人智导(七):回归分析
人智导(七):回归分析
问题引入
- 给出一组示例,估算/还原出函数f:

- 基于示例的学习(归纳学习):未知 f f f,已知的是一个示例集合(训练集),求得一个或多个函数 f ′ f' f′(模型、假设),使得 f ′ f' f′近似于 f f f
举例:
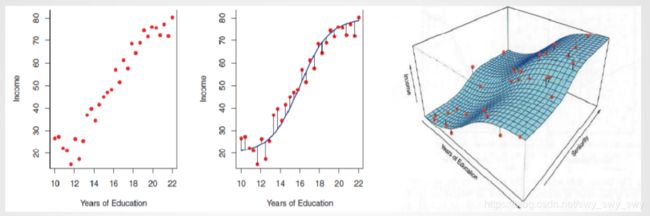
30个无产者的数据:收入与受教育年限
问题模型
问题描述
给出一组观测变量 X = ( x 1 , x 2 , … , x p ) X=(x_1,x_2, \dots ,x_p) X=(x1,x2,…,xp)以及响应变量 Y Y Y(连续值)
X X X与 Y Y Y之间存在关联,即
Y = f ( X ) + ϵ Y=f(X)+\epsilon Y=f(X)+ϵ
其中 f f f是未知的函数, ϵ \epsilon ϵ是随机错误(均值为零)
任务:已知一组观测数据( X X X, Y Y Y)取值,估算出 f f f
目的:预测和推理(解释)
预测的目的
- 在许多现实应用中,输入变量 X X X是可预测的,但输出变量 Y Y Y的实际值不易直接观测到
- 试图预测真实的 Y Y Y,通过 Y ′ = f ′ ( X ) Y'=f'(X) Y′=f′(X)
- f ′ f' f′表示未知 f f f的预估, Y ′ Y' Y′表示预测的结果
- 回归技术:估算 f f f,使得误差(残差)平方均值最小化 E ( Y − Y ′ ) 2 o r [ f ( X ) − f ′ ( X ) ] 2 E(Y-Y')^2~or~[f(X)-f'(X)]^2 E(Y−Y′)2 or [f(X)−f′(X)]2
目标函数:均方误差最小
R S S = e 1 2 + e 2 2 + ⋯ + e n 2 = ( y 1 − y 1 ′ ) 2 + ( y 2 − y 2 ′ ) 2 + ⋯ + ( y n − y n ′ ) 2 RSS=e_1^2+e_2^2+\dots +e_n^2 = (y_1-y'_1)^2+(y_2-y'_2)^2+\dots +(y_n-y'_n)^2 RSS=e12+e22+⋯+en2=(y1−y1′)2+(y2−y2′)2+⋯+(yn−yn′)2
均方误差 M S E = R S S n MSE=\frac{RSS}{n} MSE=nRSS最小化
数学期望(均值): μ = Σ i = 1 n y i n \mu = \frac{\Sigma^n_{i=1}y_i}{n} μ=nΣi=1nyi
方差:度量随机变量与其数学期望(即均值)之间的偏离程度 σ 2 = Σ i = 1 n ( y i − μ ) 2 n \sigma^2=\frac{\Sigma^n_{i=1}(y_i-\mu)^2}{n} σ2=nΣi=1n(yi−μ)2
标准差: σ \sigma σ
推理的目的
估算 f f f,是理解 X X X与 Y Y Y之间的关系
具体地,回答以下问题:
- ( x 1 , x 2 , … , x p ) (x_1,x_2,\dots ,x_p) (x1,x2,…,xp)中哪些变量与 Y Y Y关联?
- Y Y Y与 ( x 1 , x 2 , … , x p ) (x_1,x_2,\dots ,x_p) (x1,x2,…,xp)中的每一变量的关系是什么?是正/负相关性?
- Y Y Y与 ( x 1 , x 2 , … , x p ) (x_1,x_2,\dots ,x_p) (x1,x2,…,xp)中每一变量的关系能否线性地概括?或需要更复杂的方程表示?
应用示例:为客户改善其产品销售提供咨询
- 数据集:某商业客户产品在数百家商场的销售量以及三种不同媒体(电视、电台广播、报纸)在每家广告费用支出的历史数据。
- 应用目的:
- 开发一个精确的预测模型,能基于这三种媒体费用的预算预测该产品销售量 s a l e s = f ( t v , r a d i o , n e w s p a p e r ) sales=f(tv,~radio,~newspaper) sales=f(tv, radio, newspaper)
- 解答问题,如:
- 哪种媒体对销售有贡献?
- 哪种媒体对销售量的提升贡献最大?
- TV广告费用的增长将导致多少销售量的增长?
基于示例的学习
如何估算 f f f?
已有一组观察数据(训练数据):
{ ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),\dots ,(x_n,y_n)\} {(x1,y1),(x2,y2),…,(xn,yn)}, x i x_i xi是 p p p个元素的矢量
通过已观察到的(训练)数据估算未知的 f f f,发现 f ′ f' f′,使得 Y ≈ f ′ ( X ) Y\approx f'(X) Y≈f′(X)
两类通用的方法:参数化方法与非参数化方法
参数化方法:基于模型的方法

第一步:假设函数 f f f的形式/形状,如 f f f假设是线性的(模型)
f ( X ) = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β p X p f(X)=\beta_0+\beta_1X_1+\beta_2X_2+\dots +\beta_pX_p f(X)=β0+β1X1+β2X2+⋯+βpXp
第二步:使用训练数据,来训练这个模型。问题简化成估算参数的值 β 0 , β 1 , … , β p \beta_0,\beta_1 ,\dots ,\beta_p β0,β1,…,βp
Y ≈ β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β p X p Y\approx \beta_0+\beta_1X_1+\beta_2X_2+\dots +\beta_pX_p Y≈β0+β1X1+β2X2+⋯+βpXp
特点:
- 泛化能力强(generalization)
- 解释性强,适于判断X与Y的关联(推理)
参数化方法弱处:
有可能与真实的 f f f形状非常不同,预测精度相差较大。
非参数方法
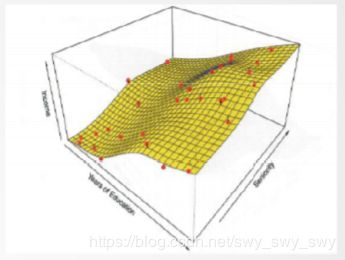
- 不假设 f f f的形式/形状,而是尽可能地拟合观察(训练)数据
- 特点:可以拟合更多形式/形状的 f f f,故预测精度高
- 缺点:需要大量的观察数据(训练数据),以便训练一个有精度的模型(针对 f f f),否则容易过拟合(overfitting)
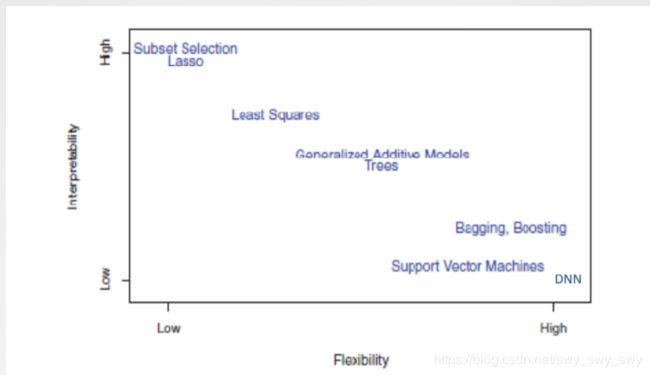
预测精度与模型可解释性的权衡
- 参数化方法:不灵活、更受限(估算的 f f f形状局限于小范围内)
- 非参数方法:更灵活的(拟合性好)、估算的 f f f形状在大范围内变化
- 既然有更灵活的方法,为何选择应用比较受限的方法?
- 以推理/解释为目的。线性模型易于解释各观测变量X与响应变量Y之间的关系
- 而描述形状更灵活的方法如SVM、Bagging&Boosting、DNN等理解观测变量X与响应变量Y间的关联是很困难的
如下图:
回归
线性回归
- 最简单形式的线性回归:单一观测变量 Y = β 0 + β 1 X Y = \beta_0 +\beta_1 X Y=β0+β1X 已知有一组观察数据(训练数据): { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),\dots ,(x_n,y_n)\} {(x1,y1),(x2,y2),…,(xn,yn)},其中第i个观测数据的误差(残差): e i = y i ′ − y i e_i = y'_i - y_i ei=yi′−yi;目标是求得参量 β 0 \beta_0 β0和 β 1 \beta_1 β1以最小化误差(损失)函数 L o s s ( β ) = Σ i = 1 n ( y i ′ − y i ) 2 Loss(\beta)=\Sigma^n_{i=1}(y'_i - y_i)^2 Loss(β)=Σi=1n(yi′−yi)2
- 最小二乘法: β 1 = Σ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) Σ i = 1 n ( x i − x ˉ ) 2 \beta_1 = \frac{\Sigma^n_{i=1}(x_i-\bar{x})(y_i-\bar{y})}{\Sigma^n_{i=1}(x_i-\bar{x})^2} β1=Σi=1n(xi−xˉ)2Σi=1n(xi−xˉ)(yi−yˉ) β 0 = y ˉ − β 1 x ˉ \beta_0 = \bar{y} - \beta_1 \bar{x} β0=yˉ−β1xˉ x ˉ = Σ i = 1 n x i n y ˉ = Σ i = 1 n y i n \bar{x} = \Sigma^n_{i=1}\frac{x_i}{n}~\bar{y} = \Sigma^n_{i=1}\frac{y_i}{n} xˉ=Σi=1nnxi yˉ=Σi=1nnyi
举例:

β 1 = 3.5 β 0 = 23.6 Y ≈ 23.6 + 3.5 X \beta_1 = 3.5~\beta_0 = 23.6~Y\approx 23.6+3.5X β1=3.5 β0=23.6 Y≈23.6+3.5X
预测10年工龄员工的工资:58.6k
多元线性回归
- 多元回归模型: Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β n X n Y=\beta_0+\beta_1X_1+\beta_2X_2+\dots +\beta_nX_n Y=β0+β1X1+β2X2+⋯+βnXn示例: s a l e s = β 0 + β 1 × r a d i o + β 2 × t v + β 3 × n e w s p a p e r sales = \beta_0~+~\beta_1~ \times~ radio~+~\beta_2~\times~tv~+\beta_3~\times~newspaper sales=β0 + β1 × radio + β2 × tv +β3 × newspaper
- 极小化损失函数(目标函数): L o s s ( β ) = Σ i = 1 n ( f β ′ ( x i ) − y i ) 2 Loss(\beta)=\Sigma^n_{i=1}(f'_{\beta}(x_i)-y_i)^2 Loss(β)=Σi=1n(fβ′(xi)−yi)2
- 最小二乘法求解参数 L o s s ( β ) = Σ i = 1 n e 2 = Σ i = 1 n ( y ′ − y ) 2 = e ′ e = ( Y − Y ′ ) ′ ( Y − Y ′ ) = ( Y − X β ) ′ ( Y − X β ) = Y ′ Y − β ′ X ′ Y − Y X β + β ′ X ′ X β = Y ′ Y − 2 β ′ X ′ Y + β ′ X ′ X β Loss(\beta)=\Sigma^n_{i=1}e^2 =\Sigma^n_{i=1}(y'-y)^2\\=e'e=(Y-Y')'(Y-Y')=(Y-X\beta)'(Y-X\beta) \\=Y'Y-\beta'X'Y-YX\beta +\beta'X'X\beta \\=Y'Y-2\beta'X'Y +\beta'X'X\beta Loss(β)=Σi=1ne2=Σi=1n(y′−y)2=e′e=(Y−Y′)′(Y−Y′)=(Y−Xβ)′(Y−Xβ)=Y′Y−β′X′Y−YXβ+β′X′Xβ=Y′Y−2β′X′Y+β′X′Xβ上式求偏导极小化损失函数: ∂ L o s s ( β ) ∂ β = ∂ ( Y ′ Y − 2 β ′ X ′ Y + β ′ X ′ X β ) ∂ β = − 2 X ′ Y + 2 X ′ X β = 0 \frac{\partial Loss(\beta)}{\partial \beta}=\frac{\partial (Y'Y-2\beta'X'Y+\beta'X'X\beta)}{\partial\beta} = -2X'Y+2X'X\beta = 0 ∂β∂Loss(β)=∂β∂(Y′Y−2β′X′Y+β′X′Xβ)=−2X′Y+2X′Xβ=0 因此 β = ( X ′ X ) − 1 X ′ Y \beta = (X'X)^{-1}X'Y β=(X′X)−1X′Y
回归模型的线性假设
- 线性回归假设一
- 观测变量 X = ( X 1 , X 2 , … , X p ) X=(X_1,X_2,\dots ,X_p) X=(X1,X2,…,Xp)与响应变量间的关系是累加性(additive)的(变量独立) Y = β 0 + β 1 X 1 + β 2 X 2 Y = \beta_0 +\beta_1X_1 +\beta_2 X_2 Y=β0+β1X1+β2X2
- 例如有两个观测变量时,扩展考虑变量间的相关性,示例: Y = β 0 + β 1 X 1 + β 2 X 2 + β 3 X 1 X 2 Y = β 0 + ( β 1 + β 3 X 2 ) X 1 + β 2 X 2 Y = β 0 + β 1 ^ X 1 + β 2 X 2 Y=\beta_0+\beta_1X_1+\beta_2X_2+\beta_3X_1X_2 \\ Y=\beta_0 +(\beta_1+\beta_3X_2)X_1+\beta_2X_2 \\ Y = \beta_0 +\hat{\beta_1}X_1+\beta_2X_2 Y=β0+β1X1+β2X2+β3X1X2Y=β0+(β1+β3X2)X1+β2X2Y=β0+β1^X1+β2X2 s a l e s = β 0 + ( β 1 + β 3 × r a d i o ) × y v + β 2 × r a d i o sales~=~\beta_0~+~(\beta_1~+~\beta_3\times radio)\times yv~+~\beta_2\times radio sales = β0 + (β1 + β3×radio)×yv + β2×radio
- 线性回归模型假设二
- 观测变量X与响应变量Y间的关系是线性的
- 多项式回归,扩展地表示非线性关系为多元线性回归 Y = β 0 + β 1 X + β 2 X 2 + β 3 X 3 + ⋯ + β n X n Y=\beta_0 +\beta_1X+\beta_2X^2+\beta_3X^3+\dots +\beta_nX^n Y=β0+β1X+β2X2+β3X3+⋯+βnXn
- 例如 n n n取值为3: Y = β 0 + β 1 X 1 + β 2 X 2 + β 3 X 3 X 1 = X X 2 = X 2 X 3 = X 3 Y =\beta_0+\beta_1X_1+\beta_2X_2+\beta_3X_3 \\X_1=X~X_2=X^2~X_3=X^3 Y=β0+β1X1+β2X2+β3X3X1=X X2=X2 X3=X3
Logistic回归
引入
有两种预测问题:
- 响应变量Y是连续型(数值型):线性回归,用于数值型问题解决
- 响应变量Y是离散型(类目型):逻辑(Logistic)回归,用于分类问题解决
- 二元分类问题(0,1)
- 并不直接模型化响应变量Y
- Logistic回归模型化Y属于一个特定类的概率,即模型化 P r ( Y = 0 ∣ X ) Pr(Y=0|X) Pr(Y=0∣X)与 X X X的关系
Logistic回归

- Logistic函数(Sigmoid函数) f ( z ) = 1 1 + e − z f(z)=\frac{1}{1+e^{-z}} f(z)=1+e−z1 z = β 0 + β 1 X 1 + ⋯ + β n X n z=\beta_0 +\beta_1X_1+\dots +\beta_nX_n z=β0+β1X1+⋯+βnXn
- [0,1]区间平滑曲线,且 f ( z ) + f ( − z ) = 1 f(z)+f(-z)=1 f(z)+f(−z)=1
- 二元分类: P ( y = 0 ∣ z ) = f ( z ) P(y=0|z)=f(z) P(y=0∣z)=f(z) P ( y = 1 ∣ z ) = 1 − f ( z ) P(y=1|z)=1-f(z) P(y=1∣z)=1−f(z)
Logistic回归与贝叶斯方法
二分类(类C1:y=0;类C2:y=1)
P ( C 1 ∣ X ) = P ( X , C 1 ) P ( X ) = P ( X ∣ C 1 ) P ( C 1 ) P ( X ) = P ( X ∣ C 1 ) P ( C 1 ) P ( X ∣ C 1 ) P ( C 1 ) + P ( X ∣ C 2 ) P ( C 2 ) = 1 1 + e − α P(C1|X)=\frac{P(X,C1)}{P(X)}=\frac{P(X|C1)P(C1)}{P(X)}\\ =\frac{P(X|C1)P(C1)}{P(X|C1)P(C1)+P(X|C2)P(C2)}\\ =\frac{1}{1+e^{-\alpha}} P(C1∣X)=P(X)P(X,C1)=P(X)P(X∣C1)P(C1)=P(X∣C1)P(C1)+P(X∣C2)P(C2)P(X∣C1)P(C1)=1+e−α1
其中
α = l n P ( X ∣ C 1 ) P ( C 1 ) P ( X ∣ C 2 ) P ( C 2 ) \alpha =ln\frac{P(X|C1)P(C1)}{P(X|C2)P(C2)} α=lnP(X∣C2)P(C2)P(X∣C1)P(C1)
逻辑回归(判别模型)
极大似然估计:决定最优参数 β ∗ \beta^{*} β∗: β ∗ ← a r g β m a x Π i = 1 m P ( Y i ∣ X i , β ) \beta^{*}\leftarrow arg_{\beta}max\Pi^m_{i=1}P(Y_i|X_i,\beta) β∗←argβmaxΠi=1mP(Yi∣Xi,β)
目标函数:求全局最优解
f ( β ) = Σ i = 1 m [ Y i l n P ( Y i = 1 ∣ X i , β ) + ( 1 − Y i ) l n P ( Y i = 0 ∣ X i , β ) ] = Σ i = 1 m [ Y i l n P ( Y i = 1 ∣ X i , β ) P ( Y i = 0 ∣ X i , β ) + l n P ( Y i = 0 ∣ X i , β ) ] = Σ i = 1 m [ Y i ( β 0 + Σ j = 1 n β j X i ( j ) ) − ( 1 + e x p ( β 0 + Σ j = 1 n β j X i ( j ) ) ) ] f(\beta) = \Sigma^m_{i=1}[Y_iln~P(Y_i=1|X_i,\beta)+(1-Y_i)ln~P(Y_i=0|X_i,\beta)]\\ =\Sigma^m_{i=1}[Y_iln\frac{P(Y_i=1|X_i,\beta)}{P(Y_i=0|X_i, \beta)} + ln~P(Y_i=0|X_i,\beta)]\\ =\Sigma^m_{i=1}[Y_i(\beta_0+\Sigma^n_{j=1}\beta_jX^{(j)}_i)-(1+exp(\beta_0+\Sigma^n_{j=1}\beta_jX^{(j)}_i))] f(β)=Σi=1m[Yiln P(Yi=1∣Xi,β)+(1−Yi)ln P(Yi=0∣Xi,β)]=Σi=1m[YilnP(Yi=0∣Xi,β)P(Yi=1∣Xi,β)+ln P(Yi=0∣Xi,β)]=Σi=1m[Yi(β0+Σj=1nβjXi(j))−(1+exp(β0+Σj=1nβjXi(j)))]
朴素贝叶斯(生成模型)
二元分类 Y ∈ { 0 , 1 } Y\in \{0,1\} Y∈{0,1}: P ( Y ∣ X ) = P ( X , Y ) P ( X ) = P ( X ∣ Y ) P ( Y ) P ( X ) P(Y|X)=\frac{P(X,Y)}{P(X)}=\frac{P(X|Y)P(Y)}{P(X)} P(Y∣X)=P(X)P(X,Y)=P(X)P(X∣Y)P(Y)
条件独立性假设 X = ( x 1 , x 2 , … , x n ) X=(x_1,x_2,\dots ,x_n) X=(x1,x2,…,xn): P ( X ∣ Y ) = Π i = 1 n P ( x i ∣ Y ) P(X|Y)=\Pi^n_{i=1}P(x_i|Y) P(X∣Y)=Πi=1nP(xi∣Y)
假设在Y类中变量 x ∈ X x\in X x∈X的概率分布服从高斯(正态)分布
概率密度函数 P ( x ∣ Y ) = 1 2 π σ k e − ( x − μ k ) 2 2 σ k 2 P(x|Y)=\frac{1}{\sqrt{2\pi}\sigma_k}e^{-\frac{(x-\mu_k)^2}{2\sigma_k^2}} P(x∣Y)=2πσk1e−2σk2(x−μk)2