I3D视频分类论文梗概及代码解读Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
论文https://arxiv.org/pdf/1705.07750.pdf,from DeepMind ,CVPR2017
代码https://github.com/LossNAN/I3D-Tensorflow
2017年视频分类最好的网络,同时提供了VGG的预训练模型,网络端到端,简单易懂,便于部署及工程化。只是跑一下基本有个Tensorflow,单显卡就能训练和测试,效果还好,一绝。本文是论文梗概和代码网络结构的少量解读。
Two-Stream Inflated 3D ConvNets
I3D网络摘要
做了一个超大的视频分类的数据集,Kinetics人类动作数据集,400类,每类超过400个YouTube视频段
新的基于2D 卷积网络的I3D模型,将filters,pooling kernels扩展到3D,从视频中学习到无缝的时空特征提取器,同时成功利用ImageNet架构设计超参数。
一、介绍
预训练方法和更深的网络总是有提升,无论是分类、姿态估计、动作分类等不同任务。
I3D,基于InceptionV1网络结构,基于Kinetics预训练,效果特别好。
二,视频分类模型
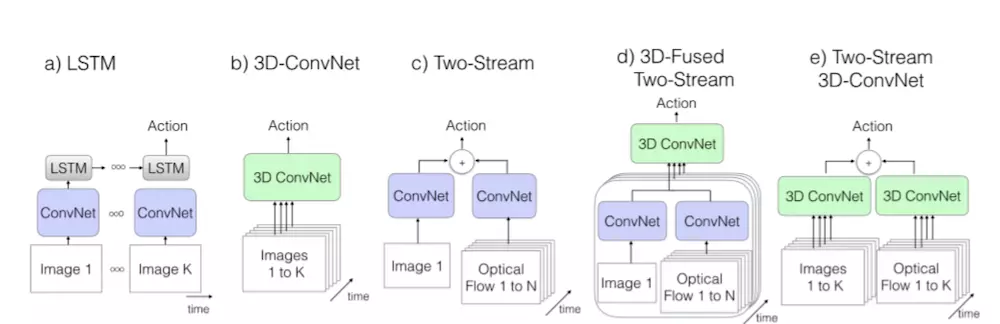
现有视频分类关注与:卷积核2D还是3D,输入时RGB还是光流,2D图片中帧间信息如LSTMs模型,我们介绍CNN+LSTM;two-stream;3D卷积网络C3D,并推出Two-Stream Inflated 3D ConvNets即I3D。
2.1 老方法一,Conv+LSTM
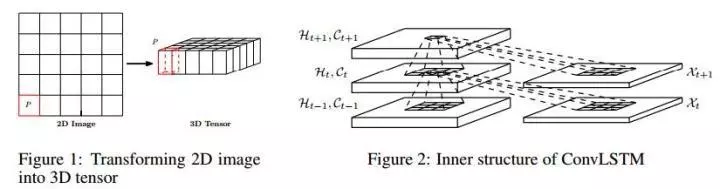
单张图片提取特征再pool在一起预测视频,但可能破坏视频局部结构,比如开门、关门的区别
因而加入LSTM时序模型,可以捕捉时序空间特征和长时间的相关性。InceptionV10最后一层pool,有512个隐含节点之后接LSTM,+全连接层接入损失函数
模型使用交叉熵损失函数,输入25帧采样为5帧
2.2老方法二,3D卷积
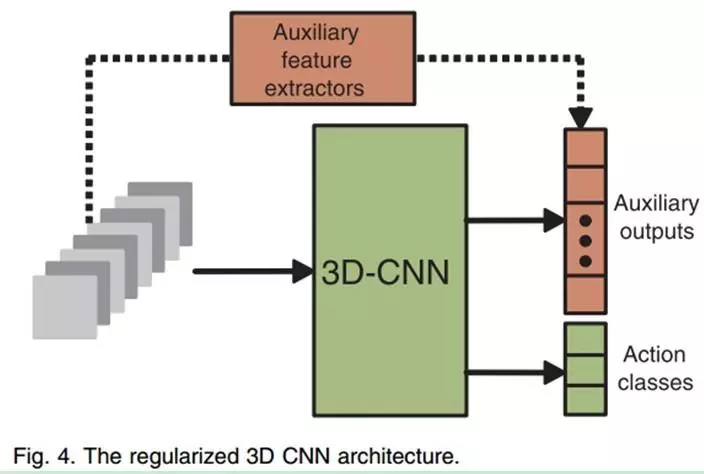
C3D看上去很自然的想法,但存在维度问题,参数更多难以训练;无法使用ImageNet预训练参数。可用,但和SOTA还有差距,可在我们大规模数据集上作为候选方法
C3D进行改进,8卷积层,5池化层,2全连接层,输入用16帧112*112 大小视频,在每个卷积层和全连接层后都加BN层。第一个pooling层我们用stride=2,这可以减少内存,使用更大的batch,这对BN层很重要,尤其是在全连接层之后
2.3老方法Two-Stream
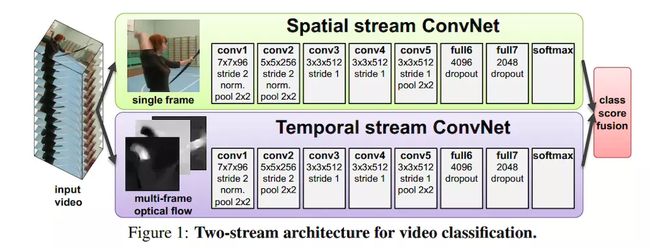
LSTM可以从Conv层达到很好效果,但不能捕捉低级的动作,低级像素的这在很多case中是关键。且训练费事,因为要从多帧反向传播。
一种实际的想法是,单张RGB图像+10帧光流场,通过两条预训练conv模型,追踪X Y两个方向光流,只产生两倍参数的输入,
测试中将结果平均,这很有效。
最近研究中,使用卷积层后空间、光流的融合可以提高精度,减少计算光流通道的计算时间。在InceptionV1后,使用5帧计算10帧光流场,在最后一层平均pool之前是5*7*7,5帧*7*7维度,经过3*3*3卷积,输出512channel,紧跟3*3*3的max-pooling,再通过全连接层。新层的初始化时高斯噪声。
two-stream和3D都可以端到端的训练。
2.4 新模型 I3D
3D卷积从2D卷积的Imagenet的网络设计和参数中获益。
拓展2D卷积网到3D 我们提出将2D转化为3D,而不仅仅是重复的对时空进行加工。这可以通过将所有滤波器和pooling核进行时间上的膨胀得到。滤波器通常是N*N变为N*N*N
将2D滤波器变为3D 除了结构,还想提取预训练参数。我们观察到视频可以通过复制图片序列得到,且视频上的pooling激活值应该与单张图片相同。由于是线性的,可以将2D滤波器沿着时间维度重复N次。这保证了相应的相同。由于图片组成的视频卷积层在时间上输出是恒定的,因此点状非线性层和average层和max pooling层和2D的一致。
空间、时间和网络深度接收增长 图片中空间域自然的将x,y同等对待,在时间域上却没必要这样,(时间域上的pooling核选取有不同),这取决于帧率和图片维度质检的关系,如果相比空间域,时间域增长太快,可能破坏早期的特征检测,如果时间上增长的过慢,可能难以捕捉场景动态信息。
在InceptionV1中,第一个conv层stride是2,然后是4个max-pooling,stride=2,最后的7*7average-pooling层。输入25帧每秒,发现,在前两个max-pooling层中不加入空间pooling比较好,(我们使用了1*3*3de kernel,stride=1)同时使用了对称的kernels和stride在所有其他的max-pooling层,最后一个average-pooling层使用2*7*7的kernel,整体结构如下图,使用64帧并进行条采样,测试时使用整个视频,对每段结果进行平均。
两个3D流 纯3D网络应该能从RGB中直接学习特征,但是它只执行纯粹的前向传播,而光流算法在某种程度上是经常性优化的,(???完全搞不懂这句话)也许因为缺乏这种循环结构,双流配置仍然很有价值,一个只接受RGB,另一个只接受优化后的平滑光流信息的网络,分别训练,测试结果取平均。
2.5实施细节
除了类似C3D卷积网络外,都是用ImageNet的InceptionV1预训练网络,每个卷积网络后都放置批量归一化BN层和ReLUctant层,来产生分类的分数。
使用SGD方法,momentum为0.9,并行32个GPU,其中3D卷积网使用64个GPU,因为要从一个很大的batch中接受大量的输入帧。Kinetics训练110K次,loss饱和时降低10倍学习率。验证集上超参数需要调整,UCF101和HMDB51使用Kinetics的学习率训5K步,使用16GPU,Tensorflow
数据增强对深度结构性能至关重要,训练时使用随机剪切,视频小边缩放至256,剪切为224,。时间域上选择开始帧来保证足够的帧数。对于短视频,循环多次来保证足够输入。训练时采用随机左右翻转,测试时我们获取整个视频的224*224的中心裁剪区域,对预测的结果进行平均。简单的尝试了256*256空间卷积,但是效果没有提升。之后我们会在测试阶段左右反转,训练时更改光度来提高。
我们使用TV-L1算法计算光流
三 人类动作视频数据集Kinetics
包括单人动作(画画,喝东西,笑),人与人之间的动作(拥抱亲吻握手),人与物之间(打开礼物,修剪草坪,洗盘子),一些行为有细粒度,如不同类型的有用。有些需要区分对象,如演奏不同类型的管乐器。400类人类行为类,每类400个更多的剪辑,共240K个训练集,剪辑时间约10s,测试集每类100个剪辑
4实验与结论
对比了5个模型在不同数据集上的结果。
表2,得出结论:
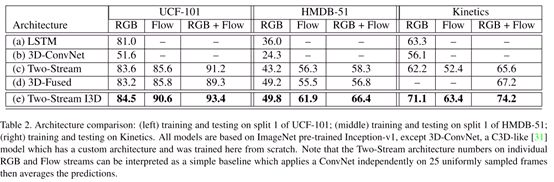
1,I3D在所有数据集表现都好,巨大参数的模型在相对小数据集UCF,HMDB上由于利用了ImageNet预训练参数,扩展到3D卷积是有好处的。
2,HMDB训练集太难,3所有模型排序差不多
4双流I3D最好,但RGB与光流两个单独版本不同模型谁好都不一定。Kinetics有相机运动,光流难以得到好效果。I3D可以更好地的利用光流信息,虽然看上去光流提供信息远少于RGB,但是实际上不是这样。预训练模型都比从头训练好。
5实验
为了评估Kinetics数据集得到的泛化能力,我们以如下方式
1,固定网络权重,由网络产生UCF数据集上的特征,使用数据集完成后续soft-max分类任务
2,fine-tune每个网络,然后再UCF上训练,
还评估了只用Kinetics预训练以及ImageNet+Kinetics的区别,如表4,I3D,C3D从预训练中获益更大,预训练+训练最后一层也比从头训练好。

强大的迁移能力得益于:训练时64帧,测试时使用所有帧,可以捕捉细粒度的时域特征。换句话说,输入帧数少的模型从预训练中获益少,者因为视频和ImageNet中图像没什么区别。I3D比C3D好,因为更深,同时参数更少,ImageNet预训练,4倍长视频,2倍分辨率
Two-Stream输入的I3D即便从头训效果也很好这是由于光流输入效果好。同时看到,Kinetics预训练比IMageNet效果好
5.1与SOTA对比
如图表5是UCF和HMDB效果对比。只基于Kinetics预训练的效果如图4
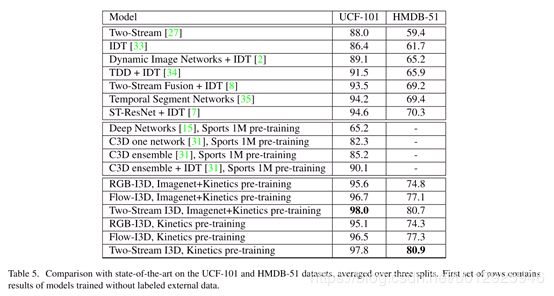
最好的结果是ResNet50 RGB+光流模型
6 讨论
视频邻域的预训练是够有效?显然Kinetics预训练效果显著。
代码少量的展示和解析
网络结构 i3d.py 输入input维度(8,32,224,224,3)8个batch,32帧一组
# Endpoints of the model in order. During construction, all the endpoints up
# to a designated `final_endpoint` are returned in a dictionary as the
# second return value.
#每层都返回final_endpoint,是一个字典结构,名字分别如下。
VALID_ENDPOINTS = (
'Conv3d_1a_7x7',
'MaxPool3d_2a_3x3',
'Conv3d_2b_1x1',
'Conv3d_2c_3x3',
'MaxPool3d_3a_3x3',
'Mixed_3b',
'Mixed_3c',
'MaxPool3d_4a_3x3',
'Mixed_4b',
'Mixed_4c',
'Mixed_4d',
'Mixed_4e',
'Mixed_4f',
'MaxPool3d_5a_2x2',
'Mixed_5b',
'Mixed_5c',
'Logits',
'Predictions',
)第一层:输出(8,16,112,112,64) 8batch,由于stride=2,2,2 因而图片维度都降低一倍,16*112*112 , 由于channel=64,输出最后一维就是64
设定好输入一次是64帧或者32帧,就是Batch* 32*224*224*3,K=7*7*7 , Stride=2*2*2 ,
net = inputs
end_points = {}
end_point = 'Conv3d_1a_7x7'
net = Unit3D(output_channels=64, kernel_shape=[7, 7, 7],
stride=[2, 2, 2], name=end_point)(net, is_training=is_training)
end_points[end_point] = net
if self._final_endpoint == end_point: return net, end_points第二层,3D版的max-pooling,输出(8,16,56,56,64), 由于padding是SAME,所以不用考虑kernel导致的维度变化
end_point = 'MaxPool3d_2a_3x3'
net = tf.nn.max_pool3d(net, ksize=[1, 1, 3, 3, 1], strides=[1, 1, 2, 2, 1],
padding=snt.SAME, name=end_point)
end_points[end_point] = net
if self._final_endpoint == end_point: return net, end_points第三层,卷积,输出(8,16,56,56,64)1*1卷积耶,线性变化,组合batch中的样本,由于channel=64,最后一维输出64维
end_point = 'Conv3d_2b_1x1'
net = Unit3D(output_channels=64, kernel_shape=[1, 1, 1],
name=end_point)(net, is_training=is_training)
end_points[end_point] = net
if self._final_endpoint == end_point: return net, end_points第四层,同上,输出维度(8,16,56,56,192)
end_point = 'Conv3d_2c_3x3'
net = Unit3D(output_channels=192, kernel_shape=[3, 3, 3],
name=end_point)(net, is_training=is_training)
end_points[end_point] = net
if self._final_endpoint == end_point: return net, end_points第五层,3Dmax_pooling,输出维度(8,16,28,28,192)
end_point = 'MaxPool3d_3a_3x3'
net = tf.nn.max_pool3d(net, ksize=[1, 1, 3, 3, 1], strides=[1, 1, 2, 2, 1],
padding=snt.SAME, name=end_point)
end_points[end_point] = net
if self._final_endpoint == end_point: return net, end_points第六层,Inception,最终输出,0,1,2,3几个层分别输出维度
(8,16,25,25,64);(8,16,28,28,128);(8,16,28,28,32);(8,16,28,28,32)
concat之后总的输出为(8,16,28,28,256)
end_point = 'Mixed_3b'
with tf.variable_scope(end_point):
with tf.variable_scope('Branch_0'):
branch_0 = Unit3D(output_channels=64, kernel_shape=[1, 1, 1],
name='Conv3d_0a_1x1')(net, is_training=is_training)
with tf.variable_scope('Branch_1'):
branch_1 = Unit3D(output_channels=96, kernel_shape=[1, 1, 1],
name='Conv3d_0a_1x1')(net, is_training=is_training)
branch_1 = Unit3D(output_channels=128, kernel_shape=[3, 3, 3],
name='Conv3d_0b_3x3')(branch_1,
is_training=is_training)
with tf.variable_scope('Branch_2'):
branch_2 = Unit3D(output_channels=16, kernel_shape=[1, 1, 1],
name='Conv3d_0a_1x1')(net, is_training=is_training)
branch_2 = Unit3D(output_channels=32, kernel_shape=[3, 3, 3],
name='Conv3d_0b_3x3')(branch_2,
is_training=is_training)
with tf.variable_scope('Branch_3'):
branch_3 = tf.nn.max_pool3d(net, ksize=[1, 3, 3, 3, 1],
strides=[1, 1, 1, 1, 1], padding=snt.SAME,
name='MaxPool3d_0a_3x3')
branch_3 = Unit3D(output_channels=32, kernel_shape=[1, 1, 1],
name='Conv3d_0b_1x1')(branch_3,
is_training=is_training)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 4)
end_points[end_point] = net
if self._final_endpoint == end_point: return net, end_points...中间很多类似的层...
Mixed_5c 输出维度(8,4,7,7,1024),然后是Logits层,其中net.shape为8,3,1,1,1024
因为pad是VALID,net变成8,3,1,1,1024
logits的维度也是8,3,1,1,1024
averaged_logits维度是8,N , N是分类的类别数 我程序里N=7 几个具体的维度在下面代码注释中有写
end_point = 'Logits'
with tf.variable_scope(end_point):
net = tf.nn.avg_pool3d(net, ksize=[1, 2, 7, 7, 1],
strides=[1, 1, 1, 1, 1], padding=snt.VALID)
net = tf.nn.dropout(net, dropout_keep_prob)
print(net.shape)
logits = Unit3D(output_channels=self._num_classes,
kernel_shape=[1, 1, 1],
activation_fn=None,
use_batch_norm=False,
use_bias=True,
name='Conv3d_0c_1x1')(net, is_training=is_training)
# logits shape: (8,3,1,1,7) 7 is N of your classicfy numbers
if self._spatial_squeeze:
logits = tf.squeeze(logits, [2, 3], name='SpatialSqueeze')
# shape of logits is 8,3,7
averaged_logits = tf.reduce_mean(logits, axis=1)
#shape of averaged_logits : 8,7
end_points[end_point] = averaged_logits
if self._final_endpoint == end_point: return averaged_logits, end_pointsAdamOptimizer优化器,L2 Loss
tf.contrib.layers.apply_regularization(regularizer=l2_reg, weights_list=weighyt_list)
All:端到端的网络就是好,简单易懂,比其他的几个stage的程序。。。好懂太多,容易部署。
不过我使用过程中,发现视频分类,自己的数据集需要很大量才不会过拟合,而且,作者的代码中几乎没有数据增强,仅有随机剪切。我们可以自己加数据增强,翻转、噪声等。我已经再用了,有空的话我会放到github上分享的。
后记
看完这些,希望你已经没有想看源码的冲动了。
如果是这样的话,不妨点个赞吧。
为何要点赞?
如果本文解决了你的困惑,不妨点个赞鼓励一下。
不管你信不信,也不管你同不同意,实际上,你的每一次点赞都标志着你自身的进步。而打赏乃是点赞的高级形式
曾经有无数个点赞的机会,但是我都没有好好珍惜,假如时光可以倒流,我一定为他们也为自己点赞。