深度学习入门:Tensorflow实战Digit Recognizer
Tensorflow是当前GitHub上最活跃的机器学习项目,本文是Tensorflow实战Digit Recognizer系列文章的第一篇,介绍如何在MNIST数据集上快速跑出一个模型。
我们在学习一门新的编程语言的时候,第一个项目都是“Hello word”。MNIST在图像识别领域的地位正如“Hello world”在程序员心中的地位,本文将手把手教会大家利用Tensorflow实现一个简单的Softmax回归模型,快速完成Kaggle的入门赛Digit Recognizer。
1.前言
1.1 Digit Recognizer竞赛
Digit Recognizer竞赛是Kaggle平台举办的新手入门级别的比赛,帮助我们快速入门计算机视觉(CV,Computer Vision)。
比赛用MNIST数据集,MNIST (“Modified National Institute of Standards and Technology”) 是计算机视觉领域非常著名的数据集,收集了大量的手写数字,参赛者选手需要通过机器学习算法来识别手写数字图片,包括0~9一共10个数字。

1.2 Tensorflow简介
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。Google在2015年将Tensorflow开源后,收到业界的追捧而成为当前最为流行的深度学习库。

Tensorflow的安装请参考另外一篇文章:深度学习环境搭建。
2.Competition
2.1 数据预处理
正则化
像素点用0~255的数字来表示,为了提高神经网络的优化SGD的准确性,对数据进行正则化处理。
train_df = train_df.applymap(lambda x: x/255.0).astype(np.float32)
test = test.applymap(lambda x: x/255.0).astype(np.float32)OneHot编码
训练数据集的标签是0~9的数字,为了方便Softmax分类,调用pandas库的get_dummies方法转化为Onehot编码方式。
label = pd.get_dummies(train['label'])验证集划分
将数据集划分为8:2的训练集和验证集。
x_train, x_valid, y_train, y_valid = train_test_split(train_df, label, test_size=0.2, random_state=2017)2.2 Tensorflow回归模型预测MNIST
2.2.1 Softmax回归模型
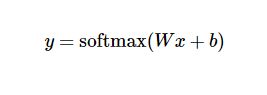
定义模型参数
Tensorflow中的Variable表示一个可以修改的张量,可以用于计算输入值,也可以在计算中被修改。对于Softmax回归模型中,我们需要定义的权重值w和偏置量b。我们想要784维的输入像素乘以w得到一个10维的值,所以w的维度是(784,10),b的维度是(10)。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))定义模型变量
Tensorflow中的placeholder表示一个占位符,我们可以在Tensorflow运行时输入这个值。我们定义输入的像素x和输入的正确标签y。
x = tf.placeholder("float", [None, 784])
y = tf.placeholder("float", [None,10])实现模型
Tensorflow已经实现的很多的运算,我们只需要简单的一行代码就可以实现我们的函数。
yhat = tf.nn.softmax(tf.matmul(x,W) + b)这行代码实现的了我们的Softmax函数。
2.2.2 训练模型
计算Cost Function
我们用交叉熵(cross-entropy),计算损失函数。
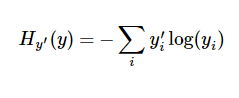
cross_entropy = -tf.reduce_sum(y*tf.log(yhat))首先计算预测的yhat,用tf.lag(yhat)求对数,再乘上正确的标签y。最后用tf.reduce_sum计算张量元素的和。
实现反向传播算法
Tensorflow训练算法非常容易,它对常规的函数已经内置了求导函数,因此可以自动帮我们实现反向传播算法。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)我们定义梯度下降算法来最小化cross_entropy,步长为0.01。
模型训练
训练之前初始化全局variables,再以64个训练样本为mini-batch,训练我们的模型。
tf.global_variables_initializer().run()
train_size = x_train.shape[0]
batch = 64
for i in range(1000):
start = i*batch % train_size
end = (i+1)*batch % train_size
#print(start, end)
if start > end:
start = 0
batch_x = x_train[start:end]
batch_y = y_train[start:end]
sess.run(train_step,feed_dict={x:batch_x,y_:batch_y})模型评估
完成模型训练后,我们需要对模型的性能进行评估,观察模型的性能是否符合我们的需求。
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(accuracy.eval({x: x_valid, y_: y_valid}))output:0.91
结束语
我们用Tensorflow实现了Softmax回归模型,并在MNIST数据集上取得约91%的成绩。虽然这个成绩比传统的机器学习算法表现更差,但是,我们对Tensorflow的运行有了一个直观的认识。在后面的几篇文章中,我们将用Tensorflow实现更高级的算法,实现可以商用的算法,准确高达99.8%。