Python爬虫:爬取天气
Python爬取天气
python最大的用途就是爬虫了,这里演示一下使用python urllib完成一个简单的天气爬取。
爬取的页面直接选择百度的天气信息,当你在百度中输入城市+天气就会直接显示出当地的天气信息,有了想要的信息就可以对页面进行分析爬取了。
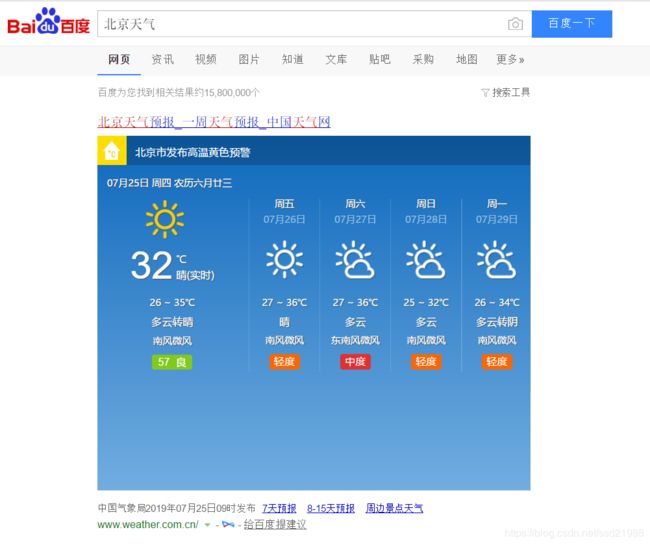
最左侧的为当前的天气就是我们想要的数据

知道数据位置后,在开始前还需要对当前城市进行定位然后请求当前的城市天气
通过IP获取当前所处城市
使用python请求一个api传入当前ip即可获得当前ip的地址
location_temp = json.loads(
urllib.request.urlopen(
"https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?`在这里插入代码片`query=112.96.180.56&resource_id=6006&format=json")
.read().decode(
"gbk"))["data"][0]["location"]
通过这个api就获取到了当前城市,这是返回数据

在城市的后面还有联通二个字,这个也要进行处理
location = location_temp.split(" ")[0] if " " in location_temp else location_temp
经过字符切割后,就能得出最终的城市名称

获取到了城市地址之后就可以向百度传入这个参数进行请求了,这是在百度搜索结果处理后的url
![]()
现在只需要将城市名称拼接到wd后面就能请求到想要百度的页面了,要获取到天气还要在城市名称后面加上‘天气’二个字。
import urllib.request
import urllib.parse
# 拼接url
url = "http://www.baidu.com/s?wd=" + urllib.parse.quote(location+'天气')
# 请求读取
page_source = urllib.request.urlopen(url).read().decode("utf-8").replace("\n", "").replace("\r", "")
url完成请求后,就是对关键数据进行提取了,可以自己先在浏览器中输入url然后使用开发者工具定位要找的元素id或class。
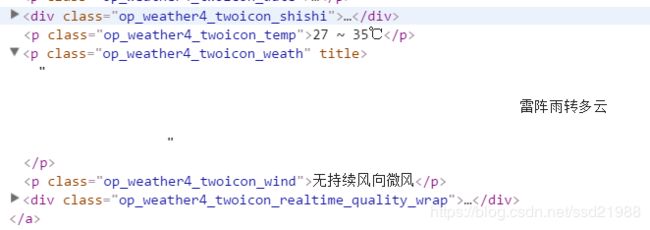
这里的二个p标签就是我们要的数据,它们的class为op_weather4_twoicon_weath和op_weather4_twoicon_temp,接下来用python将这个标签的文本提取出来就行了。
weather = page_source.split(')[1].split('title="">')[1].split('
')[0].strip()
temp = page_source.split(''
)[1].split('')[0].strip()
print(weather,temp)
爬取成功

高效率的聚合搜索:www.xiaoqiuss.cn