LeNet、AlexNet、GoogLeNet、VGG、ResNetInception-ResNet-v2、FractalNet、DenseNet
2006年Hinton他们的Science Paper再次引起人工神经网络的热潮,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服。当时有流传的段子是Hinton的学生在台上讲paper时,台下的机器学习大牛们不屑一顾,质问你们的东西有理论推导吗?有数学基础吗?搞得过SVM之类吗?回头来看,就算是真的,大牛们也确实不算无理取闹,是骡子是马拉出来遛遛,不要光提个概念。
时间终于到了2012年,Hinton的学生Alex Krizhevsky在寝室用GPU死磕了一个Deep Learning模型,一举摘下了视觉领域竞赛ILSVRC 2012的桂冠,在百万量级的ImageNet数据集合上,效果大幅度超过传统的方法,从传统的70%多提升到80%多。个人觉得,当时最符合Hinton他们心境的歌非《我不做大哥好多年》莫属。
这个Deep Learning模型就是后来大名鼎鼎的AlexNet模型。这从天而降的AlexNet为何能耐如此之大?有三个很重要的原因:
- 大量数据,Deep Learning领域应该感谢李飞飞团队搞出来如此大的标注数据集合ImageNet;
- GPU,这种高度并行的计算神器确实助了洪荒之力,没有神器在手,Alex估计不敢搞太复杂的模型;
- 算法的改进,包括网络变深、数据增强、ReLU、Dropout等,这个后面后详细介绍。
- 数据扩展:裁剪,镜像,平移,旋转,颜色,光照等。
从此,Deep Learning一发不可收拾,ILSVRC每年都不断被Deep Learning刷榜,如图1所示,随着模型变得越来越深,Top-5的错误率也越来越低,目前降到了3.5%附近,而在同样的ImageNet数据集合上,人眼的辨识错误率大概在5.1%,也就是目前的Deep Learning模型的识别能力已经超过了人眼。而图1中的这些模型,也是Deep Learning视觉发展的里程碑式代表。
图1. ILSVRC历年的Top-5错误率
在仔细分析图1中各模型结构之前我们先需要了解一下深度学习三驾马车之一————LeCun的LeNet网络结构。为何要提LeCun和LeNet,因为现在视觉上这些神器都是基于卷积神经网络(CNN)的,而LeCun是CNN的祖师爷,LeNet是LeCun打造的CNN经典之作。
LeNet以其作者名字LeCun命名,这种命名方式类似的还有AlexNet,后来又出现了以机构命名的网络结构GoogLeNet、VGG,以核心算法命名的ResNet。LeNet有时也被称作LeNet5或者LeNet-5,其中的5代表五层模型。不过别急,LeNet之前其实还有一个更古老的CNN模型。
最古老的CNN模型
1985年,Rumelhart和Hinton等人提出了后向传播(Back Propagation,BP)算法[1](也有说1986年的,指的是他们另一篇paper:Learning representations by back-propagating errors),使得神经网络的训练变得简单可行,这篇文章在Google Scholar上的引用次数达到了19000多次,目前还是比Cortes和Vapnic的Support-Vector Networks稍落后一点,不过以Deep Learning最近的发展劲头来看,超越指日可待。
几年后,LeCun利用BP算法来训练多层神经网络用于识别手写邮政编码[2],这个工作就是CNN的开山之作,如图2所示,多处用到了5*5的卷积核,但在这篇文章中LeCun只是说把5*5的相邻区域作为感受野,并未提及卷积或卷积神经网络。关于CNN最原始的雏形感兴趣的读者也可以关注一下文献[10]。
图2. 最古老的CNN网络结构图
LeNet
1998年的LeNet5[4]标注着CNN的真正面世,但是这个模型在后来的一段时间并未能火起来,主要原因是费机器(当时苦逼的没有GPU啊),而且其他的算法(SVM,老实说是你干的吧?)也能达到类似的效果甚至超过。
图3. LeNet网络结构
初学者也可以参考一下Caffe中的配置文件:
https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet.prototxt
AlexNet、VGG、GoogLeNet、ResNet对比
LeNet主要是用于识别10个手写数字的,当然,只要稍加改造也能用在ImageNet数据集上,但效果较差。而本文要介绍的后续模型都是ILSVRC竞赛历年的佼佼者,这里具体比较AlexNet、VGG、GoogLeNet、ResNet四个模型。如表1所示。
| 模型名 | AlexNet | VGG | GoogLeNet | ResNet |
|---|---|---|---|---|
| 初入江湖 | 2012 | 2014 | 2014 | 2015 |
| 层数 | 8 | 19 | 22 | 152 |
| Top-5错误 | 16.4% | 7.3% | 6.7% | 3.57% |
| Data Augmentation | + | + | + | + |
| Inception(NIN) | – | – | + | – |
| 卷积层数 | 5 | 16 | 21 | 151 |
| 卷积核大小 | 11,5,3 | 3 | 7,1,3,5 | 7,1,3,5 |
| 全连接层数 | 3 | 3 | 1 | 1 |
| 全连接层大小 | 4096,4096,1000 | 4096,4096,1000 | 1000 | 1000 |
| Dropout | + | + | + | + |
| Local Response Normalization | + | – | + | – |
| Batch Normalization | – | – | – | + |
AlexNet
接下里直接上图即可,AlexNet结构图如下:
图4. AlexNet网络结构
换个视角:
图5. AlexNet网络结构精简版
AlexNet相比传统的CNN(比如LeNet)有哪些重要改动呢:
(1) Data Augmentation
数据增强,这个参考李飞飞老师的cs231课程是最好了。常用的数据增强方法有:
- 水平翻转
- 随机裁剪、平移变换
- 颜色、光照变换
(2) Dropout
Dropout方法和数据增强一样,都是防止过拟合的。Dropout应该算是AlexNet中一个很大的创新,以至于Hinton在后来很长一段时间里的Talk都拿Dropout说事,后来还出来了一些变种,比如DropConnect等。
(3) ReLU激活函数
用ReLU代替了传统的Tanh或者Logistic。好处有:
- ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作;
- ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作;
- ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0;
- ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。
当然,ReLU也是有缺点的,比如左边全部关了很容易导致某些隐藏节点永无翻身之日,所以后来又出现pReLU、random ReLU等改进,而且ReLU会很容易改变数据的分布,因此ReLU后加Batch Normalization也是常用的改进的方法。
(4) Local Response Normalization
Local Response Normalization要硬翻译的话是局部响应归一化,简称LRN,实际就是利用临近的数据做归一化。这个策略贡献了1.2%的Top-5错误率。
(5) Overlapping Pooling
Overlapping的意思是有重叠,即Pooling的步长比Pooling Kernel的对应边要小。这个策略贡献了0.3%的Top-5错误率。
(6) 多GPU并行
这个不多说,比一臂之力还大的洪荒之力。
VGG
VGG结构图
图6. VGG系列网络结构
换个视角看看VGG-19:
图7. VGG-19网络结构精简版
VGG很好地继承了AlexNet的衣钵,一个字:深,两个字:更深。
GoogLeNet
图8. GoogLeNet网络结构
GoogLeNet依然是:没有最深,只有更深。
主要的创新在于他的Inception,这是一种网中网(Network In Network)的结构,即原来的结点也是一个网络。Inception一直在不断发展,目前已经V2、V3、V4了,感兴趣的同学可以查阅相关资料。Inception的结构如图9所示,其中1*1卷积主要用来降维,用了Inception之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
图9. Inception结构
ResNet
网络结构如图10所示。
图10. ResNet网络结构
ResNet依然是:没有最深,只有更深(152层)。听说目前层数已突破一千。
主要的创新在残差网络,如图11所示,其实这个网络的提出本质上还是要解决层次比较深的时候无法训练的问题。这种借鉴了Highway Network思想的网络相当于旁边专门开个通道使得输入可以直达输出,而优化的目标由原来的拟合输出H(x)变成输出和输入的差H(x)-x,其中H(X)是某一层原始的的期望映射输出,x是输入。
图11. ResNet网络结构
总结
Deep Learning一路走来,大家也慢慢意识到模型本身结构是Deep Learning研究的重中之重,而本文回顾的LeNet、AlexNet、GoogLeNet、VGG、ResNet又是经典中的经典。
16年又有很多网络提出来,比较典型的有
Inception-ResNet-v2: 将深度和宽带融合到一起
为了进一步推进这个领域的进步,今天Google团队宣布发布Inception-ResNet-v2(一种卷积神经网络——CNN),它在ILSVRC图像分类基准测试中实现了当下最好的成绩。Inception-ResNet-v2是早期Inception V3模型变化而来,从微软的残差网络(ResNet)论文中得到了一些灵感。相关论文信息可以参看我们的论文Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning(Inception-v4, Inception-ResNet以及残差连接在学习上的影响):

残差连接(Residual connections )允许模型中存在shortcuts,可以让研究学者成功地训练更深的神经网络(能够获得更好的表现),这样也能明显地简化Inception块。将两种模型架构对比,见下图:
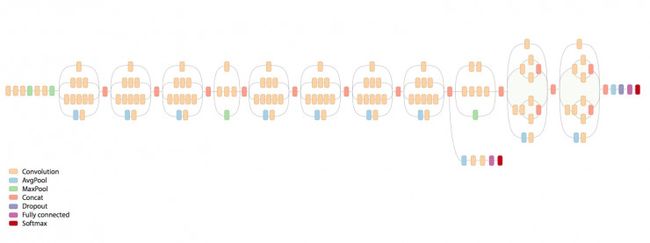
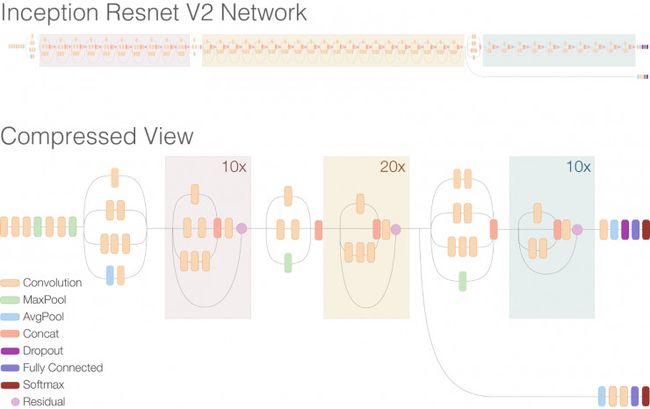
在第二幅Inception-ResNet-v2图中最上部分,你能看到整个网络扩展了。注意该网络被认为比先前的Inception V3还要深一些。在图中主要部分重复的残差区块已经被压缩了,所以整个网络看起来更加直观。另外注意到图中inception区块被简化了,比先前的Inception V3种要包含更少的并行塔 (parallel towers)。
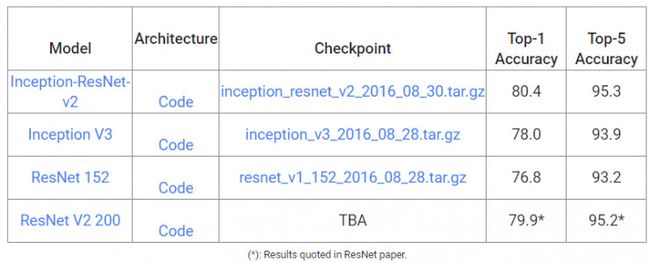
如下方图表所示,Inception-ResNet-v2架构的精确度比之前的最优模型更高,图表中所示为基于单个图像的ILSVRC 2012图像分类标准得出的排行第一与排行第五的有效精确度。此外,该新模型仅仅要求两倍于Inception v3的容量与计算能力。
例如,尽管Inception v3与Inception-ResNet-v2都很擅长识别每一条狗所属的类别,这种新模型的性能更为显著。例如,旧模型可能会错误地将右边的图片识别为阿拉斯加雪橇犬,新模型Inception-ResNet-v2能够准确地识别两个图片中狗的类别。

阿拉斯加雪橇犬(左)和西伯利亚雪橇犬(右)。图片来源:维基百科。
为了使人们理解开始试验,我们也将要发布新型Inception-ResNet-v2预训练实例,作为TF-Slim 图像模型库的组成部分。
看到本研究领域关于这一经过改进的模型所取得的进展,而且人们开始采用这种新模型,并将其性能在多种任务作对比,我们为此感到非常兴奋。你也想要开始使用这种新模型吗?让我们一起来看看附带的操作指示,学会如何训练,评估或微调一个网络。
Inception-ResNet-v2具体代码实现过程参见:
https://github.com/tensorflow/models/blob/master/slim/nets/inception_resnet_v2.py
随着2012年AlexNet的一举成名,CNN成了计算机视觉应用中的不二选择。目前,CNN又有了很多其他花样,比如R-CNN系列,
FractalNet
ResNet 是 ImageNet 2015 冠军,通过让网络对残差进行学习,在深度和精度上做到了比CNN 更加强大。于是有人认为残差结构对此很重要,本文提出一个不依赖于残差的极深(Ultra-Deep)架构,指出残差学习对极深CNN 并非必需。论文提出了极深CNN 中首个 ResNet 的替代品 FractalNet,并开发了一种新的正则化规则,无需数据增强就能大幅超越残差网络性能。作者称该结构可以自动容纳过去已有的强大结构。
-
【题目】分形网络:无残差的极深神经网络(FractalNet:Ultra-Deep Neural Networks without Residuals)
-
【作者】芝加哥大学 GustavLarsson,丰田工大学芝加哥分校 Michael Maire及 Gregory Shakhnarovich
我们为神经网络的宏观架构引进了一种基于自相似的设计策略。单一扩展规则的重复应用生成一个极深的网络,其结构布局正是一个截断的分形。这样的网络包含长度不同的相互作用子路径,但不包含任何直通式连接(pass-through connections):每个内部信号在被下一层看见之前,都被一个过滤器和非线性部件变换过了。这个性质与当前显式规划极深网络的结构使得训练成为一个残差学习问题的方法形成鲜明对比。我们的实验表明,残差表示不是极深卷积神经网络成功的基本要素。分形设计在 CIFAR-100 数据集(https://www.cs.toronto.edu/~kriz/cifar.html) 上达到 22.85% 的错误率,与残差网络的最佳水平持平。
除了高性能之外,分形网络还展现了有趣的性质。它们可被认为是各种深度的子网络的隐式联合且计算效率高。我们探讨了对于训练的影响,简单提及了与“师徒”行为的联系,最重要的,展示了提取高性能固定深度子网络的能力。为了实现后一个任务,我们发展路径舍弃方法(drop-path;对 dropout 的自然扩展)正则化分形架构里子路径的协同适应。通过这样的正则化,分形网络展示了一种无例外的性质:浅层子网络给出快捷的答案,而深度子网络(有较多延迟)给出更精准的答案。
最近的 ResNet 在深度和精度上比卷积神经网络(CNN)做出了极大进步,方法是让网络对残差进行学习。ResNet 的变型以及类似的架构通过直接通道(pass-through channel;相当于恒等函数的网络)使用了共同的初始化和锚定技术。这样,训练有两个方面不同。第一,目标变成对残差输出的学习而不是对未被提及的绝对映射学习。第二,这些网络展示了一种深度监督,因为接近恒等的层有效减少了损失距离。何恺明等人 推测前者(即残差的构造)是关键的。
答案并非如此。我们通过构造不依赖于残差的极深架构揭示了这一点。我们的设计原则非常单纯,用“分形”一个词以及一幅图(图 1)就足以描述。可是,分形网络隐含地重现了过去的成功架构里硬性加入的许多性质。深度监督不仅自然出现,并且驱动了一种网络内部的“师徒学习”(student-teacher learning)。其他设计的模块化构成单元几乎都是分形网络嵌套子结构的特殊情形。
对于分形网络,训练的简单性与设计的简单性相对应。单个连接到最后一层的损失函数足以驱动内部行为去模仿深度监督。参数是随机初始化的。由于包含不同深度的子网络,分形网络对总体深度的选取不敏感;让深度足够,然后训练会刻划出有用的子网络集合。
图 1:分形架构。左:简单的扩展规则生成分形架构。基础情形 f1(z) 包含输入输出之间单个选定类型的层 (比如卷积层)。连接层计算了逐元素平均。右:深度卷积网络周期性地通过汇集来降低空间分辨率。分形版本使用 fC 作为汇集层之间的建构单元。把 B 个这样的块堆起来就得到一个网络,其总深度是 B * 2^{C-1} (通过卷积层衡量)。这个例子的深度是 40 (B = 5, C = 4)。
分形设计导致的一系列涌现行为可能会让近期为了达到类似效果发展出的工程技巧变得不那么必要。这些技巧包括,恒等初始化的残差函数形式,手动深度监督,手工雕琢的架构模块,以及师徒训练体系。第 2 节回顾了这些相互关联的技术。混合设计当然可以把它们中任何一个与分形架构集成;关于这种混合体在多大程度上是多余或是互相促进这个问题,我们持开放态度。
我们的主要贡献有以下两点:
-
引入了 FractalNet,第一个在极深卷积神经网络领域对于ResNet 的替代品。FractalNet 在科学上令人吃惊,它表明了残差学习对于极深网络不是必需的。
-
通过分析和实验,我们阐释了FractalNet 与一系列被加入到之前深度网络设计的那些现象之间的联系。
还有一个贡献,我们为极深网络开发了一种称为路径舍弃的新的正则化规则。已有的关于深度残差网络的工作其实缺乏有效正则化技术的展示,而仅仅依赖于数据增强。无需数据增强,通过 dropout 和路径舍弃训练的分形网络远远超过了报道的残差网络的性能。
路径舍弃不仅是一种直观的正则化策略,而且提供了保证训练出的分形网络拥有无例外性质的方法。具体来说,训练期间对路径舍弃的特定安排阻止了不同深度的子网络的协同适应。结果就是,浅和深的网络必需各自能输出正确结果。测试期间,对浅子网络的请求在整个网络完成之前给出快速而精度普通的答案。
第 3 节给出了分形网络和路径舍弃的细节。第 4 节提供了基于 CIFAR-10, CIFAR-100 以及 SVHN 数据集与残差网络的比较。我们还评估了正则化和数据增强策略,探究了训练期间的子网络师徒行为,评价了通过路径舍弃得到的 anytime 网络。第 5 节提供了综合。通过容纳许多已知但看起来不同的设计原理,自相似结构也许会变成神经网络架构的基本组件。
2. 相关研究(略)
我们从对图1中描绘的想法的正式陈述开始。我们将以卷积神经网络作为例子和实验平台。但是,需要强调我们的框架更有一般性。原则上,为了生成其他分形架构,图1 中的卷积层可以被替换为不同的层类型,甚至是定制化的模块或子网络。
令C 表示截断分形 fC(.)的指标。我们的网络结构、连接以及层类型,通过 f C(.) 定义。包含单个卷积层的网络是基础情形:
f1(z)= conv(z) (1)
我们递归定义接下来的分形:
f{C1}(z)= [ (fCo fC)(z)] ⊕[ conv(z) ] (2)
这里 o 表示复合,而 ⊕ 表示连接操作。当以图 1 的风格来画时,C 对应于列数,或者说网络fC(.)的宽度。深度定义为从输入到输出的最长路径上的 conv 层的个数,正比于2^{C-1}。用于分类的卷积网络通常分散布置汇集层。为了达到相同目的,我们使用 fC(.) 作为构建单元,将之与接下来的汇集层堆叠B 次,得到总深度 B * 2^{C-1}。
连接操作 ⊕ 把两个特征块合为一个。这里,一个特征块是一个conv 层的结果:在一个空间区域为固定的一些通道维持活化的张量。通道数对应于前面的 conv层的过滤器的个数。当分形被扩展,我们把相邻的连接合并成单个连接层;如图 1右侧所示,这个连接层跨越多列。连接层把所有其输入特征块合并成单个输出块。
连接层行为的几种选择看起来都是合理的,包括拼接和加法。我们把每个连接实例化,计算其输入的逐元素平均。这对于卷积网络是恰当的,在那里通道数对一个分形块里的所有conv 层是相同的。平均操作可能看起来类似 ResNet 的加法操作,但有几个关键不同:
-
ResNet 明确区分了直接通过与残差信号。在 FractalNet里,没有什么信号是优越的。每一个对联合层的输入是上一个 conv层的输出。单凭网络结构本身不能识别什么是主要的。
-
路径舍弃正则化,如第 3.1节描述,强制让每个连接层的输入独自可靠。这降低了回报,即便是隐式学习把一个信号的一部分作为另一个的残差这种情形。
-
实验表明我们可以提取仅包含一列的高性能子网络 (4.2节)。这样的子网络实际上不包含连接。它们不提供可以与残差相加的信号。
这些性质保证了连接层不是残差学习的一个替代方法。
3.1 基于路径舍弃的正则化
Dropout[10] 和 drop-connect [35] 通过修改网络层序列之间的相互作用来减弱共同适应(co-adaptation)。由于分形网络包含额外的大尺度结构,我们提出使用一种类似的粗粒度正则化策略来辅助这些技术。
图 2 解释了路径舍弃。如同 dropout禁止了活化的共同适应,路径舍弃通过随机丢弃连接层的操作数来禁止平行路径的共同适应。这压制了网络使用一个路径作为锚标,用另一个作为修正(这可能导致过拟合) 的行为。我们考虑两个采样策略:
-
局部:连接层以固定几率舍弃每个输入,但我们保证至少一个输入保留。
-
全局:每条路径是为了整个网络选出的。我们限制这条路径是单列的,激励每列成为有力的预测器。
如同dropout,信号可能需要恰当的缩放。对于逐元素平均,这是平凡的;连接仅仅计算了活跃输入的平均。
图 2:分形网络。某些层之间的连接被停用后仍能工作,前提是从输入到输出的某些路径还存在。路径舍弃保证至少一条这样的路径存在,与此同时许多其它路径被停用。训练期间,对每个 mini-batch 展示不同的活跃子网络阻止了平行路径的共同适应。全局采样策略返回单列作为子网络。与局部采样交替使用鼓励了每列发展为表现良好的单独运作的子网络。
实验中,我们使用了 dropout 以及对路径舍弃采用了 50% 局部以及 50%全局的混合采样。我们在每个 mini-batch 采样一个新的子网络。内存足够的情况下,对每个mini-batch,我们可以同时对一个局部样本和所有全局样本求值。
全局路径舍弃不仅仅是作为一个正则化器,也是一个诊断工具。监控单列的表现体提供了关于网络和训练机制的洞察,这将在 4.3节进一步提及。单个强大的列也让使用者在速度和精度方面取舍。
3.2 数据增强
数据增强可以显著降低对正则化的需求。ResNet 展示了这一点,对 CIFAR-100 数据集从44.76%的错误率降低到27.22%。虽然数据增强对分形网络有好处,我们提出一点,那就是路径舍弃提供了高度有效的正则化,让它们无需数据增强也能达到有竞争力的结果。
3.3 优化
我们使用含冲量的随机梯度下降来训练分形网络。我们对每个 conv层引进批量归一化(卷积,批量归一化,ReLU)。
我们使用 Caffe 实现 FractalNet。纯粹为了实现的方便,我们把图 1 中汇集和连接层的顺序翻转了。每列在跨越所有列的连接层之前单独汇集,而不是在那之后。
我们采用 CIFAR-100, CIFAR-10 以及 SVHN 作为比较用的数据集。我们评估在每个数据集的标准分类任务上的表现。这些数据集都由 32 x 32 图片组成,所以我们固定分形网络的块数为 5 (B=5),采用 2 x 2 的不重叠的 max-pooling。这就把输入的 32 x 32 分辨率变成 1 x 1。网络终端连接了 softmax 的预测层。
除非专门提及,我们把5个块中过滤器的个数设为(64,128, 256, 512, 512)。这个递增数列类似于 VGG-16 和 ResNet。这符合分辨率降低一半后通道数加倍的传统。
4.1 训练
对于使用 dropout 的实验,我们固定每块的丢弃率为 (0%, 10%, 20%, 30%, 40%)。局部路径舍弃采用 15% 的舍弃率。
我们在 CIFAR-10/CIFAR-100 上训练了 400 个 epoch,在 SVHN 上训练了 20 个 epoch;每当剩余的 epoch 数减半,我们就把学习速率缩小 10。学习速率初始为 0.2。我们使用随机梯度下降方法,批处理大小为 100,冲量为 0.9。对参数使用 Xavier 初始化。
对 CIFAR-10 和 CIFAR-100 有标准的数据增强技术,仅包含平移和镜像翻转。平移量是 -4 到 4 的随机数。有必要的时候图像在减去平均值后以 0 补全。一半的图像水平被翻转。我们给使用的数据增强不超过这些所得到的结果标记为“+”。标记为“ ”的使用了更多的增强技术;精确的策略可能会不一样。
4.2 结果
表1.CIFAR-100/CIFAR-10/SVHN.
表 1 报告了 FractalNet 的表现,对应 C = 3 列,应用到 CIFAR 和 SVHN分类任务上。也列了所有竞争方法的分数。整个表上 FractalNet 超过了原始 ResNet的表现。使用数据增强后,FractalNet 在 CIFAR-100 上的表现几乎跟 ResNet的最佳变型一模一样。不使用数据增强和正则化,我们模型在 CIFAR-100 和 CIFAR-10 上的表现优于 ResNet 和随机深度的 ResNet。这提示与 ResNet 相比FractalNet 可能不那么容易过拟合。所有方法在 SVHN上表现都不错,因此那个数据集没什么区分度。
不使用数据增强的实验强调了路径舍弃正则化的能力。对于 CIFAR-100,添加路径舍弃把错误率从35.34% 降低到 28.20%。未正则化的 ResNet 则差得远 (44.76%),而通过随机深度正则化的 ResNet达到的错误率为 37.80%,还不如我们未正则化的错误率 35.34%。CIFAR-10上表现类似。
与数据增强组合起来后,路径舍弃要么提高了精度,或者效果不显著。通过路径舍弃,FractalNet 在CIFAR-10 上达到所有模型中的最佳误差率。
对于CIFAR-10,分形网络的最深的那列统计上与整个网络在统计上不能区分。这提示,对于这个任务,分形网络可能更重要的是作为学习框架,而不是最终的模型架构。
表2. FractalExpansion.
表 2 表明 FractalNet 在通过增加 C 得到极深网络时性能并不下降 (C=6 对应160 层)。这个表里的分数不能跟表 1 里的比。
表3. FractalColumns.
表 3 提供的基准显示,普通深度神经网络当层数达到 40 后就会下降。我们的经验中,普通的 160层的网络完全不能收敛。表 3 还高亮了使用 FractalNet以及路径舍弃作为提取已训练好网络的能力。
4.3 内省
看图 3 中 40 层的分形网络训练期间的演化。通过追踪每一列我们发现,40层的列一开始改进缓慢,但当网络中其它部分的损失开始稳定后会加快。普通的 40层网络从来不会快速改进。
图3.
我们猜测分形结构触发了类似于深度监督和以及师徒信息流的效应。第 4 列每隔一层就与第 3列连接,而每隔 4 层这个连接不涉及别的列。当分形网络部分依赖于信号从第 3 列流过,路径舍弃对第 4 列施加压力,以产生一个当第 3列被移除时的替代信号。一个特定的舍弃仅仅需要第 4 列中两个相邻层代替第 3列中的一层。这相当于小小的师徒问题。
FractalNet展示了路径长度对训练极深神经网络至关重要;而残差的影响是偶然的。关键在于 FractalNet和 ResNet 具有共同特性:标称网络深度很大,但训练过程中梯度传播的有效路径更短。分形结构可能是满足这一需求的最简单方式,并且能达到甚至超越循环网络的经验性能。它们能避免深度太大;过多的深度会使训练变慢,但不会增加准确度。
通过 drop-path极深分形网络的正则化是直接而有效的。对于需要快速回应的应用,drop-path能对分形网络里的延迟和精确性做折中。
我们的分析连接了分形网络中的突发内部行为与构建在其他设计中的现象。分形网络的子结构与一些卷积网络中作为结构模块的人工设计模块相似。它们的进化或许能仿真深度监视和师徒学习。
(DenseNet), 将所有层都连接到最后
[参考文献]
[1] DE Rumelhart, GE Hinton, RJ Williams, Learning internal representations by error propagation. 1985 – DTIC Document.
[2] Y. LeCun , B. Boser , J. S. Denker , D. Henderson , R. E. Howard , W. Hubbard and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition”, Neural Computation, vol. 1, no. 4, pp. 541-551, 1989.
[3] Kaiming He, Deep Residual Learning, http://image-net.org/challenges/talks/ilsvrc2015_deep_residual_learning_kaiminghe.pdf
[4] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
[5] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
[6] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich: Going deeper with convolutions. CVPR 2015: 1-9
[7] Karen Simonyan, Andrew Zisserman: Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR abs/1409.1556 (2014)
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
[9] 一些对应的caffe实现或预训练好的模型: https://github.com/BVLC/caffe https://github.com/BVLC/caffe/wiki/Model-Zoo
[10] K. Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4): 93-202, 1980.