虑目标对象与全局图像上下文之间的关系,并直接并行输出最终的预测集合。
与许多其他现代检测器不同,新模型在概念上很简单,并且不需要专门的库。DETR与具有挑战性的COCO对象检测数据集上公认的且高度优化的Faster R-CNN baseline具有同等的准确性和运行时性能。此外,可以很容易地将DETR迁移到其他任务例如全景分割。
本文的Detection Transformer(DETR,请参见图1)可以预测所有物体的剧烈运动,并通过设置损失函数进行端到端训练,该函数可以在预测的物体与地面真实物体之间进行二分匹配。DETR通过删除多个手工设计的后处理过程例如nms,对先验知识进行编码的组件来简化检测流程。与大多数现有的检测方法不同,DETR不需要任何自定义层,因此可以在包含标准CNN和转换器类的任何框架中轻松复制。
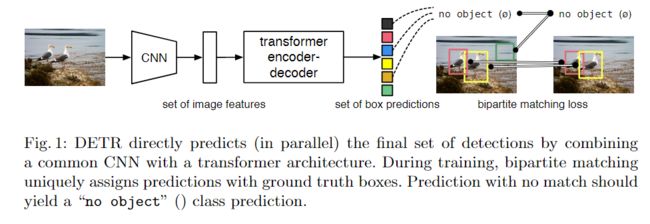
DETR的主要特征是二分匹配损失和具有(非自回归)并行解码的Transformer的结合。
Transformer
Transformer是一种用于序列预测的流行架构。Transformer的自注意力机制可显式地模拟序列中元素之间的所有成对相互作用,从而使这些体系结构特别适用于集合预测的特定约束,例如删除重复的预测。
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入。
在Transformer的encoder中,数据首先会经过一个叫做‘self-attention’的模块得到一个加权之后的特征向量 ,这个 便是论文公式1中的 :
得到 之后,它会被送到encoder的下一个模块,即Feed Forward Neural Network。这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
Decoder的结构如下图所示,它和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:
1、Self-Attention:当前和前文之间的关系;
2、Encoder-Decnoder Attention:当前和编码的特征向量之间的关系。
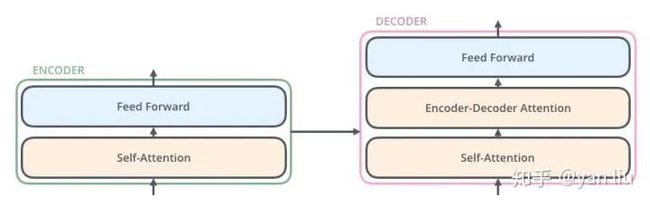 Transformer的解码器由self-attention,encoder-decoder attention以及FFNN组成
Transformer的解码器由self-attention,encoder-decoder attention以及FFNN组成
本文方法:DETR具体结构
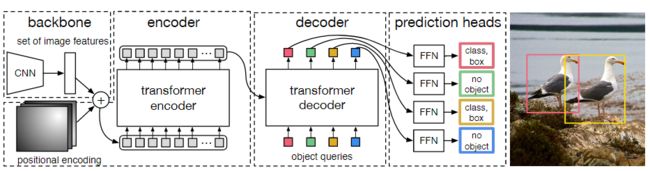
图2:DETR使用常规的CNN主干来学习输入图像的2D表示。模型将其展平并在将其传递到Transformer的编码器之前对其进行位置编码补充。然后,Transformer的解码器将固定数量的学习到的位置嵌入作为输入,我们将其称为目标对象查询,并另外参与编码器的输出。我们将解码器的每个输出嵌入传递到预测检测(类和边界框)或“无对象”类的共享前馈网络(FFN)。
本文提出的网络如上图所示,它包含三个主要组件,提取紧凑特征表示的CNN主干网络,编码器-解码器Transformer结构和形成最终结构的简单前馈网络(FFN)检测网络。
1、backbone:通常将通道数设为2048,下采样到分辨率为1/32。
2.1、Transformer encoder:首先,1x1卷积将高级特征图f的通道维从C减小到较小的维,并创建一个新的特征图z0。编码器需要一个序列作为输入,因此将z0的空间尺寸折叠为一个尺寸,从而生成一个d×HW特征图。每个编码器层均具有标准架构,并由多头自注意模块(Multi-head attention layers)和前馈网络(FFN)组成。
由于Transformer体系结构是置换不变的,因此我们将其添加有固定位置编码,该编码被添加到每个关注层的输入中。
Multi-head attention layers:多头注意力仅是单个注意力头的串联,后跟带有L的映射。常见做法是使用残差连接,dropout和layer normalization。
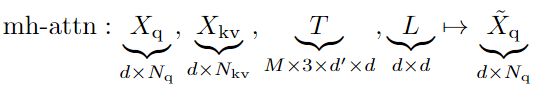
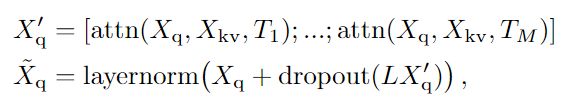
Multi-Head Attention相当于 个不同的self-attention的集成(ensemble),在这里我们以 举例说明。Multi-Head Attention的输出分成3步:
1、将数据 分别输入到图13所示的8个self-attention中,得到8个加权后的特征矩阵 。
2、将8个 按列拼成一个大的特征矩阵;
3、特征矩阵经过一层全连接后得到输出 。
Single-head attention layers:参考自注意力机制的实现,首先,在添加查询和键位置编码后,计算所谓的查询(query),键(key)的ositional encodings。然后根据查询和键之间的点积的softmax计算注意力权重α,以使查询序列的每个元素都参与键值序列的所有元素。最终输出是通过注意力权重加权的值的总和。
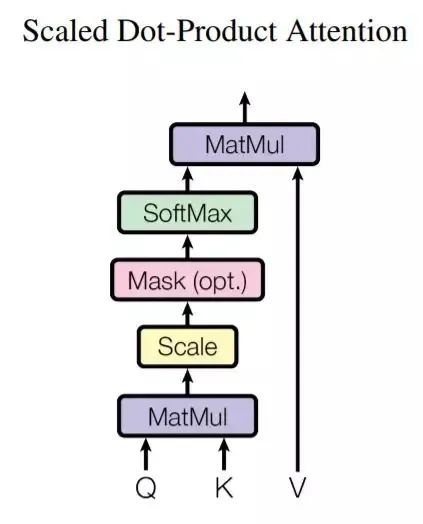
在本文中,位置编码可能是学习的或固定的,但在给定查询/键值序列的所有关注层中都共享,因此本文没有明确地将其写为关注参数。当描述编码器和解码器时,我们将提供有关其确切值的更多详细信息。
Feed-forward network (FFN) layers:最初的Transformer交替使用了多头注意力和所谓的FFN层,它们实际上是多层1x1卷积。本文的FFN由两层带有ReLUactivation的1x1卷积层组成,两层之后还有一个残差连接,dropout和layer normalization。
2.2 Transformer decoder:解码器遵循Transformer的标准体系结构,使用多头自编码器和编码器-解码器注意机制对d大小的N embeddings进行转换。与原始Transformer的不同之处在于,我们的模型在每个解码器层并行解码N个对象。
由于解码器也是置换不变的,因此N输入的嵌入必须不同才能产生不同的结果。这些输入嵌入是我们称为对象查询的学习位置编码,与编码器类似,我们将它们添加到每个关注层的输入中.。N个物体查询由解码器转换为输出embedding,然后独立解码为box坐标和通过前馈网络对类进行标记,得出N个 最终的预测。
通过对这些嵌入的自注意力和编码器-解码器注意力,该模型使用它们之间的成对关系,全局地将所有对象归结在一起,同时能够将整个图像用作上下文。
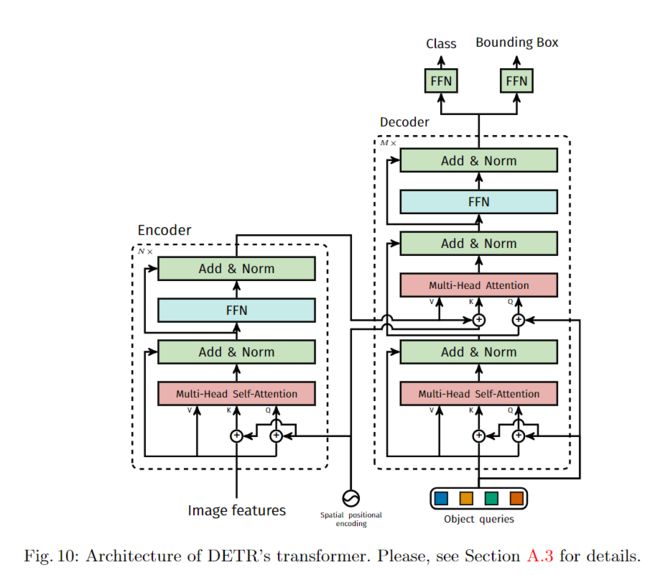
图10中给出了DETR中使用的转换器的详细说明,并在每个关注层传递了位置编码。来自CNN主干的图像特征通过了转换器编码器,并将空间位置编码与添加到查询和键处的空间编码一起传递。每个多头自我注意层。然后,解码器接收查询(最初设置为零),输出位置编码(对象查询)和编码器内存,并通过多个多头自我关注和解码器-编码器关注来生成最终的一组预测类标签和边界框。可以跳过第一解码器层中的第一自我注意层。
3 Prediction feed-forward networks (FFNs):最终预测是由具有ReLU激活功能且具有隐藏层的3层感知器和线性层计算的。FFN预测框的标准中心坐标,高度和宽度。由于预测了一组固定大小的N bounding框,其中N通常比图像中实际感兴趣的对象的数量大得多,因此使用了一个额外的特殊类:∅ 空标签类来表示未检测到任何对象。此类在标准目标检测方法中扮演的角色与“背景”类相似。
Auxiliary decoding losses:我们在每个解码器层之后添加预测FFN和Hungarian 损失,所有预测FFN共享其参数,并使用附加的共享层范数来标准化来自不同解码器层的预测FFN的输入。
Box loss:
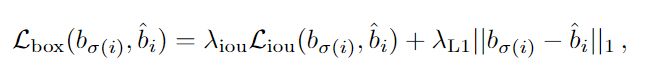
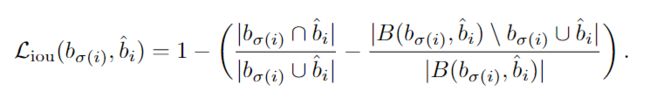
DICE/F-1 loss :
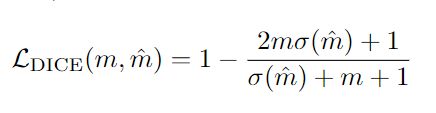
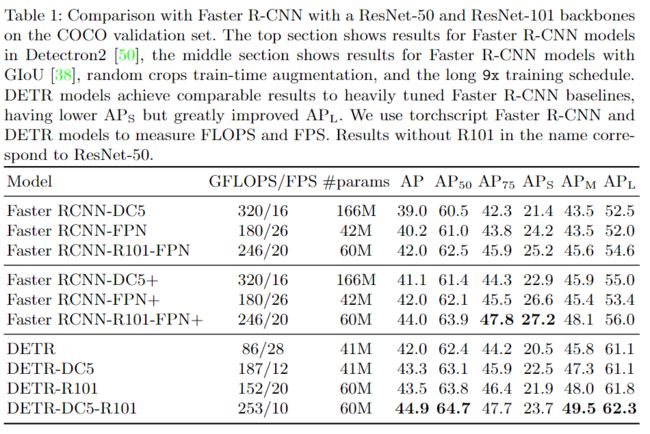
实验与结果分析
与Faster RCNN比较

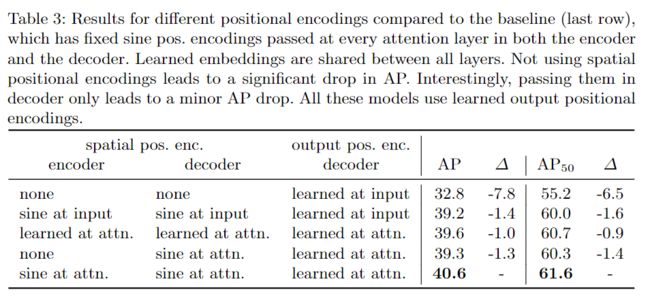
不同位置编码的对比
应用于全景分割
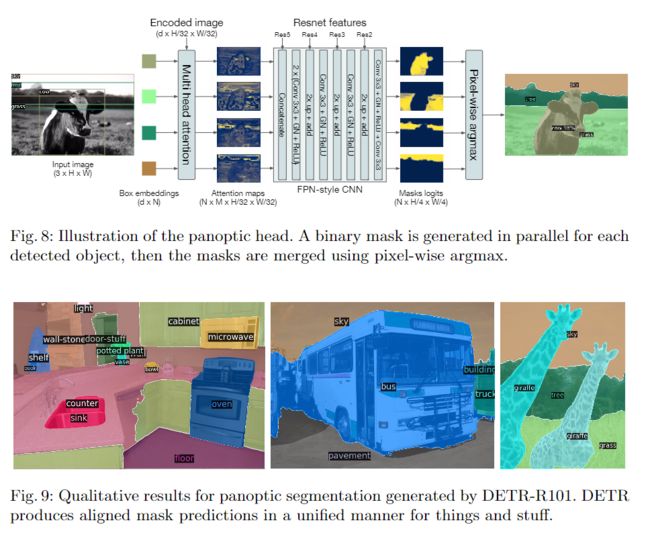
具体细节可以参考原文,包括训练细节,十分详细。
参考
https://zhuanlan.zhihu.com/p/48508221
扫描上方微信号,进入学习群。
目标检测、图像分割、自动驾驶、机器人、面试经验。
福利满满,名额已不多…