C语言基础知识
<>引用的是“官方”头文件如stdio.h,""引用的是你自己写的“民间”头文件如my.h。
- 静态局部变量存储在静态区,普通局部变量存储在栈区。
- 静态局部变量未初始化时,系统自动置0;初始化仅在函数初次调用时进行一次。
- 静态局部变量在函数结束时不会释放,其生存期为整个程序运行期,并能保存上次调用的值。
#include
int main(){
int a=1;
int b=2;
const int *p1=&a; //常量指针p1
int* const p2=&b; //指针常量p2
printf("%d:\n",*p1);
p1=&b; //常量指针指(*P)不可变,但p可变
//p2=&a; 错误,p2为指针常量,p2这个指针是常量,故p2不能修改
printf("%d:\n",*p1);
return 0;
} #include
int Sub(int a,int b){ //定义减法操作函数
return (a-b);
}
int Add(int a,int b) //定义加法操作函数
{
return (a+b);
}
int main()
{
int (*p)(int,int); //定义函数指针
p=Sub;
printf("a-b=%d \n",p(100,3));//调用函数Sub()
p=Add;
printf("a+b=%d \n",p(100,3));//调用函数Add()
return 0;
}
C语言之回调函数
1、什么是回调函数?
回调函数:见名知意,首先肯定的一点是它是一个函数,修饰词回调指的是程序员自己定义一个函数并实现它的程序内容,然后把这个函数的指针作为参数传递给其他函数(如系统函数)中,由其他函数(如系统函数)在运行时调用所实现的函数。函数是程序员自己实现的,但却是由其他函数(如系统函数)在运行时通过参数传递的方式调用的,这就是回调函数。简单一句话就是:由别人的函数运行期间来回调你实现的函数。
回调函数该如何使用?
int fun1(void)
{
printf("hello world.\n");
return 0;
}
void callback(int (*Pfun)())
{
Pfun();
}
int
main(void)
{
callback(fun1);
} callback回调定义的函数fun1,传递给callback的是函数fun1的地址
int fun2(char *s)
{
printf("%s.\n", s);
return 0;
}
void callback(int (*Pfun)(char *), char *s)
{
Pfun(s);
}
int
main(void)
{
callback(fun2, "hello world");
return 0;
}
两者区别:
区别一
for(;;)死循环里的两个;;代表两个空语句,编译器一般会优化掉它们,直接进入循环体。
while(1)死循环里的1被看成表达式,每循环一次都要判断常量1是不是等于零。
区别二
同样的代码,编译出的程序代码大小不同。
static
(一)
当它用于函数定义时,或用于代码块之外的变量声明时,static关键字用于修改标示符的链接属性,从externl改为internal。
(二)
当它用于代码块内部的变量声明时,static关键字用于修改变量的存储类型,从自动变量修改为静态变量,但变量的链接属性和作用域不受影响。
用这种方式声明的变量在程序执行之前创建,并在程序的整个执行期间一直存在,而不是每次在代码块开始执行时创建,在代码块执行完毕后销毁。
main.c源码
#include
#include "test.h"
void main(void)
{
fun(); /*fun函数就是在test.c文件中声明的函数*/
printf("j = %d\n", j);/*j变量也是在test.c文件中声明的变量*/
} test.c源码
#include
static int i = 1;/*声明为内部变量,只能用于test.c源文件*/
int j = 2;/*可以作为外部变量使用,在main文件中用到了*/
static void fun1(void)/*声明为内部函数,只能用在test.c源文件中*/
{
printf("i+1 = %d, j+1 = %d\n", i+1, j+1);
}
void fun(void)/*可以用在其他文件中,用在main文件中*/
{
printf("i = %d, j = %d\n", i, j);
fun1();
} test.h源码
extern int j;
extern void fun(void); 显示结果如下:
i = 1, j = 2//该行是由main函数里调用的test.c文件中的fun函数生成的
i+1 = 2, j+1 = 3//该行是由test文件中fun函数调用的fun1函数生成的
j = 2//这是由main函数使用外部变量j直接生成的
堆与栈的深入理解
程序=数据结构+算法
| 代码区 |
| 静态区 |
| 堆 |
| 空闲内存 |
| 栈 |

有人说不能在printf中使用%lf,为什么printf中用%f输出double型,而scanf却用%lf呢?
- sscanf(str,"%d%3s%f",&i,s,&f);
- printf("%d,%s,%f\n",i,s,f);
1.文件:
1.1文件路径:文件在外部存储设备中的位置
1.2文件名:文件的标识名
1.3文件扩展名:标识文件的格式
2.1打开文件fopen():通过这个函数可以打开一个文件,用法:
文件指针名=fopen(文件名,打开文件方式)
文件打开方式,"w"代表以只读的方式打开一个二进制文件,这类参数还有:
r : 打开一个文本文件,只允许读数据
rb : 打开一个二进制文件,只允许读数据
w : 打开一个文本文件,只允许写数据
wb :打开一个二进制文件,只允许写数据
2.2关闭文件fclose():这个函数用来关闭一个文件,其用法为:
fclose(文件指针)
指针扮演一个什么样的角色?存储在静态区的全局变量与静态变量,栈区的局部变量

- 用法:malloc(int size) ,size为需要开辟的字节数。
- 返回值:开辟空间的首地址。
- 用法:free(void *p) , p为指向开辟空间的指针
- 返回值:无返回值。
链表可以更好的适应实时变化的存储需求,具有无限的扩展性,然而你并不需要担心是否有足够连续的内存。
- 连续内存约束:数组的内存必须是连续的,当存储数据量达到一定程度,开辟数组空间可能面临一个严重的问题-内存中找不到足够大的连续内存。链表不需要连续的内存,它可以将零散的内存串起来,不断的延伸表的长度。
- 插入与删除:数组的插入与删除需要移动大量的数据,并且在时间的消耗上具有不定性,在数据实时变化的情况下,数组的效率非常低下。链表的删除与插入只需操作几个指针,具有固定的时间消耗,相当高的效率。
- 更好的适用性:即使是动态开辟的数组,如果遇到更大的存储需求,就必须重新开辟更大的数组并复制数据。链表在几乎可以满足任何大小,不断变化的存储需求。

1.链表的插入:将新的节点插入到链表指定的位置。
等待插入的新节点(p),插入链表两个节点之间(左边为p1,右边为p2)
2.链表的删除: 将一个节点从链表删除。
删除节点P,只需要把P1的指针指向P2,P便不在属于链表了
P1->next=P->next;
3.链表的查询:遍历链表查找满足特定要求的节点
#include
#include
//************
//定义链表节点
//************
struct Node{
int id; //id为学号,Score为成绩
int Score; //id,Score为数据区
struct Node * next; //指针next,指向下一个节点,故类型为Node *
};
//************
//定义链表头
//************
Node *Head;
int main(){
Node *temp;
Node *p1;
Node *p2;
Head=(Node *)malloc(sizeof(Node));
if(Head!=NULL){ //检查是否申请空间成功
Head->next=NULL; //只有头节点,故此时指向空NULL
Head->id=0; //赋值id
Head->Score=0; //赋值Score,一般而言,头节点不用于存储数据,此处均象征性赋值为0
}
printf("现在创建含4带个节点的链表:\n");
for(int i=0;i<4;i++){
//************
//新建一个节点并赋值
//************
temp=(Node *)malloc(sizeof(Node));
if(temp!=NULL){ //检查是否申请空间成功
temp->next=NULL;
printf("请输入id与Score:\n");
scanf("%d %d",&temp->id,&temp->Score);
}
//************
//将节点添加到链表末尾
//************
p1=Head;
while(p1->next!=NULL)
{
p1=p1->next; //找到链表的末尾
}
p1->next=temp; //将节添加到链表的末尾
//printf("*****%d",Head->next->id);
}
printf("现在输出链表中的4个节点:\n");
//************
//输出链表
//************
p1=Head->next;
while(p1!=NULL){
printf("id为%d,成绩为%d\n",p1->id,p1->Score);
p1=p1->next;
}
//*********
//查找节点
//*********
printf("请输入你要查找的学生id:\n");
int tempid;
scanf("%d",&tempid);
p1=Head->next;
while(p1!=NULL) //到链表末尾或找到该id则停止循环
{
if(p1->id==tempid) break;
p1=p1->next;
}
if(p1!=NULL){ //如果不是到链表末尾,当然就是找到该id
printf("找到该id学生,其分数为%d:\n",p1->Score);
}
else{ //到末尾了,说明该id没找到
printf("没有找到该id的学生\n");
}
//**********
//删除节点
//**********
printf("请输入你要删除的学生id:\n");
scanf("%d",&tempid);
p1=Head;
while(p1!=NULL)
{
if(p1->id==tempid) break;
p2=p1; //记录要删除节点的上一个加点
p1=p1->next;
}
if(p1!=NULL){
p2->next=p1->next; //删除的核心代码
free(p1);
}
else{
printf("没有找到该id的学生\n");
}
//************
//输出链表
//************
p1=Head->next; //用于验证是否删除成功
while(p1!=NULL){
printf("id为%d,成绩为%d\n",p1->id,p1->Score);
p1=p1->next;
}
return 0;
}
Windows下远程登录到Linux -- 以Win7,Ubuntu12.04LTS,SSH 为例
引言:
Linux大多应用于服务器,而服务器不可能像PC一样躺在办公室里,它们是放在IDC机房的,所以我们平时登录Linux系统都是通过远程登录的。Linux系统中是通过ssh服务实现的远程登录功能。默认ssh服务开启了22端口,而且当我们安装完系统时,这个服务已经安装,并且是开机启动的。所以不需要我们额外配置什么就能直接远程登录linux系统。
Ssh服务的配置文件为/etc/ssh/sshd_config,你可以修改这个配置文件来实现你想要的ssh服务。比如你可以更改启动端口为36000.
为什么不用Telnet?telnet因为采用明文传送报文,安全性不好,很多Linux服务器都不开放telnet服务,而改用更安全的ssh方式了。
http://blog.csdn.net/zjf280441589/article/details/17408991
1、ssh的安装
2、生成密钥
3、修改配置文件
将Linux作为:
1.开发平台
2.服务器
在Windows平台学习的话,一但涉及到底层的东西,你就会发现很难深入
附:美女的比喻:
Linux就好像是一个极富内涵的美女,不光外表漂亮,而且富有感染力,她会毫不隐藏自己的优点,缺点,然你去自己的品味,欣赏她,以至于深入的了解她,她甚至会为了你而去改变她自己!!
而Windows则更像一位贵妇,虽然外表很漂亮,很有吸引力,但是,万一你要是紧盯着她,她就会说:看什么呢,丑流氓,再看我报警了!!!
作为程序员,有两种方式快速的提高
1)不断的写代码
2)不断的看别人的代码
解决问题的智慧:
注意系统的英文提示信息,以及系统的文档,示例;
提问前,首先自己分析,学习。
互联网,教材,论坛的检索;#Google.combaidu.com提问的智慧!
整理好自己得学习笔记!
学习大纲:
1、文件处理命令
2、权限管理命令
3、文件搜索命令
4、帮助命令
5、压缩解压缩命令
6、网络通信命令
7、系统开关机命令
8、Shell应用技巧
只有root才能执行的命令
/sbin 或/usr/sbin
所用用户都可执行的命令
/bin或 /usr/bin
选项: -a all
-l long 详细信息
-d directory 查看目录属性
r:read读权限
w:write写权限
x:execute执行权限
用户也分为三种:
1、所有者U:user
2、所属组G:group
3、其他人O:others
Linux很多的大小是用数据块来表示:block,其单位512字节,但其 大小可根据实际应用进行调节。
数据块可以理解为:存储数据的最小单位。
2、cd [change directory]
cd [目录]
e.g.
ch / 切换到根目录
cd.. 切换到上级目录
3、pwd [printworking directory] /bin/pwd
4、touch:创建文件 /bin/touch
touch[文件名]
5、mkdir [makedirectories] :创建目录
mkdir [目录名]
mkdir /test
//mkdir test :在当前目录下创建目录
6、cp[copy]:复制文件或目录 /bin/cp
cp-R [复制目录]
//如果复制的是文件的话,就不用加-R,并且文件数不做限制
附: etc目录下保存的大多是配置文件。
Ctrl+c:终止程序运行
7、mv[move]:移动文件,更名 /bin/mv 类似与剪切、重命名
mv[源文件或目录][目的目录]
e.g.
mv servers ser 改名
mv /test/ser /tmp 移动
mv /test/testfile /tmp/file.test 移动并改名
8、rm[remove]:删除文件 /bin/rm
rm -r [文件或目录]
rm只能用来删除文件,要想删除目录,则要加上-r即可,有时候会很烦人。。。
但是如果你十分确定这个文件目录确实应该删除,则加上-rf即可
如果不想弹出确认信息,则加上 -f选项【force】,并不推荐,不同与UNIX
8.1rmdir 用来删除空目录,不常用
9、cat[concatenateand diplay files] /bin/cat
比较适用于文件内容不是很长的文件
cat[文件名]
10、more /bin/more
分页显示文件内容
命令:
f或Space 翻页
Q或q 退出
Enter 下一行
e.g. more /etc/servies
11、head /bin/head
查看文件的前几行
head -num [文件名]// 不加数字默认看10行
e.g. head -20 /etc/servirs
12、tail/bin/tail
查看文件的后几行
tail -num [文件名]
-f 动态显示文件内容
13、ln[link]: /bin/ln
产生链接文件。
语法: 产生硬链接 不需要加任何选项,直接生成
ln[源文件][目标文件]
产生软链接 需要加-s[soft]
ls-s [源文件][目标文件]
附: 为什么他可以同步更新
ls -i i[inode] i节点实际上就是一个数字标识,因为Linux 不认识字符!在Linux里面处理任何东西,都要有一个数字标识。所以,所有文件必须要有i节点!
对象是类的实例,相对抽象地类,对象是具体的实体
对象是类的实例。类是生成对象的”模板“
字符串常量
"acb132"
字符串常量就是字符数组,内部以'\0'结尾
枚举常量
默认第一个枚举名的值为0,第二个为1,类推,
外部变量与静态变量默认初始值为0
自动变量的默认初始化为未定义值(为垃圾)
#include
void swap(int *a,int *b)
{
int *t;
t=a;
a=b;
b=t;
}
int main()
{
int a=10,b=20;
int *pa,*pb;
pa=&a;
pb=&b;
printf("%d %d ",*pa,*pb);
swap(pa,pb);
printf("%d %d ",*pa,*pb);
}
上面输出10 20 10 20
简单的函数传值 传址问题。。。
给的是地址 把地址当成常量传值 地址这个量进行交换 返回回来输出不变
更改下swap函数
void swap(int *a,int *b)
{
int t;
t=*a;
*a=*b;
*b=t;
}
输出:10 20 20 10
给的是地址 传过去是地址。把地址中的值交换了 所以返回输出值交换了
extern
外部变量定义在 文件中间 ,在调用它的 函数的下面 ,必须使用 extern声明声明变量在外部定义
例1:外部变量定义在文件开头,在调用它的函数的上面,extern可省略
主文件使用从文件里的外部变量,extern可以省略
从文件使用主文件的外部变量,必须使用extern声明
C++
1)构造函数用来对类的数据成员进行初始化,析构函数用来释放已经实例化的对象。
一个类除了需要定义一般的构造函数外,还要定义拷贝、赋值、析构三大函数;
缓冲区:
每个输出流都管理一个缓冲区,用来保存读写的数据。导致缓冲区的刷新原因:
- 程序正常结束,作为main函数的return操作的一部分,缓冲被刷新
- 缓冲区满,刷新缓冲区
- 操作符endl可以用来显示的刷新缓冲区
- 默认情况下,写到ceer的内容都是立即刷新的
- 一个输出流可能被关联到另一个流,此时缓冲区会被刷新
- cout << "scott" << endl;//输出scott和一个换行符,然后刷新缓冲区
- cout << "scott" << flush;//输出scott 然后刷新缓冲区
- cout << "scott" << ends;//输出scott和一个空字符 然后刷新缓冲区
STL(Standard Template Library)
标准模板库。从根本上说,STL是一些“容器”的集合,这些“容器”有list, vector,set,map等,
STL也是算法和其它一些组件的集合。这里的“容器”和算法的集合指的是世界上很多聪明人很多年的杰作。每一个C++程序员都应该好好学习STL。
大体上包括container(容器)、algorithm(算法)和iterator(迭代器),容器和算法通过迭代器可以进行无缝连接。
2.顺序容器:
vector 可变大小数组。支持快速随机访问。在尾部之外的位置插入/删除元素速度可能很慢。
deque 双端队列。支持快速随机访问。在头尾插入/删除元素速度很快。
list 双向链表。只支持双向顺序访问。在list任何位置插入/删除速度都很快。
string 与vector类似。
添加元素:
c.pusk_back(t) 在c尾部加入元素t——list、deque、vector支持
c.push_front(t) 在c头部加入元素t ——list、deque支持,vector不支持。
c.insert(p, t) 在迭代器p指向的元素之前创建一个值为t的元素,返回指向新元素的迭代器。
c.insert(p, n, t) 在迭代器p指向的元素之前插入n个值为t的元素,返回指向新添加第一个元素的迭代器。
c.insert(p, b, e)将迭代器b和e指定的范围内的元素插入到迭代器p指向的元素之前。
删除元素:
c.pop_back() 删除c中尾元素
c.pop_front() 删除c中首元素——同样,vector不支持
c.erase(p) 删除迭代器p指向的元素,返回一个执行被删元素之后元素的迭代器
c.erase(b, e) 删除迭代器b、e范围内元素
c.clear() 删除c中所有元素
3.迭代器
迭代器范围:一个左闭右开区间[begin, end);
iterator、const_iterator、reverse_iterator、const_reverse_iterator;
- vector<int> vec(10);//vec含10个元素,每个元素都是0
- vector<int>::iterator i = vec.begin();//获取指向第一个元素的迭代器。
- *i = 10;//解引用可以作为左值改变容器中的值
1.泛型算法
find函数用于找出容器中一个特定的值,有三个参数
- int val = 10;//val为我们需要查找的值
- auto result = find(vec.begin(), vec.end(), val):
count函数用来统计容器中元素个数
count(str.begin(), str.end(), val);
accumulate函数定义在numeric头文件中,用于统计指定迭代器范围内元素的和。
第三个参数是和的初值,用一般为0.
int num = accumulate(vec.begin(), vec.end(), 0);
fill函数用来向给定范围内容器写入数据。
fill(v.begin(), v.end(), 0); //将每个元素置为0
sort(words.begin(), words.end());
关联容器
与顺序容器不同,关联容器的元素是按关键字来访问和保存的。而顺序容器中的元素是按他们在容器中的位置来顺序保存的。
关联容器最常见的是map、set、multimap、multiset
map的元素以键-值【key-value】对的形式组织:键用作元素在map中的索引,而值则表示所存储和读取的数据。
set仅包含一个键,并有效的支持关于某个键是否存在的查询。
pair类型
首先介绍下pair,pair定义在utility头文件中,
一个pair保存两个数据成员,类似容器,pair是一个用来生成特点类型的模板。
当创建一个pair时,我们必须提供两个类型名。
pair
pair
可以使用make_pair来构建一个pair
查找与统计map中的元素:
1、使用m.count(k); 统计m中k出现的次数
2、使用m.find(k);查找以k为索引的元素,如果存在返回指向该元素的迭代器,否则返回末端迭代器
动态内存
C++中,动态内存管理是通过一对运算符完成的:new和delete。
C语言中通过malloc与free函数来实现先动态内存的分配与释放
2.智能指针
由于 C++ 语言没有自动内存回收机制,每次 new 出来的内存都要手动 delete。程序员忘记 delete,流程太复杂,最终导致没有 delete,异常导致程序过早退出,没有执行 delete 的情况并不罕见。
用智能指针便可以有效缓解这类问题
C++11新标准提供了两种智能指针,负责自动释放所指向的对象。
shared_ptr允许多个指针指向同一个对象;unique_ptr则"独占"所指向的对象。
标准库还定义了一个名为weak_ptr的伴随类;这三种类型都定义在memory头文件中。
对于编译器来说,智能指针实际上是一个栈对象,并非指针类型,在栈对象生命期即将结束时,智能指针通过析构函数释放有它管理的堆内存。所有智能指针都重载了“operator->”操作符,直接返回对象的引用,用以操作对象。访问智能指针原来的方法则使用“.”操作符。
访问智能指针包含的裸指针则可以用 get() 函数。由于智能指针是一个对象,所以if (my_smart_object)永远为真,要判断智能指针的裸指针是否为空,需要这样判断:if (my_smart_object.get())。
智能指针包含了 reset() 方法,如果不传递参数(或者传递 NULL),则智能指针会释放当前管理的内存。如果传递一个对象,则智能指针会释放当前对象,来管理新传入的对象。
深拷贝与浅拷贝:
>浅拷贝: 指的是在对象复制时,只对对象中的数据成员进行简单的赋值;默认拷贝构造函数执行的也是浅拷贝。 大多情况下“浅拷贝”已经能很好地工作了,但是一旦对象存在了动态成员,那么浅拷贝就会出问题了。
>深拷贝:当类的成员变量有指针类型时,拷贝对象时应该为指针变量重新分配好空间,避免浅拷贝中只拷贝指针的 值,使得两个指针指向同一块内存空间。
对象是类的实例,相对抽象地类,对象是具体的实体
对象是类的实例。类是生成对象的”模板“
字符串常量
"acb132"
字符串常量就是字符数组,内部以'\0'结尾
枚举常量
默认第一个枚举名的值为0,第二个为1,类推,
外部变量与静态变量默认初始值为0
自动变量的默认初始化为未定义值(为垃圾)
#include
void swap(int *a,int *b)
{
int *t;
t=a;
a=b;
b=t;
}
int main()
{
int a=10,b=20;
int *pa,*pb;
pa=&a;
pb=&b;
printf("%d %d ",*pa,*pb);
swap(pa,pb);
printf("%d %d ",*pa,*pb);
}
上面输出10 20 10 20
简单的函数传值 传址问题。。。
给的是地址 把地址当成常量传值 地址这个量进行交换 返回回来输出不变
更改下swap函数
void swap(int *a,int *b)
{
int t;
t=*a;
*a=*b;
*b=t;
}
输出:10 20 20 10
给的是地址 传过去是地址。把地址中的值交换了 所以返回输出值交换了
extern
外部变量定义在 文件中间 ,在调用它的 函数的下面 ,必须使用 extern声明声明变量在外部定义
例1:外部变量定义在文件开头,在调用它的函数的上面,extern可省略
主文件使用从文件里的外部变量,extern可以省略
从文件使用主文件的外部变量,必须使用extern声明
C++
1)构造函数用来对类的数据成员进行初始化,析构函数用来释放已经实例化的对象。
一个类除了需要定义一般的构造函数外,还要定义拷贝、赋值、析构三大函数;
缓冲区:
每个输出流都管理一个缓冲区,用来保存读写的数据。导致缓冲区的刷新原因:
- 程序正常结束,作为main函数的return操作的一部分,缓冲被刷新
- 缓冲区满,刷新缓冲区
- 操作符endl可以用来显示的刷新缓冲区
- 默认情况下,写到ceer的内容都是立即刷新的
- 一个输出流可能被关联到另一个流,此时缓冲区会被刷新
- cout << "scott" << endl;//输出scott和一个换行符,然后刷新缓冲区
- cout << "scott" << flush;//输出scott 然后刷新缓冲区
- cout << "scott" << ends;//输出scott和一个空字符 然后刷新缓冲区
STL(Standard Template Library)
标准模板库。从根本上说,STL是一些“容器”的集合,这些“容器”有list, vector,set,map等,
STL也是算法和其它一些组件的集合。这里的“容器”和算法的集合指的是世界上很多聪明人很多年的杰作。每一个C++程序员都应该好好学习STL。
大体上包括container(容器)、algorithm(算法)和iterator(迭代器),容器和算法通过迭代器可以进行无缝连接。
2.顺序容器:
vector 可变大小数组。支持快速随机访问。在尾部之外的位置插入/删除元素速度可能很慢。
deque 双端队列。支持快速随机访问。在头尾插入/删除元素速度很快。
list 双向链表。只支持双向顺序访问。在list任何位置插入/删除速度都很快。
string 与vector类似。
添加元素:
c.pusk_back(t) 在c尾部加入元素t——list、deque、vector支持
c.push_front(t) 在c头部加入元素t ——list、deque支持,vector不支持。
c.insert(p, t) 在迭代器p指向的元素之前创建一个值为t的元素,返回指向新元素的迭代器。
c.insert(p, n, t) 在迭代器p指向的元素之前插入n个值为t的元素,返回指向新添加第一个元素的迭代器。
c.insert(p, b, e)将迭代器b和e指定的范围内的元素插入到迭代器p指向的元素之前。
删除元素:
c.pop_back() 删除c中尾元素
c.pop_front() 删除c中首元素——同样,vector不支持
c.erase(p) 删除迭代器p指向的元素,返回一个执行被删元素之后元素的迭代器
c.erase(b, e) 删除迭代器b、e范围内元素
c.clear() 删除c中所有元素
3.迭代器
迭代器范围:一个左闭右开区间[begin, end);
iterator、const_iterator、reverse_iterator、const_reverse_iterator;
- vector<int> vec(10);//vec含10个元素,每个元素都是0
- vector<int>::iterator i = vec.begin();//获取指向第一个元素的迭代器。
- *i = 10;//解引用可以作为左值改变容器中的值
1.泛型算法
find函数用于找出容器中一个特定的值,有三个参数
- int val = 10;//val为我们需要查找的值
- auto result = find(vec.begin(), vec.end(), val):
count函数用来统计容器中元素个数
count(str.begin(), str.end(), val);
accumulate函数定义在numeric头文件中,用于统计指定迭代器范围内元素的和。
第三个参数是和的初值,用一般为0.
int num = accumulate(vec.begin(), vec.end(), 0);
fill函数用来向给定范围内容器写入数据。
fill(v.begin(), v.end(), 0); //将每个元素置为0
sort(words.begin(), words.end());
关联容器
与顺序容器不同,关联容器的元素是按关键字来访问和保存的。而顺序容器中的元素是按他们在容器中的位置来顺序保存的。
关联容器最常见的是map、set、multimap、multiset
map的元素以键-值【key-value】对的形式组织:键用作元素在map中的索引,而值则表示所存储和读取的数据。
set仅包含一个键,并有效的支持关于某个键是否存在的查询。
pair类型
首先介绍下pair,pair定义在utility头文件中,
一个pair保存两个数据成员,类似容器,pair是一个用来生成特点类型的模板。
当创建一个pair时,我们必须提供两个类型名。
pair
pair
可以使用make_pair来构建一个pair
查找与统计map中的元素:
1、使用m.count(k); 统计m中k出现的次数
2、使用m.find(k);查找以k为索引的元素,如果存在返回指向该元素的迭代器,否则返回末端迭代器
动态内存
C++中,动态内存管理是通过一对运算符完成的:new和delete。
C语言中通过malloc与free函数来实现先动态内存的分配与释放
2.智能指针
由于 C++ 语言没有自动内存回收机制,每次 new 出来的内存都要手动 delete。程序员忘记 delete,流程太复杂,最终导致没有 delete,异常导致程序过早退出,没有执行 delete 的情况并不罕见。
用智能指针便可以有效缓解这类问题
C++11新标准提供了两种智能指针,负责自动释放所指向的对象。
shared_ptr允许多个指针指向同一个对象;unique_ptr则"独占"所指向的对象。
标准库还定义了一个名为weak_ptr的伴随类;这三种类型都定义在memory头文件中。
对于编译器来说,智能指针实际上是一个栈对象,并非指针类型,在栈对象生命期即将结束时,智能指针通过析构函数释放有它管理的堆内存。所有智能指针都重载了“operator->”操作符,直接返回对象的引用,用以操作对象。访问智能指针原来的方法则使用“.”操作符。
访问智能指针包含的裸指针则可以用 get() 函数。由于智能指针是一个对象,所以if (my_smart_object)永远为真,要判断智能指针的裸指针是否为空,需要这样判断:if (my_smart_object.get())。
智能指针包含了 reset() 方法,如果不传递参数(或者传递 NULL),则智能指针会释放当前管理的内存。如果传递一个对象,则智能指针会释放当前对象,来管理新传入的对象。
深拷贝与浅拷贝:
>浅拷贝: 指的是在对象复制时,只对对象中的数据成员进行简单的赋值;默认拷贝构造函数执行的也是浅拷贝。 大多情况下“浅拷贝”已经能很好地工作了,但是一旦对象存在了动态成员,那么浅拷贝就会出问题了。
>深拷贝:当类的成员变量有指针类型时,拷贝对象时应该为指针变量重新分配好空间,避免浅拷贝中只拷贝指针的 值,使得两个指针指向同一块内存空间。
可变参数函数指可以接受可变数量参数的函数。比如printf函数就是一个可变参数函数。
要完成可变参数函数的编写,需要用到定义于stdarg.h头文件中的一个类型va_list和三个宏va_start、va_arg、va_end。
va_list类型用于声明一个变量,该变量将依次引用各参数。
va_start宏将va_list声明的变量初始化为指向第一个无名参数的指针。在使用变量之前,该宏必须被调用一次。参数表必须至少包括一个有名参数,va_start将最后一个有名参数作为起点。
va_arg宏,调用该宏,该函数都将返回一个参数,并将声明的变量指向下一个参数。va_arg使用一个类型名来决定返回的对象类型、指针移动的步长。
va_end宏,该宏必须在函数返回之前调用,以完成一些必要的清理工作。
通常要在函数内部实现跳转,会用到goto语句。如果想要实现不同函数间的跳转,就要用到setjmp和longjmp语句的组合来完成。
理论分析:
setjmp和longjmp组合可以实现跳转,与goto语句有相似的地方。但有以下不同:
1、用longjmp只能跳回到曾经到过的地方。在执行setjmp的地方仍留有一个过程活动记录。从这个角度看,longjmp更像是“从何处来”而不是“往何处去”。longjmp接收一个额外的整型参数并返回它的值
2、goto语句不能跳出C语言当前的函数,而longjmp可以跳的更远,可以跳出函数,甚至跳到其他文件中的函数中。
setjmp(jmp_buf j)必须首先被调用。它表示“使用变量j记录现在的位置”。函数返回零。
longjmp(jmp_buf j, int i)可以接着被调用。它表示“回到j所记录的位置,让它看上去像从原先的setjmp函数返回一样。函数返回i。”
setjmp/longjmp最大的用途是错误恢复。但跟goto一样,使得程序难以理解和调试。如果不是出于特殊需要,最好避免使用它们。
使用步骤:
1、包含头文件setjmp.h,定义jmp_buf类型的变量,如jmp_buf buf;
2、调用setjmp(buf);该函数返回0。
3、在想要跳转的地方调用longjmp(buf, i);该函数返回整数i,实现跳转。

运行结果:
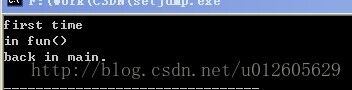
指针:
指针变量一定要先进行初始化,然后才能使用。
初始化指要对指针变量进行赋值,将一个地址值赋值给指针变量。极为常犯的错误是:
int *a;
*a = 12; /*未对它进行初始化,没有办法预测12这个值将存储于什么地方*/
关于字符串:
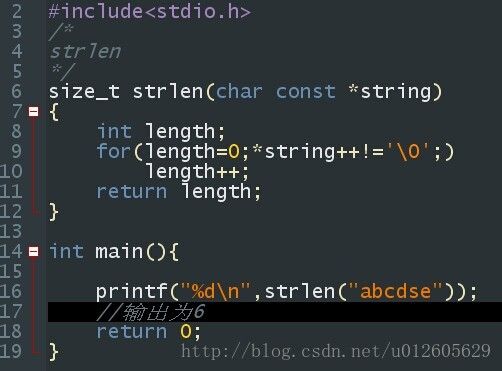
1、字符串的长度
strlen返回一个类型为size_t的值,它是一个无符号整数类型。
在表达式中使用无符号数可能导致不可预料的结果。
if(strlen(x) >= strlen(y)) 正常
if(strlen(x) - strlen(y) >= 0) /*永远为真,strlen的结果是个无符号数,所以操作符>=左边的表达式也将是无符号数*/
strlen:
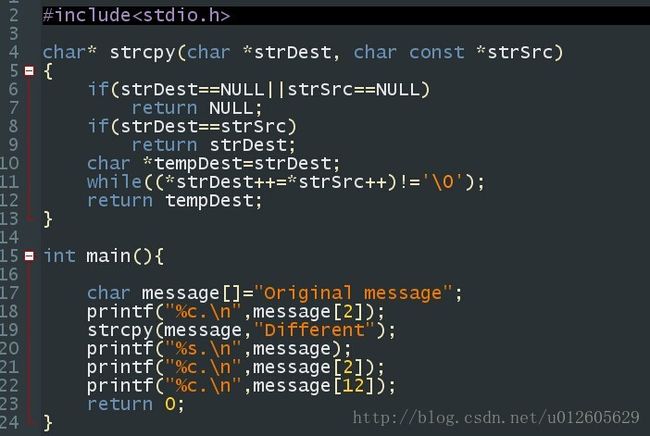
char *strcpy(char *dst, char const *src); 它把参数src字符串复制到dst参数。
dst参数的以前内容将被覆盖掉并丢失。
即使新的字符串比dst原先的内存更短,由于新字符串以NUL字节结尾,所以老字符串最后剩余的几个字符也会被有效地删除,(其实并为被删除,可以使用地址访问)。
显示的结果:

3、连接字符串:把一个字符串添加(连接)到另一个字符串的后面。
原型:char *strcat(char *dst, char const *src); 该函数要求dst参数原先已经包含了一个字符串,它找到这个字符串的末尾,并把src字符串的一份拷贝添加到这个位置。同样应该确保目标字符数组剩余的空间足以保存整个源字符串。

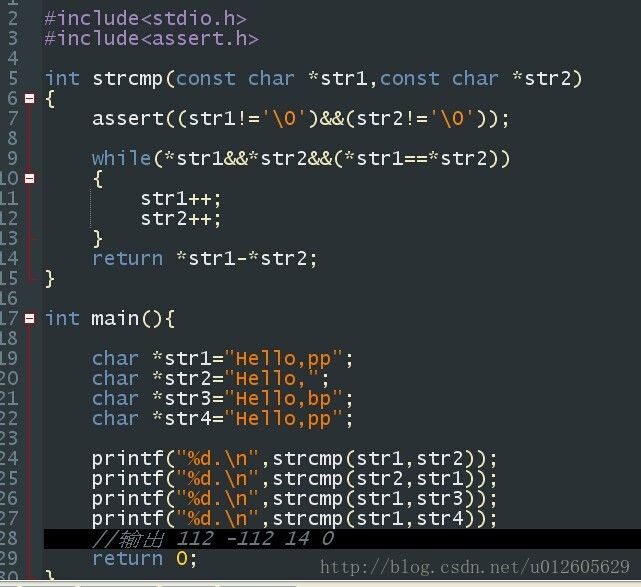
4、字符串比较:比较两个字符串涉及对两个字符串对应的字符逐个进行比较,直到发现不匹配为止。
原型:int strcmp(char const *s1, char const *s2);
如果s1小于s2,返回值小于0;
如果s1大于s2,返回值大于0;
如果s1等于s2,返回值等于0;
5、其他字符串函数
char *strncpy(char *dst, char const *src, size_t len);
向dst写入len个字符。如果strlen(src)的值小于len,dst数组就用额外的NUL字节填充到len长度。
如果strlen(src)的值大于或等于len,那么只有len个字符被复制到dst中。注意,它的结果将不会以NUL字节结尾。
源码跟4有关系 ;
char *strncat(char *dst, char const *src, size_t len);
int strncmp(char const *s1, char const *s2, size_t len);
动态内存分配
一块内存的生命周期可以分为四个阶段:分配、初始化、使用、释放。
malloc函数(原型:void *malloc(size_t size))
1、malloc的参数就是需要分配的内存的字节数。
2、malloc所分配的是一块连续的内存。
3、分配成功,则返回指向分配内存起始地址的指针。分配失败,返回NULL指针。
4、对每个malloc返回的指针都进行检查,是好的习惯。
释放内存一般使用free函数(原型:void free(void *pointer))完成。
1、动态内存分配有助于消除程序内部存在的限制。
2、使用sizeof计算数据类型的长度,调高程序的可移植性。
calloc和realloc函数
void *calloc(size_t nmemb, size_t size);
void *realloc(void *ptr, size_t size);
calloc与malloc的区别
一是前者返回指向内存的指针之前把它初始化为0.
二是calloc的参数包括所需元素的数量和每个元素的字节数。根据这些值,能够计算出总共需要分配的内存。
realloc函数用于修改一个原先已经分配的内存卡的大小。使用该函数,可以使一块内存扩大或缩小。如果原先的内存卡无法改变大小,realloc将分配另一块正确大小的内存,并把原先那块内存的内容复制到新的块上。
三、malloc与new的不同点
从函数声明上可以看出。malloc 和 new 至少有两个不同:
new 返回指定类型的指针,并且可以自动计算所需要大小。
比如:
int *p;
p = new int; //返回类型为int* 类型(整数型指针),分配大小为 sizeof(int);
或:
int* parr;
parr = new int [100]; //返回类型为 int* 类型(整数型指针),分配大小为 sizeof(int) * 100;
而 malloc 则必须由我们计算要字节数,并且在返回后强行转换为实际类型的指针。
int* p;
p = (int *) malloc (sizeof(int));
第一、malloc 函数返回的是 void * 类型,如果你写成:p = malloc (sizeof(int)); 则程序无法通过编译,
报错:“不能将 void* 赋值给 int * 类型变量”。所以必须通过 (int *) 来将强制转换。
第二、函数的实参为 sizeof(int) ,用于指明一个整型数据需要的大小。如果你写成:
int* p = (int *) malloc (1);
代码也能通过编译,但事实上只分配了1个字节大小的内存空间,当你往里头存入一个整数,
就会有3个字节无家可归,而直接“住进邻居家”!造成的结果是后面的内存中原有数据内容全部被清空。
malloc 也可以达到 new [] 的效果,申请出一段连续的内存,方法无非是指定你所需要内存大小。
比如想分配100个int类型的空间:
int* p = (int *) malloc ( sizeof(int) * 100 ); //分配可以放得下100个整数的内存空间。
另外有一点不能直接看出的区别是,malloc 只管分配内存,并不能对所得的内存进行初始化,所以得到的一片新内存中,其值将是随机的。
除了分配及最后释放的方法不一样以外,通过malloc或new得到指针,在其它操作上保持一致。
malloc()函数其实就在内存中找一片指定大小的空间,然后将这个空间的首地址范围给一个指针变量,
这里的指针变量可以是一个单独的指针,也可以是一个数组的首地址,这要看malloc()函数中参数size的具体内容。
指针
- int f; /*声明一个整型变量*/
- int *f; /*一个指向整型的指针*/
- int f();/*把f声明为一个函数,它的返回值是一个整数*/
- int *f(); /*f是一个函数,它的返回值类型是一个指向整型的指针*/
- int (*f)(); /*使f成为一个函数指针,它所指向的函数返回一个整型值*/
- int *(*f)(); /*f是一个函数指针,只是所指向的函数的返回值是一个整型指针*/
- int f[]; /*f是个整型数组*/
- int *f[]; /*f是数组,它的元素类型是指向整型的指针*/
- int (*f[])(); /*括号内的表达式*f[]首先进行求值,所以f是一个元素为某种类型的指针的数组。表达式
- 末尾的()是函数调用操作符,所以f肯定是一个数组,数组元素的类型是函数指针,
- 它所指向的函数的返回值是一个整型值*/
- int *(*f[])(); /*f是一个指针数组,指针所指向的类型是返回值为整型指针的函数*/
命令行参数
第1个通常称为argc,它表示命令行参数的数目。第2个通常称为argv,它指向一组参数值。
指针数组:这个数组的每个元素都是一个字符指针,数组的末尾是一个NULL指针。
argc的值和这个NULL值都用于确定实际传递了多少个参数。argv指向数组的第1个元素,
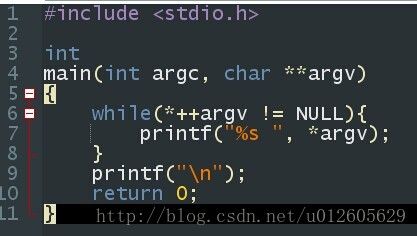
输出printf:
int printf(const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
int sprintf(char *str, const char *format, ...);
int snprintf(char *str, size_t size, const char *format, ...);
printf是标准的输出函数。
int printf ( const char * fmt , . . . ){
char printf_buf [ 1024 ] ;
va_list args ;
int printed ;
va_start(args, fmt);
printed = vsprintf(printf_buf, fmt, args);
va_end(args);
puts(printf_buf);
return printed;
}
fprintf传送格式化输出到一个文件中。根据指定的format(格式)发送信息(参数)到由stream(流)指定的文件,
fprintf只能和printf一样工作。若成功则返回值是输出的字符数,发生错误时返回一个负值。
第一个参数是文件指针stream,后面的参数就是printf中的参数,其功能就是把这些输出送到文件指针指定的文件中,如果想要像printf一样将输出送到标准输出,只需要将文件指针FILE指定为stdout即可。
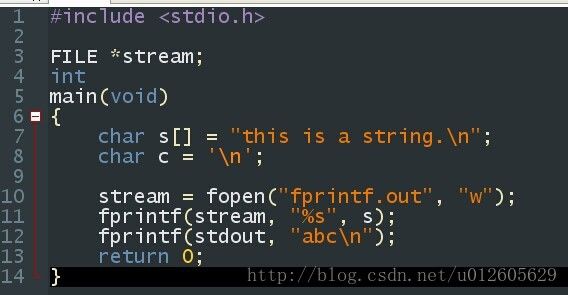
该程序的运行结果是在fprintf.out文件中存入了this is a string.字符串,
在标准输出输出了abc字符串。
sprintf,字符串格式化命令,主要功能是把格式化的数据写入某个字符串中。
第一个参数str是char型指针,指向将要写入的字符串的缓冲区。后面第二个参数是格式化字符串。
- char s[100];
- sprintf(s, "%%sfjdksfj" );
- printf("%s\n", s);
snprintf函数与sprintf函数类似。它也是将可变个参数按照format格式化成字符串,然后将其复制到str中。
(1) 如果格式化后的字符串长度 < size,则将此字符串全部复制到str中,并给其后添加一个字符串结束符('\0');(2) 如果格式化后的字符串长度 >= size,则只将其中的(size-1)个字符复制到str中,并给其后添加一个字符串结束符('\0'),返回值为格式化后的字符串的长度。
- snprintf(s, 4, "%%sfjdksfj" );
- printf("%s\n", s);
- snprintf(s, sizeof(s), "%%sfjdksfj" );
- printf("%s\n", s);
%sf
%sfjdksfj
const
1、const可以理解成是”只读变量“的限定词;
const修饰的是变量,跟常量是不同的,常量是被编译器放在内存中的只读区域,
const int nochange;nochange = 12;/*这是不允许的*/
const int nochange = 12;/*这是可以的*/
2、在声明指针时使用关键字const,一定要区分
让指针本身成为const 与 让指针指向的值成为const区分开来。
const float *pf;/*pf 指向一个常量浮点数值,pf指向的值必须是不变的,但pf本身的值可以改变*/
float *const pt;/*pt是一个常量指针,它必须总是指向同一个地址,但所指向的值可以改变*/
const float *const ptr;/*ptr必须总是指向同一个位置,并且它所指位置存储的值也不能改变*/
float const *pfc;等同于const float *pfc;
把const放在类型名的后边和*的前边,意味着指针不能用来改变它所指向的值。
总之,一个位于*左边任意位置的const使得数据成为常量,而一个位于*右边的const使得指针自身成为常量。
常见用法是声明作为函数形式参量的指针。
3、对全局数据使用const。
首先遵循外部变量的惯用规则:在一个文件中进行定义声明,在其他文件中进行引用声明(使用extern关键字)。
定义一些全局变量
const doubule PI = 3.141;
使用在其他文件中定义的全局变量
extern const double PI;
gets函数从系统标准输入获得一个字符串,读取字符串直到遇到一个换行符(\n),它读取换行符之前的所有字符,在这些字符后添加一个空字符(\0),然后把这个字符串交给调用它的程序。它把读取的换行符直接丢弃,而不是把它放入字符串
char *gets(char *s);
gets函数的一个不足是它不检查预留存储区是否能够容纳实际输入的数据。多出来的字符简单地溢出到相邻的内存区。
fgets()函数改进了这个问题。它可以指定最大读入字符数。
fgets()和gets()有3点不同:
a、它需要第二个参数来说明组大读入字符数。如果这个参数值为n,fgets()就会读取最多n-1个字符或者读完一个换行符为止。
b、如果fgets读取到换行符,就会把它存放在字符串里,而不是像gets()那样丢弃它。也就是说它在字符串的最后存放的是换行符(\n),而不是空字符(\0)。
c、它还需要第三个参数来说明读哪一个文件。
#include
char *fgets(char *s, int size, FILE *strem);
C有三个用于输出字符串的标准库函数puts()、fputs()和printf()。
1、puts()函数只需要给出字符串参数的地址。
#include
int puts(const char *s);
puts()显示字符串时自动在其后添加一个换行符。
2、fputs()函数时puts()的面向文件版本。
与puts()不同,fputs()并不为输出自动添加换行符。
#include
int fputs(const char *s, FILE *stream);
注意:gets()丢掉输入里的换行符,但puts()为输出添加换行符。
技巧:假定写一个循环,读取一行并把它回显在下一行,可以这么写:
char line[80];
while(gets(line))
puts(line);
pintf("%s \n", string);等同于 puts(string);
int fputc(int c, FILE *stream);
int fputs(const char *s, FILE *stream);
int putc(int c, FILE *stream);
int putchar(int c);
int puts(const char *s);
fputc()写一个字符c,强制转换成一个unsigned char类型字符,到文件stream。
fputs()写一个字符串到stream,省略字符串尾部的‘\0’。
putc()与fputc()相同,只是putc()是作为一个宏实现的。
putchar(c)等同于putc(c,stdout)。
puts()写一个字符串到标准输出stdout,并自动在字符串的尾部添加一个换行符"\n"。
返回值:
字符:fputc()、putc()和putchar()成功时返回要写的字符,失败返回EOF。
字符串:puts()和fputs()成功时返回一个非负数,失败返回EOF。
intfgetc(FILE *stream);
char *fgets(char *s, int size, FILE *stream);
int getc(FILE *stream);
int getchar(void);
char *gets(char *s);
fgetc()读取文件指针stream所指向文件的下一个字符,返回值是所读取字符强制类型转换成整数的值,如果到达文件尾部或者出错,则返回EOF。
getc()与fgetc()函数相同,只是它是一个宏实现。
getchar()等同于getc(stdin)。
gets()从标准输入读取一行到字符串指针s所指向的缓冲区,直到行结束或遇到一个EOF,然后用'\0'替代它。
fgets()从文件指针stream所指向的文件中,最多取出size个字符存放到s所指向的换中去中。遇到EOF或一行结束时,读取停止。如果读取一行,它将该行存放到缓冲区,在最后一个字符的后边添加'\0'并放到缓冲区。
返回值:
fgetc(), getc() 和getchar()成功时返回读取字符的ASCII码值,失败时返回EOF。
gets() 和fgets() 成功时返回字符串的指针s,失败时返回NULL指针。
scanf:
scanf函数也是有返回的,它的返回值是成功读取变量的个数。如果有一个输入与变量格式不匹配,那么返回值为0。
- scanf("%d %d", &num1, &num2);
如果输入一个浮点数一个整数,则返回值是1。
如果输入一个字符一个整数,则返回值是0。
内联函数是通过编译器来实现的,而宏则是在预编译的时候替换。
创建内联函数方法:在函数声明中使用函数说明符inline。
内联函数的特点:
1、类似于宏,编译器在看到内联函数声明时,就会在使用内联函数时用函数体代替函数调用,其效果就如同在此处键入了函数体的代码。
2、内联函数应该是比较短小。对于很长的函数,调用函数的时间少于执行函数主体的时间;此时,使用内联函数不会节省多少时间。
一段C程序,编译连接后形成的可执行文件一般有代码段、数据段、堆和栈等几部分组成。其中数据段又包括只读数据段、已初始化的读写数据段和未初始化的BSS段。
文本段:存放程序执行的代码。
数据段:
1>只读数据段:
只读数据段是程序使用的一些不会被更改的数据,使用这些数据的方式类似查表式的操作,由于这些变量不需要更改,因此只需要放置在只读存储器中即可。
一般是const修饰的变量以及程序中使用的文字常量一般会存放在只读数据段中。
2>已初始化的读写数据段:
已初始化数据是在程序中声明,并且具有初值的变量,这些变量需要占用存储器的空间,在程序执行时它们需要位于可读写的内存区域内,并且有初值,以供程序运行时读写。
在程序中一般为已经初始化的全局变量,已经初始化的静态局部变量(static修饰的已经初始化的变量)
3>未初始化段(BSS):
未初始化数据是在程序中声明,但是没有初始化的变量,这些变量在程序运行之前不需要占用存储器的空间。与读写数据段类似,它也属于静态数据区。但是该段中数据没有经过初始化。未初始化数据段只有在运行的初始化阶段才会产生,因此它的大小不会影响目标文件的大小。在程序中一般是没有初始化的全局变量和没有初始化的静态局部变量。
栈:由系统自动分配。例如,声明在函数中一个局部变量int b;系统自动在栈中为b开辟空间。
二
根据上面的理论知识,分析示例片段的内存分配:

三
栈与堆的区别:
1.申请方式
(1)栈(satck):由系统自动分配。例如,声明在函数中一个局部变量int b;系统自动在栈中为b开辟空间。
(2)堆(heap):需程序员自己申请(调用malloc,realloc,calloc),并指明大小,并由程序员进行释放。
char p; p = (char *)malloc(sizeof(char));
但是,p本身是在栈中。
2.申请大小的限制
(1)栈:栈是向底地址扩展的数据结构,是一块连续的内存区域(它的生长方向与内存的生长方向相反)。栈的大小是固定的。如果申请的空间超过栈的剩余空间时,将提示overflow。
(2)堆:堆是高地址扩展的数据结构(它的生长方向与内存的生长方向相同),是不连续的内存区域。这是由于系统使用链表来存储空闲内存地址的,自然是不连续的,而链表的遍历方向是由底地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。
申请效率
(1)栈由系统自动分配,速度快。但程序员是无法控制的
(2)堆是由malloc分配的内存,一般速度比较慢,而且容易产生碎片,不过用起来最方便。
.存取效率
(1)堆:char *s1=”hellow tigerjibo”;是在编译是就确定的
(2)栈:char s1[]=”hellow tigerjibo”;是在运行时赋值的;用数组比用指针速度更快一些,指针在底层汇编中需要用edx寄存器中转一下,而数组在栈上读取。
7.分配方式:
(1)堆都是动态分配的,没有静态分配的堆。
(2)栈有两种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的。它的动态分配是由编译器进行释放,无需手工实现。
Windows下远程登录到Linux -- 以Win7,Ubuntu12.04LTS,SSH 为例
引言:
Linux大多应用于服务器,而服务器不可能像PC一样躺在办公室里,它们是放在IDC机房的,所以我们平时登录Linux系统都是通过远程登录的。Linux系统中是通过ssh服务实现的远程登录功能。默认ssh服务开启了22端口,而且当我们安装完系统时,这个服务已经安装,并且是开机启动的。所以不需要我们额外配置什么就能直接远程登录linux系统。
Ssh服务的配置文件为/etc/ssh/sshd_config,你可以修改这个配置文件来实现你想要的ssh服务。比如你可以更改启动端口为36000.
为什么不用Telnet?telnet因为采用明文传送报文,安全性不好,很多Linux服务器都不开放telnet服务,而改用更安全的ssh方式了。
http://blog.csdn.net/zjf280441589/article/details/17408991
1、ssh的安装
2、生成密钥
3、修改配置文件
将Linux作为:
1.开发平台
2.服务器
在Windows平台学习的话,一但涉及到底层的东西,你就会发现很难深入
附:美女的比喻:
Linux就好像是一个极富内涵的美女,不光外表漂亮,而且富有感染力,她会毫不隐藏自己的优点,缺点,然你去自己的品味,欣赏她,以至于深入的了解她,她甚至会为了你而去改变她自己!!
而Windows则更像一位贵妇,虽然外表很漂亮,很有吸引力,但是,万一你要是紧盯着她,她就会说:看什么呢,丑流氓,再看我报警了!!!
作为程序员,有两种方式快速的提高
1)不断的写代码
2)不断的看别人的代码
解决问题的智慧:
注意系统的英文提示信息,以及系统的文档,示例;
提问前,首先自己分析,学习。
互联网,教材,论坛的检索;#Google.combaidu.com提问的智慧!
整理好自己得学习笔记!
学习大纲:
1、文件处理命令
2、权限管理命令
3、文件搜索命令
4、帮助命令
5、压缩解压缩命令
6、网络通信命令
7、系统开关机命令
8、Shell应用技巧
只有root才能执行的命令
/sbin 或/usr/sbin
所用用户都可执行的命令
/bin或 /usr/bin
选项: -a all
-l long 详细信息
-d directory 查看目录属性
r:read读权限
w:write写权限
x:execute执行权限
用户也分为三种:
1、所有者U:user
2、所属组G:group
3、其他人O:others
Linux很多的大小是用数据块来表示:block,其单位512字节,但其 大小可根据实际应用进行调节。
数据块可以理解为:存储数据的最小单位。
2、cd [change directory]
cd [目录]
e.g.
ch / 切换到根目录
cd.. 切换到上级目录
3、pwd [printworking directory] /bin/pwd
4、touch:创建文件 /bin/touch
touch[文件名]
5、mkdir [makedirectories] :创建目录
mkdir [目录名]
mkdir /test
//mkdir test :在当前目录下创建目录
6、cp[copy]:复制文件或目录 /bin/cp
cp-R [复制目录]
//如果复制的是文件的话,就不用加-R,并且文件数不做限制
附: etc目录下保存的大多是配置文件。
Ctrl+c:终止程序运行
7、mv[move]:移动文件,更名 /bin/mv 类似与剪切、重命名
mv[源文件或目录][目的目录]
e.g.
mv servers ser 改名
mv /test/ser /tmp 移动
mv /test/testfile /tmp/file.test 移动并改名
8、rm[remove]:删除文件 /bin/rm
rm -r [文件或目录]
rm只能用来删除文件,要想删除目录,则要加上-r即可,有时候会很烦人。。。
但是如果你十分确定这个文件目录确实应该删除,则加上-rf即可
如果不想弹出确认信息,则加上 -f选项【force】,并不推荐,不同与UNIX
8.1rmdir 用来删除空目录,不常用
9、cat[concatenateand diplay files] /bin/cat
比较适用于文件内容不是很长的文件
cat[文件名]
10、more /bin/more
分页显示文件内容
命令:
f或Space 翻页
Q或q 退出
Enter 下一行
e.g. more /etc/servies
11、head /bin/head
查看文件的前几行
head -num [文件名]// 不加数字默认看10行
e.g. head -20 /etc/servirs
12、tail/bin/tail
查看文件的后几行
tail -num [文件名]
-f 动态显示文件内容
13、ln[link]: /bin/ln
产生链接文件。
语法: 产生硬链接 不需要加任何选项,直接生成
ln[源文件][目标文件]
产生软链接 需要加-s[soft]
ls-s [源文件][目标文件]
附: 为什么他可以同步更新
ls -i i[inode] i节点实际上就是一个数字标识,因为Linux 不认识字符!在Linux里面处理任何东西,都要有一个数字标识。所以,所有文件必须要有i节点!
Python进阶:
一.数据类型
4.列表List
1.列表长度是动态的,可任意添加删除元素
2.用索引可以很方便的访问元素,甚至返回子列表
3.list:列表(即动态数组,C++标准库的vector,但可含不同类型的元素于一个list中)
a = ["I","you","he","she"] #元素可为任何类型。
4.下标:按下标读写,就当作数组处理
以0开始,有负下标的使用
0第一个元素,-1最后一个元素,
-len第一个元 素,len-1最后一个元素
取list的元素数量
len(list) #list的长度。实际该方法是调用了此对象的__len__(self)方法。
L = range(1,5) # 即 L=[1,2,3,4], 不含最后一个元素
L = range(1, 10, 2) # 即 L=[1, 3, 5, 7, 9]
6.list的方法
L.append(var) #追加元素
L.insert(index,var)
L.pop(var) #返回最后一个元素,并从list中删除之
L.remove(var) #删除第一次出现的该元素
L.count(var) #该元素在列表中出现的个数
L.index(var) #该元素的位置,无则抛异常
L.extend(list) #追加list,即合并list到L上
L.sort() #排序
L.reverse() #倒序
list 操作符:,+,*,关键字del
a[1:] #片段操作符,用于子list的提取
[1,2]+[3,4] #为[1,2,3,4]。同extend()
[2]*4 #为[2,2,2,2]
del L[1] #删除指定下标的元素
del L[1:3] #删除指定下标范围的元素
list的复制
L1 = L #L1为L的别名,用C来说就是指针地址相同,对L1操作即对L操作。函数参数就是这样传递的
L1 = L[:] #L1为L的克隆,即另一个拷贝。
5.字典
其实与C++中的Map相对应,每一个元素是pair,包含key、value两部分。key是Integer或string类型,value 是任意类型。
键是唯一的,字典只认最后一个赋的键值。
dictionary的方法
D.get(key, 0) #同dict[key],多了个没有则返回缺省值,0。[]没有则抛异常
D.has_key(key) #有该键返回TRUE,否则FALSE
D.keys() #返回字典键的列表
D.values()
D.items()
D.update(dict2) #增加合并字典
D.popitem() #得到一个pair,并从字典中删除它。已空则抛异常
D.clear() #清空字典,同del dict
D.copy() #拷贝字典
D.cmp(dict1,dict2) #比较字典,(优先级为元素个数、键大小、键值大小)#第一个大返回1,小返回-1,一样返回0
dictionary的复制
dict1 = dict #别名
dict2=dict.copy() #克隆,即另一个拷贝。
6.元组
在python中,元组有以下特性
1.任意对象的有序集合,这条没啥说的,数组的同性;
2.通过偏移读取;
3.一旦生成,不可改变;
4.固定长度,支持嵌套