拥塞控制在mininet中的仿真
- 查看操作系统中支持的拥塞控制版本
cat /proc/sys/net/ipv4/tcp_allowed_congestion_control
- 通过socket配置拥塞控制算法
int set_congestion_type(int fd,char *cc){
char optval[TCP_CC_NAME_MAX];
memset(optval,0,TCP_CC_NAME_MAX);
strncpy(optval,cc,TCP_CC_NAME_MAX);
int length=strlen(optval)+1;
int rc=setsockopt(fd,IPPROTO_TCP, TCP_CONGESTION, (void*)optval,length);
if(rc!=0){
printf("cc is not supprt\n");
}
return rc;
}
mininet仿真拓补构建:
#!/usr/bin/python
from mininet.topo import Topo
from mininet.net import Mininet
from mininet.cli import CLI
from mininet.link import TCLink
import time
# ___r1____
# / \0 1
# h1 r3---h2
#
#
bottleneckbw=4
nonbottlebw=500;
max_queue_size =bottleneckbw*1000*100/(1500*8)
net = Mininet( cleanup=True )
h1 = net.addHost('h1',ip='10.0.1.1')
r1 = net.addHost('r1',ip='10.0.1.2')
r3 = net.addHost('r3',ip='10.0.5.1')
h2 = net.addHost('h2',ip='10.0.5.2')
c0 = net.addController('c0')
net.addLink(h1,r1,intfName1='h1-eth0',intfName2='r1-eth0',cls=TCLink , bw=nonbottlebw, delay='20ms', max_queue_size=max_queue_size)
net.addLink(r1,r3,intfName1='r1-eth1',intfName2='r3-eth0',cls=TCLink , bw=bottleneckbw, delay='20ms', max_queue_size=max_queue_size)
net.addLink(r3,h2,intfName1='r3-eth1',intfName2='h2-eth0',cls=TCLink , bw=nonbottlebw, delay='10ms', max_queue_size=max_queue_size)
net.build()
h1.cmd("ifconfig h1-eth0 10.0.1.1/24")
h1.cmd("route add default gw 10.0.1.2 dev h1-eth0")
r1.cmd("ifconfig r1-eth0 10.0.1.2/24")
r1.cmd("ifconfig r1-eth1 10.0.2.1/24")
r1.cmd("ip route add to 10.0.1.0/24 via 10.0.1.1")
r1.cmd("ip route add to 10.0.2.0/24 via 10.0.2.2")
r1.cmd("ip route add to 10.0.5.0/24 via 10.0.2.2")
r1.cmd('sysctl net.ipv4.ip_forward=1')
r3.cmd("ifconfig r3-eth0 10.0.2.2/24")
r3.cmd("ifconfig r3-eth1 10.0.5.1/24")
r3.cmd("ip route add to 10.0.1.0/24 via 10.0.2.1")
r3.cmd("ip route add to 10.0.2.0/24 via 10.0.2.1")
r3.cmd("ip route add to 10.0.5.0/24 via 10.0.5.2")
r3.cmd('sysctl net.ipv4.ip_forward=1')
h2.cmd("ifconfig h2-eth0 10.0.5.2/24")
h2.cmd("route add default gw 10.0.5.1")
net.start()
time.sleep(1)
CLI(net)
net.stop()
h1中启动两个tcp流,各向server端传输100MB的数据。server端每隔5秒,输出收到的数据。格式为 id time length。
根据log抽取每个客户端的数据发送速率。脚本:
#!/usr/bin/python
delimiter="_"
class Client:
def __init__(self,prefix,id):
self.id=id
name=prefix+delimiter+str(id)+".txt"
self.fout=open(name,'w')
self.samples=0;
self.last_time=0;
self.bytes=0;
def __del__(self):
self.fout.close()
def OnNewSample(self,id,ts,len):
if id!=self.id:
return
sec=float(ts)/1000
if self.samples==0:
self.fout.write(str(sec)+"\t"+str(0)+"\n");
else:
previous_bytes=self.bytes
inc_bytes=float(len-previous_bytes)
inc_time=(ts-self.last_time)*1000;
if ts>self.last_time:
rate=inc_bytes*8/inc_time #in Mbps
self.fout.write(str(sec)+"\t"+str(rate)+"\n");
self.samples=self.samples+1
self.last_time=ts
self.bytes=len
prefix="tcp_client_rate"
clients={}
log_in="server_log.txt"
# id ts length
with open(log_in) as txtData:
for line in txtData.readlines():
lineArr = line.strip().split()
id=lineArr[0]
time=int(lineArr[1])
len=int(lineArr[2])
if clients.has_key(id):
clients.get(id).OnNewSample(id,time,len)
else:
client=Client(prefix,id)
clients[id]=client
client.OnNewSample(id,time,len)
clients.clear()
画图:
#! /bin/sh
file1=tcp_client_rate_1.txt
file2=tcp_client_rate_2.txt
output=tcp
gnuplot<后来我测试的时候,发现带宽只能在2-3Mbps之间波动。把链路带宽调整到32M,4个数据流分享带宽。每个数据流的理论带宽应该是8Mbps。我猜测是TCP send buffer的原因。于是就在代码中增加配置buf的部分。
void TcpClient::SetSendBufSize(int len){
if(sockfd_<0){
return ;
}
int nSndBufferLen =len;
int nLen = sizeof(int);
setsockopt(sockfd_, SOL_SOCKET, SO_SNDBUF, (char*)&nSndBufferLen, nLen);
}
void TcpClient::SetRecvBufSize(int len){
if(sockfd_<0){
return ;
}
int nRcvBufferLen =len;
int nLen = sizeof(int);
setsockopt(sockfd_, SOL_SOCKET, SO_RCVBUF, (char*)&nRcvBufferLen, nLen);
}
测试后,问题依旧:
原因在这里:
···
void TcpClient::NotifiWrite(){
if(sendByte_
NextWriteEvent(millis);
}
}
void TcpClient::NextWriteEvent(int millis){
struct timeval tv;
struct event_base evb=thread_->getEventBase();
event_assign(&write_event_, evb, -1, 0,WriteEventCallback, (void)this);
evutil_timerclear(&tv);
tv.tv_sec = millis/1000;
tv.tv_usec=(millis%1000)*1000;
event_add(&write_event_, &tv);
}
···
我在这里每次发送10个包,下次发包间隔间隔是0-100毫秒之间的随机数。期望带宽:
B = 1500 b y t e s ∗ 10 ∗ 8 50 m s ≈ 2.4 M b p s B=\frac{1500bytes*10*8}{50ms}\approx 2.4Mbps B=50ms1500bytes∗10∗8≈2.4Mbps
更改之后,发现带宽有所提高,但是同理论带宽仍有一段距离。使用iperf测试,socket使用默认的缓冲区,TCP可以很容易达到最大的带宽。仍是一个bug。后来怀疑是libevent的问题,libevent在应用层使用eventbuffer对数据进行缓存。实在懒得去查到底是哪里引入的问题。我把redis中的异步IO库拿了出来,代码不再依赖libevent。经测试,block_client能够很快到达最大带宽。代码从22号写到了25号。
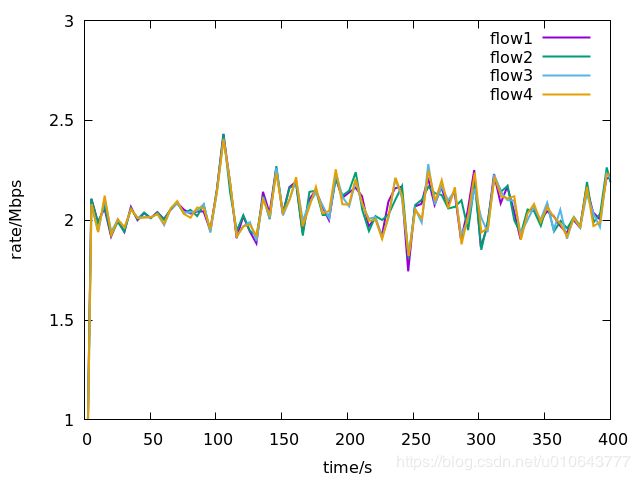
测试结果,瓶颈链路带宽20Mbps,一共四条数据流。
拥塞控制的RTT不公平性测试。仿真拓补:
#!/usr/bin/python
from mininet.topo import Topo
from mininet.net import Mininet
from mininet.link import TCLink
from mininet.cli import CLI
import time
import datetime
import subprocess
import os,signal
import sys
# ___r1____
# / \0 1
# h1 r3---h2
# \ /2
# ---r2-----
bottleneckbw=20
nonbottlebw=500;
max_rtt=300
bottleneckQ=bottleneckbw*1000*max_rtt/(1500*8)
nonbottleneckQ=nonbottlebw*1000*max_rtt/(1500*8)
net = Mininet( cleanup=True )
h1 = net.addHost('h1',ip='10.0.1.1')
r1 = net.addHost('r1',ip='10.0.1.2')
r2 = net.addHost('r2',ip='10.0.3.2')
r3 = net.addHost('r3',ip='10.0.5.1')
h2 = net.addHost('h2',ip='10.0.5.2')
c0 = net.addController('c0')
net.addLink(h1,r1,intfName1='h1-eth0',intfName2='r1-eth0',cls=TCLink , bw=nonbottlebw, delay='10ms', max_queue_size=nonbottleneckQ)
net.addLink(r1,r3,intfName1='r1-eth1',intfName2='r3-eth0',cls=TCLink , bw=nonbottlebw, delay='10ms', max_queue_size=nonbottleneckQ)
net.addLink(r3,h2,intfName1='r3-eth1',intfName2='h2-eth0',cls=TCLink , bw=bottleneckbw, delay='20ms', max_queue_size=bottleneckQ)
net.addLink(h1,r2,intfName1='h1-eth1',intfName2='r2-eth0',cls=TCLink , bw=nonbottlebw, delay='20ms', max_queue_size=nonbottleneckQ)
net.addLink(r2,r3,intfName1='r2-eth1',intfName2='r3-eth2',cls=TCLink , bw=nonbottlebw, delay='30ms', max_queue_size=nonbottleneckQ)
net.build()
h1.cmd("ifconfig h1-eth0 10.0.1.1/24")
h1.cmd("ifconfig h1-eth1 10.0.3.1/24")
h1.cmd("ip route flush all proto static scope global")
h1.cmd("ip route add 10.0.1.1/24 dev h1-eth0 table 5000")
h1.cmd("ip route add default via 10.0.1.2 dev h1-eth0 table 5000")
h1.cmd("ip route add 10.0.3.1/24 dev h1-eth1 table 5001")
h1.cmd("ip route add default via 10.0.3.2 dev h1-eth1 table 5001")
h1.cmd("ip rule add from 10.0.1.1 table 5000")
h1.cmd("ip rule add from 10.0.3.1 table 5001")
h1.cmd("ip route add default gw 10.0.1.2 dev h1-eth0")
#that be a must or else a tcp client would not know how to route packet out
h1.cmd("route add default gw 10.0.1.2 dev h1-eth0") #would not work for the second part when a tcp client bind a address
r1.cmd("ifconfig r1-eth0 10.0.1.2/24")
r1.cmd("ifconfig r1-eth1 10.0.2.1/24")
r1.cmd("ip route add to 10.0.1.0/24 via 10.0.1.1")
r1.cmd("ip route add to 10.0.2.0/24 via 10.0.2.2")
r1.cmd("ip route add to 10.0.5.0/24 via 10.0.2.2")
r1.cmd('sysctl net.ipv4.ip_forward=1')
r3.cmd("ifconfig r3-eth0 10.0.2.2/24")
r3.cmd("ifconfig r3-eth1 10.0.5.1/24")
r3.cmd("ifconfig r3-eth2 10.0.4.2/24")
r3.cmd("ip route add to 10.0.1.0/24 via 10.0.2.1")
r3.cmd("ip route add to 10.0.2.0/24 via 10.0.2.1")
r3.cmd("ip route add to 10.0.5.0/24 via 10.0.5.2")
r3.cmd("ip route add to 10.0.4.0/24 via 10.0.4.1")
r3.cmd("ip route add to 10.0.3.0/24 via 10.0.4.1")
r3.cmd('sysctl net.ipv4.ip_forward=1')
r2.cmd("ifconfig r2-eth0 10.0.3.2/24")
r2.cmd("ifconfig r2-eth1 10.0.4.1/24")
r2.cmd("ip route add to 10.0.3.0/24 via 10.0.3.1")
r2.cmd("ip route add to 10.0.4.0/24 via 10.0.4.2")
r2.cmd("ip route add to 10.0.5.0/24 via 10.0.4.2")
r2.cmd('sysctl net.ipv4.ip_forward=1')
h2.cmd("ifconfig h2-eth0 10.0.5.2/24")
h2.cmd("route add default gw 10.0.5.1")
#ping -I src dst
net.start()
time.sleep(1)
CLI(net)
net.stop()
print "stop"
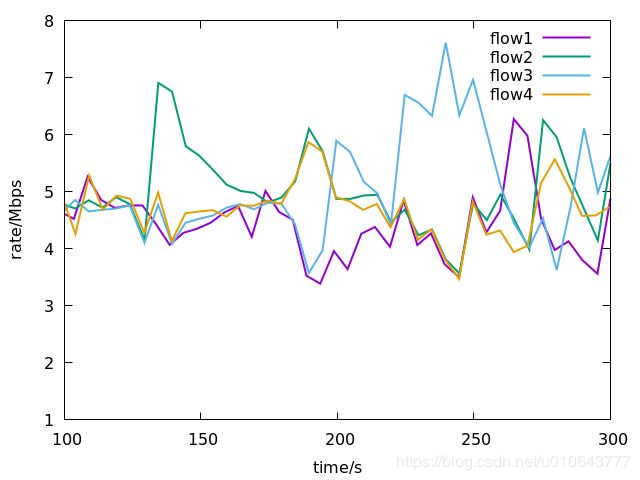
路径p1,h1(10.0.1.1)到h2,25个TCP连接,编号1-25;路径p2,h1(10.0.3.1)到h2,25个TCP连接,编号26-50。 代码下载地址[1]。
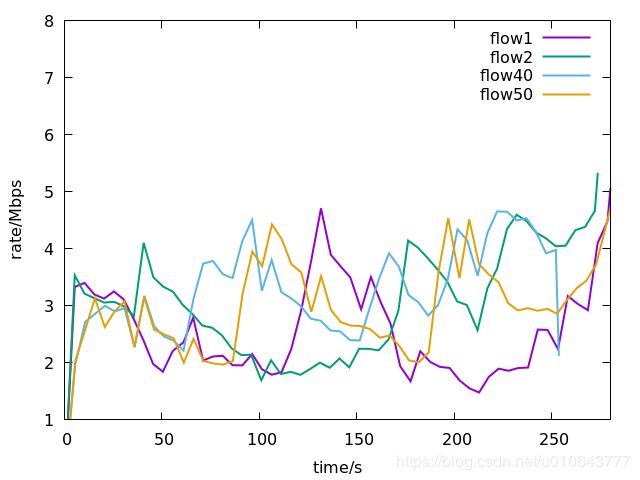
所有的流均采用BBR算法。BBR的特性还是很明显的,数据流在传输时延大的路径p2可以获取更多的吞吐量。
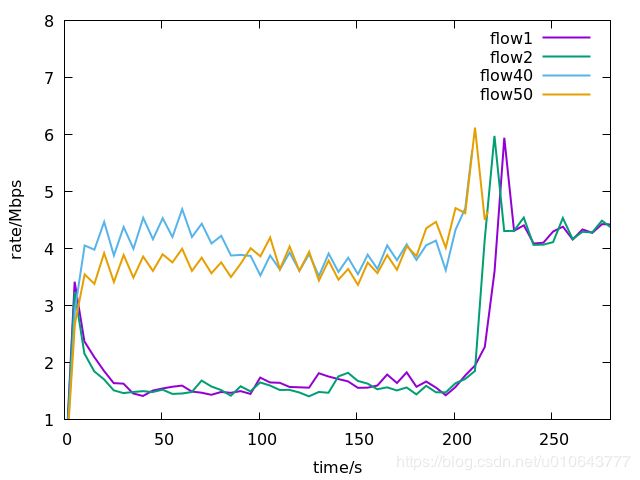
所有的流均采用Reno算法:
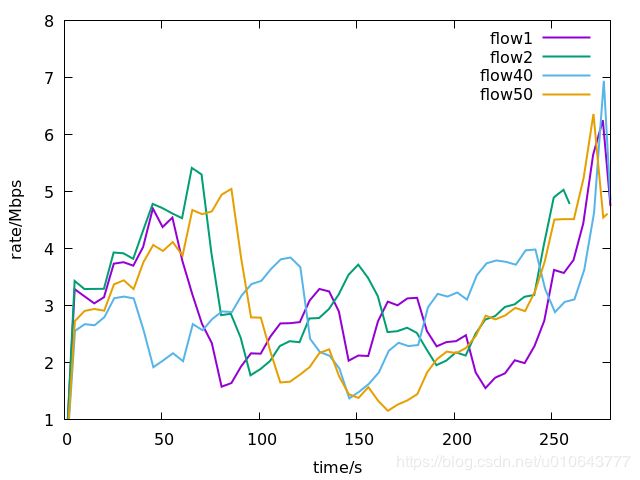
所有的流均采用Cubic算法:
另外发现,在socket非阻塞模式,调用write函数,不能保证全部写入。代码标号1处,会出现written_bytesint TcpClient::WriteMessage(const char *msg, int len){
int written_bytes=0;
if(sockfd_<=0){
return written_bytes;
}
//1
written_bytes=write(sockfd_,msg,len);
if(written_bytes<=0){
if(errno == EWOULDBLOCK || errno == EAGAIN){
written_bytes=0;
}else{
written_bytes=0;
LOG(INFO)<<"write error "<
[1] tcp-congestion-mininet