mybatis分页插件
mybatis
- mybatis 分页插件
mybatis 分页插件
网上找到的mybatis分页插件实现原理大多是通过拦截原查询sql , 外层增加分页参数 .
如下
String sql = (String) metaStatementHandler.getValue(“delegate.boundSql.sql”);
//构建新的分页sql语句
String limitSql = “select * from (” + sql + “) $_paging_table limit ?,?”;
然后通过count 语句拿到查询的结果总数, 计算有多少页 , count语句通常如下改造
将sql改写成统计记录数的count 语句,这里是mysql的改写语句,将第一次查询结果作为第二次查询的表
String countSql = “select count(*) as total from (” + sql + “) $_paging”;
当原sql比较复杂的时候, 效率比较低.
粗糙的测试几遍在100万数据的时候.
select count() as total from (" + sql + ") 0.9s
select count() as total from table where …; 0.3s
在600万数据的时候是
select count() as total from (" + sql + ") 1分钟
select count() as total from table where …; 5s
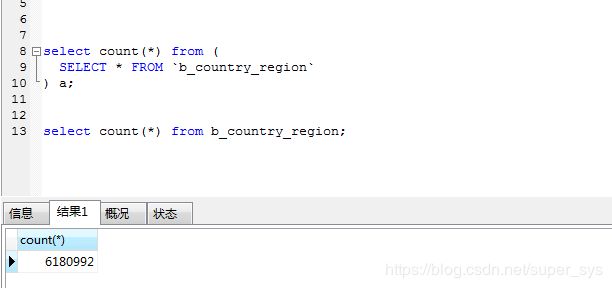
上图中的2条sql ,在600万数据时,多次测试,交换执行先后顺序测试.效率差距保持10倍以上.
如果原sql含有分组函数的时候,效率差距翻倍增大. (工具显示ms 实际是s秒)

交换执行顺序
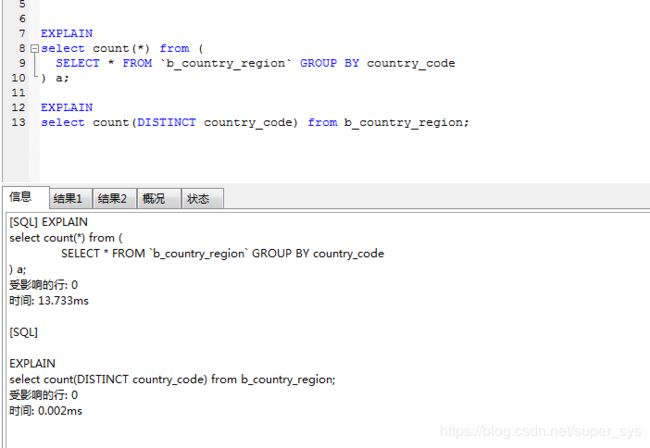
不懂数据库查询原理,懂一些sql的语法,觉得可以通过改造原sql ,而不是直接增加一层 select count(*) from (原sql). 性能会更好.
直接上代码, 大部分的情况下,可以把原sql改造为一条直接的count 语句. 如果报错,说明不支持,这条sql的count语句就需要自己写.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GenMysqlCountUtil {
/** 结果集的子查询 */
public static Pattern subquery = Pattern.compile("\\(\\s*select[^\\)]+\\)[\\s\\w]+,", Pattern.CASE_INSENSITIVE);
/** 结果集最后一个子查询 */
public static Pattern lastSubquery = Pattern.compile("\\(\\s*select[^\\)]+\\)[\\s\\w]+?(?!from)",
Pattern.CASE_INSENSITIVE);
/** 外层order by */
public static Pattern pOrder = Pattern.compile(
"order\\s+by(\\s[\\w\\.]+(\\s*asc|\\s*desc)*)?(\\s*,\\s*[\\w\\.]+(\\s*asc|\\s*desc)*)*",
Pattern.CASE_INSENSITIVE);
/** 外层group by */
public static Pattern pGroup = Pattern.compile("group\\s+by(\\s[\\w\\.]+)?(\\s*,\\s*[\\w\\.]+)*",
Pattern.CASE_INSENSITIVE);
/** 外层limit */
public static Pattern pLimit = Pattern.compile("limit", Pattern.CASE_INSENSITIVE);
/** sleect from */
public static Pattern pSelectF = Pattern.compile("select[\\s\\S]+?from", Pattern.CASE_INSENSITIVE);
/** count sum avg max min group_concat */
public static Pattern pAggregate = Pattern.compile(
"max\\s*\\(|min\\s*\\(|count\\s*\\(|sum\\s*\\(|avg\\s*\\(|group_concat\\s*\\(", Pattern.CASE_INSENSITIVE);
/** 外层having */
public static Pattern pHaving = Pattern.compile("having\\s+[\\s\\W]+", Pattern.CASE_INSENSITIVE);
public static String genCountSql(String sql) {
Matcher m = null;
// 去掉结果集的子查询
m = subquery.matcher(sql);
while (m.find()) {
sql = m.replaceAll("");
}
// 去掉结果集的最后一个子查询
m = lastSubquery.matcher(sql);
while (m.find()) {
sql = m.replaceAll("");
}
int start = -1, end = -1;
// 去掉最外层limit
m = pLimit.matcher(sql);
while (m.find()) {
start = m.start();
end = m.end();
}
if (start > sql.lastIndexOf(")")) {
sql = sql.substring(0, start);
start = -1;
end = -1;
}
// 去掉最外层having
m = pHaving.matcher(sql);
/*
* while (m.find()) { start = m.start(); end = m.end(); } String having
* = null; if (start > sql.lastIndexOf("from")) { having =
* sql.substring(start, end); sql = sql.substring(0, start);
*
* start = -1; end = -1; }
*/
// 去掉最外层order by
m = pOrder.matcher(sql);
while (m.find()) {
start = m.start();
end = m.end();
}
if (start > sql.lastIndexOf(")")) {
sql = sql.substring(0, start) + sql.substring(end, sql.length());
start = -1;
end = -1;
}
// 处理最外层group 转count (distinct)
m = pGroup.matcher(sql);
while (m.find()) {
start = m.start();
end = m.end();
}
String group = null;
if (start > sql.lastIndexOf("from")) {
group = sql.substring(start, end).replaceFirst("([Gg][Rr][Oo][Uu][Pp])\\s+([Bb][Yy])", "distinct");
sql = sql.substring(0, start) + sql.substring(end, sql.length());
start = -1;
end = -1;
}
// 获取select - from
m = pSelectF.matcher(sql);
if (!m.find()) {
return null;
}
String countSql = "";
// 外层有group
if (group != null) {
// group 多个字段
if (group.indexOf(",") > 0) {
countSql = m.replaceFirst("select count(*) from (select " + group + " from ") + ") unique_alias";
return countSql;
}
countSql = m.replaceFirst("select count(" + group + ") from");
return countSql;
}
// 外层无group by
// 结果集有聚合函数
if (pAggregate.matcher(m.group()).find()) {
return "select 1";
}
countSql = m.replaceFirst("select count(0) from");
return countSql;
}
}
完整的分页插件代码还有代码生成工具链接
分页插件: https://download.csdn.net/download/super_sys/11009842
生成工具: https://download.csdn.net/download/super_sys/11009846