想自己动手写一个CNN很久了,论文和代码之间的差距有一个银河系那么大。
在实现两层的CNN之前,首先实现了UFLDL中与CNN有关的作业。然后参考它的代码搭建了一个一层的CNN。最后实现了一个两层的CNN,码代码花了一天,调试花了5天,我也是醉了。这里记录一下通过代码对CNN加深的理解。
首先,dataset是MNIST。这里层的概念是指convolution+pooling,有些地方会把convolution和pooling分别作为两层看待。
1.CNN的结构
这个两层CNN的结构如下:
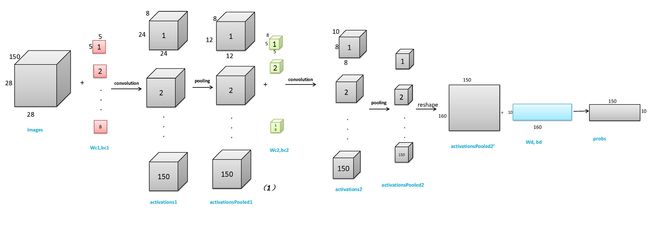
图一
各个变量的含义如下(和代码中的变量名是一致的)
images:输入的图片,一张图片是28*28,minibatch的大小设置的是150,所以输入就是一个28*28*150的矩阵。
Wc1,bc1:第一层卷积的权重和偏置。一共8个filter,每个大小为5*5。
activations1:通过第一层卷积得到的feature map,大小为(28-5+1)*(28-5+1)*8*150,其中8是第一层卷积filter的个数,150是输入的image的个数。
activationsPooled1:将卷积后的feature map进行采样后的feature map,大小为(24/2)*(24/2)*8*150。
Wc2,bc2:第二层卷积的权重和偏置。一共10个filter,每个大小为5*5*8.注意第二层的权重是三维的,这就是两层卷积网络和一层卷积网络的差别,对于每张图像,第一层输出的对应这张图像的feature map是12*12*8,而第二层的一个filter和这个feature map卷积后得到一张8*8的feature map,所以第二层的filter都是三维的。具体操作后面再详细介绍。
activations2:通过第二层卷积得到的feature map,大小为(12-5+1)*(12-5+1)*10*150,其中10是第二层卷积filter的个数,150是输入的image的个数。
activationsPooled2:将卷积后的feature map进行采样后的feature map,大小为(8/2)*(8/2)*10*150。
activationsPooled2':第二层卷积完了之后,要把一张image对应的所有feature map reshape成一列,那么这一列的长度就是4*4*10=160,所以reshape后得到一个160*150的大feature map.(代码中仍然是用的activationsPooled2)。
Wd,bd:softmax层的权重和偏执。
probs:对所有图像所属分类的预测结果,每一列对应一张图像,一共10行,第i行代表这张图像属于第i类的概率。
从实现的角度来说,一个CNN主要可以分成三大块:Feedfoward Pass,Caculate cost和 Backpropagation.这里就详细介绍这三块。
2. Feedfoward Pass
这个过程主要是输入一张图像,通过目前的权重,使得图像依次通过每一层的convolution或者pooling操作,最后得到对图像分类的概率预测。这里比较tricky的部分是对三维的feature map的卷积过程。比如说对于第一层pooling输出的feature map,一张图像对应一个尺寸为12*12*8的feature map,这个时候要用第二层卷积层中一个5*5*8的filter(Wc2中的一个filter)和它进行卷积,最终得到一个8*8的feature map。整个过程可以用图二,图三来表示:
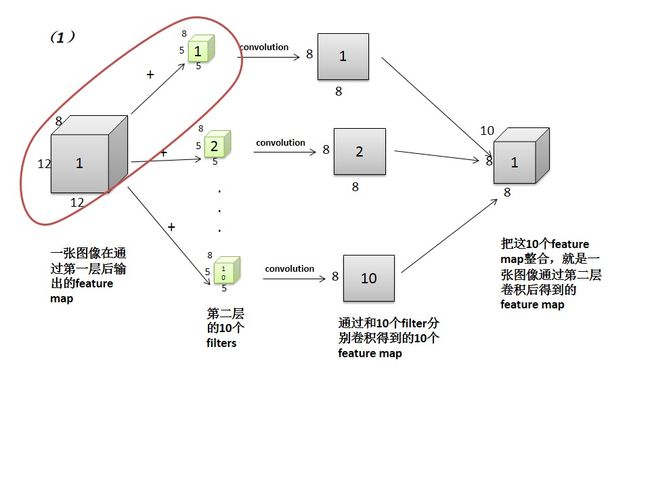
图二
继续放大,来看看输入的feature map是怎样和第二层的一个filter进行卷积的:

图三
也就是说,这个卷积是通过filter中每一个filter:Wc2(:,:,fil1,fil2)和activationsPooled1(:,:,fil1,imageNum)卷积,然后将所有的fil1=1:8得到的全部结果相加后得到最后的
1 for i = 1:numImages 2 for fil2 = 1:numFilters2 3 convolvedImage = zeros(convDim, convDim); 4 for fil1 = 1:numFilters1 5 filter = squeeze(W(:,:,fil1,fil2)); 6 filter = rot90(squeeze(filter),2); 7 im = squeeze(images(:,:,fil1,i)); 8 convolvedImage = convolvedImage + conv2(im,filter,'valid'); 9 end 10 convolvedImage = bsxfun(@plus,convolvedImage,b(fil2)); 11 convolvedImage = 1 ./ (1+exp(-convolvedImage)); 12 convolvedFeatures(:, :, fil2, i) = convolvedImage; 13 end 14 end
最后整个Feedforward的过程代码如下:
1 %Feedfoward Pass 2 activations1 = cnnConvolve4D(mb_images, Wc1, bc1); 3 activationsPooled1 = cnnPool(poolDim1, activations1); 4 activations2 = cnnConvolve4D(activationsPooled1, Wc2, bc2); 5 activationsPooled2 = cnnPool(poolDim2, activations2); 6 7 % Reshape activations into 2-d matrix, hiddenSize x numImages, 8 % for Softmax layer 9 activationsPooled2 = reshape(activationsPooled2,[],numImages); 10 11 %% --------- Softmax Layer --------- 12 probs = exp(bsxfun(@plus, Wd * activationsPooled2, bd)); 13 sumProbs = sum(probs, 1); 14 probs = bsxfun(@times, probs, 1 ./ sumProbs); 15
3. Caculate cost
这里使用的loss function是cross entropy function,关于这个函数的细节可以看这里。这个函数比起squared error function的好处是它在表现越差的时候学习的越快。这和我们的直觉是相符的。而对于squared error function,它在loss比较大的时候反而进行的梯度更新值很小,即学习的很慢,具体解释也参见上述链接。计算cost的代码十分直接,这里直接使用了ufldl作业中的代码。
1 logp = log(probs); 2 index = sub2ind(size(logp),mb_labels',1:size(probs,2)); 3 ceCost = -sum(logp(index)); 4 wCost = lambda/2 * (sum(Wd(:).^2)+sum(Wc1(:).^2)+sum(Wc2(:).^2)); 5 cost = ceCost/numImages + wCost;
注意ceCost是loss function真正的cost,而wCost是weight decay引起的cost,我们期望学习到的网络的权重都偏小,对于这一点现在没有很完备的解释,我们期望权值比较小的一个原因是小的权值使得输入波动比较大的时候,网络的各部分的值变化不至于太大,否则网络会不稳定。
4. Backpropagation
Backpropagation算法其实可以分成两部分:计算error和gradient
4.1 caculate error of each layer
对于每一层生成的feature map,我们计算一个误差(残差),说明这一层计算出来的结果和它应该给出的“正确”结果之间的差值。
计算这个误差的过程,其实就是“找源头”的过程,只要知道某张feature map和该层的哪些filter生成了下一层的哪些feature map,然后用下一层feature map对应的误差和filter就可以得到要计算的feature map对应的误差了。
那么对于最后一层softmax的误差就很好理解了,就是ground truth的labels和我们所预测的结果之间的差值:
1 output = zeros(size(probs)); 2 output(index) = 1; 3 DeltaSoftmax = (probs - output); 4 t = -DeltaSoftmax;
output是把ground truth的labels整成一个10*150的矩阵,output(i,j)=1表示图像j属于第i类,output(i,j)=0表示图像j不属于第i类。
接下来把这个残差一层层的依次推回到pooling2->convolution2->pooling1->convolution1这些层。
用到的公式是以下四个,具体的推倒参见这里,下面也会有一部分对这些公式直观的解释。

4.1.1 pooling2层的误差
这一层比较简单,根据上面的公式BP2,我们直接可以用Wd' * DeltaSoftmax就可以得到这一层的误差(因为这一层没有sigmoid函数,所以没有BP2后面的导数部分)。当然,Wd是一个10*160的矩阵,而DeltaSoftmax和probs同维度,即10*150(参见图一),它们相乘后得到160*150的矩阵,其中每一列对应一张图像的误差。而我们所要求得pooling2层的feature map的维度是4*4*10*150,所以我们要把得到的160*150的矩阵reshape成pooling2的feature map所对应的误差。具体代码如下:
DeltaPool2 = reshape(Wd' * DeltaSoftmax,outputDim2,outputDim2,numFilters2,numImages);
得到pooling2层的误差后,一个很重要的操作是unpool的过程。为什么要用这个过程呢?我们先来看一个简单的pooling过程:
假设有一张4*4的feature map,对它进行average pooling:

在上面的pooling过程中,采样后的featuremap中红色部分的值来自于未采样的feature map中红色部分的4个值取平均,所以红色部分的值的误差,就由这4个红色的值“负责”,这个误差在unpool的过程中就在这4个值对应的error上均分。其他颜色的部分同样的道理。unpool部分的代码由conv函数和kron函数共同实现,具体的解释参考这里。代码如下:
1 DeltaUnpool2 = zeros(convDim2,convDim2,numFilters2,numImages); 2 for imNum = 1:numImages 3 for FilterNum = 1:numFilters2 4 unpool = DeltaPool2(:,:,FilterNum,imNum); 5 DeltaUnpool2(:,:,FilterNum,imNum) = kron(unpool,ones(poolDim2))./(poolDim2 ^ 2); 6 end 7 end
4.1.2 convolution2的误差
有了上述unpool的误差,我们就可以直接用公式BP2计算了:
DeltaConv2 = DeltaUnpool2 .* activations2 .* (1 - activations2);
其中的activations2 .* (1 - activations2)对应BP2中的σ'(z),这是sigmoid函数一个很好的性质。
4.1.3 pooling1的误差
这一层的误差计算的关键同样是找准“源头”。在feedfoward的过程中,第二层的convolution过程如下:

假设我们要求第一张图像的第二张feature map(黑色那张)对应的误差error。那么我们只要搞清楚它“干了多少坏事”,然后把这些“坏事”加起来就是它的误差了。如上图所示,假设第二层convolution由4个5*5*3的filter,那么这张黑色的feature map分别和这4个filter中每个filters的第二张filter进行过卷积,并且这些卷积的结果分别贡献给了第一张图convolved feature map的第1,2,3,4个feature map(上图convolved feature map中和filter颜色对应的那几张feature map)。所以,要求紫色的feature map的误差,我们用convolved feature map中对应颜色的error和对应颜色filter卷积,然后将所有的卷积结果相加,就可以得到紫色的feature map的error了。如下图所示:
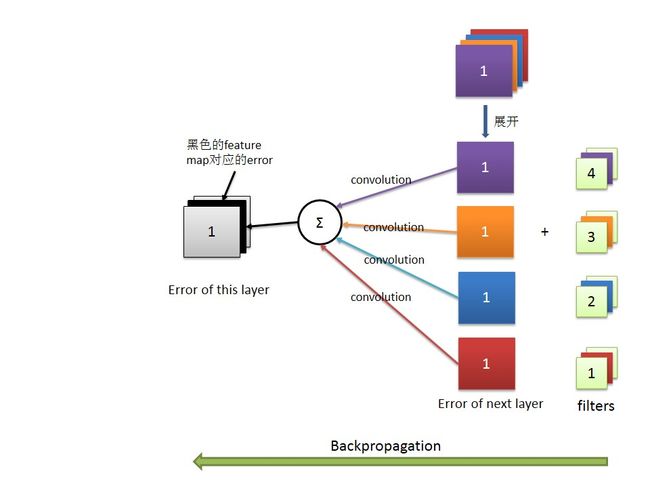
代码如下:
1 %error of first pooling layer 2 DeltaPooled1 = zeros(outputDim1,outputDim1,numFilters1,numImages); 3 for i = 1:numImages 4 for f1 = 1:numFilters1 5 for f2 = 1:numFilters2 6 DeltaPooled1(:,:,f1,i) = DeltaPooled1(:,:,f1,i) + convn(DeltaConv2(:,:,f2,i),Wc2(:,:,f1,f2),'full'); 7 end 8 end 9 end
然后同样进行上面解释过的unpool过程得到DeltaUnpooled1:
1 %error of first convolutional layer 2 DeltaUnpool1 = zeros(convDim1,convDim1,numFilters1,numImages); 3 for imNum = 1:numImages 4 for FilterNum = 1:numFilters1 5 unpool = DeltaPooled1(:,:,FilterNum,imNum); 6 DeltaUnpool1(:,:,FilterNum,imNum) = kron(unpool,ones(poolDim1))./(poolDim1 ^ 2); 7 end 8 end
4.1.4 convolution1的误差
这层的误差还是根据BP2公式计算:
DeltaConv1 = DeltaUnpool1 .* activations1 .* (1-activations1);
4.2 Caculate Gradient
对于梯度的计算类似于误差的计算,对于每一个filter,找到它为哪些feature map的计算“做出贡献”,然后用这些feature map的误差计算相应的梯度并求和。在我们的CNN中,有三个权值Wc1,Wc2,Wd,bc1,bc2,bd的梯度需要计算。
4.2.1 Wd,bd的梯度计算。
这两个梯度十分好计算,只要根据公式BP4计算就可以了,代码如下:
1 % softmax layer 2 Wd_grad = DeltaSoftmax*activationsPooled2'; 3 bd_grad = sum(DeltaSoftmax,2);
4.2.2 Wc2,bc2的梯度计算。
计算Wc2,首先要知道在forward pass过程中,Wc2中的某个filter生成了哪些feature map,然后在用这些feature map的error来计算filter的梯度,feedforward的过程如下图所示:
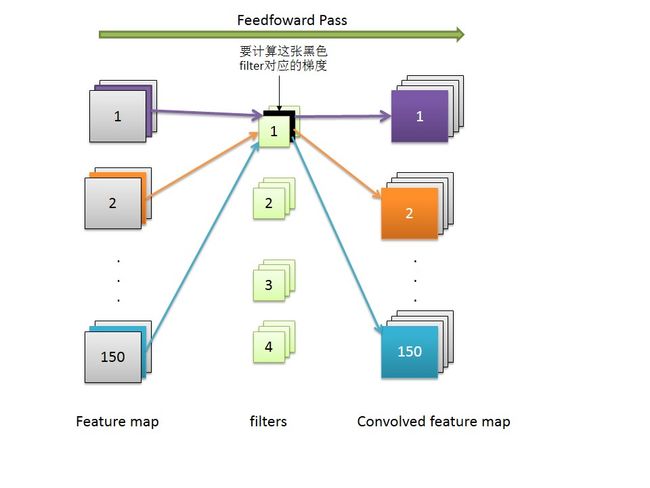
假设我们要计算黑色的filter对应的梯度,在feedforward的过程中,这个filter和左边的pooling1层输出的feature map卷积,生成右边对应颜色的feature map,那么在backpropagation的过程中,我们就用右边这些feature map对应的误差error和左边输入的feature map卷积,最后把每张图像的卷积结果相加,就可以得到黑色的filter对应的梯度了,如下图所示:

代码如下:
1 for fil2 = 1:numFilters2 2 for fil1 = 1:numFilters1 3 for im = 1:numImages 4 Wc2_grad(:,:,fil1,fil2) = Wc2_grad(:,:,fil1,fil2) + conv2(activationsPooled1(:,:,fil1,im),rot90(DeltaConv2(:,:,fil2,im),2),'valid'); 5 end 6 end 7 temp = DeltaConv2(:,:,fil2,:); 8 bc2_grad(fil2) = sum(temp(:)); 9 end
4.2.3 Wc1,bc1的梯度计算。
Wc1和bc1的计算和Wc2,bc2是类似的,只是第一层的输入是图像数据集images,所以只要把上述代码中的numFilters2换成numFilters1,numFilters1换成imageChannel(图像的通道RGB图像对应3,这里用灰度图像,所以imageChannel的值是1),activationsPooled1换成图像集mb_images,DeltaConv2换成DeltaConv1就可以了。
1 % first convolutional layer 2 for fil1 = 1:numFilters1 3 for channel = 1:imageChannel 4 for im = 1:numImages 5 Wc1_grad(:,:,channel,fil1) = Wc1_grad(:,:,channel,fil1) + conv2(mb_images(:,:,channel,im),rot90(DeltaConv1(:,:,fil1,im),2),'valid'); 6 end 7 end 8 temp = DeltaConv1(:,:,fil1,:); 9 bc1_grad(fil1) = sum(temp(:)); 10 end
4.2.4 梯度值更新。
这一步就十分简单了,直接用计算好的梯度去更新权重就可以了。不过使用了冲量和weight decay,其中alpha是学习速率,lambda是weight decay factor,代码如下:
1 Wd_velocity = mom*Wd_velocity + alpha*(Wd_grad/minibatch+lambda*Wd); 2 bd_velocity = mom*bd_velocity + alpha*bd_grad/minibatch; 3 Wc2_velocity = mom*Wc2_velocity + alpha*(Wc2_grad/minibatch+lambda*Wc2); 4 bc2_velocity = mom*bc2_velocity + alpha*bc2_grad/minibatch; 5 Wc1_velocity = mom*Wc1_velocity + alpha*(Wc1_grad/minibatch+lambda*Wc1); 6 bc1_velocity = mom*bc1_velocity + alpha*bc1_grad/minibatch; 7 8 Wd = Wd - Wd_velocity; 9 bd = bd - bd_velocity; 10 Wc2 = Wc2 - Wc2_velocity; 11 bc2 = bc2 - bc2_velocity; 12 Wc1 = Wc1 - Wc1_velocity; 13 bc1 = bc1 - bc1_velocity;
总结以下Backpropagation算法的关键,就是找准误差的源头,然后将这个误差顺着源头从最后一层推回到第一层,沿路根据误差更新权重,以此来训练神经网络。
5. CNN效果及代码
以下是cost在迭代过程中的变化图像,一共进行了3次迭代,每次对400个minibatch进行stochastic gradient descent,每个minibatch有150张图像。

最后的结果:

代码参见我的github。
有趣的一点是,之前我用一层的CNN在MNIST上可以达到97.4%的准确率,换成这个两层的CNN,准确率却下降了。一种可能是我没有进行fine tuning,上述的参数有些是参考别人的,有些是自己随便设置的;另一个原因可能是overfitting,在没有加入weight decay的代码之前,得到的准确率只有94%,weight decay减轻了部分overfitting的现象,准确率提高了两个百分点。
以上是个人实现CNN的笔记,欢迎大神指正。
参考资料:
【1】http://neuralnetworksanddeeplearning.com/
【2】https://github.com/yaolubrain/cnn_linear_max
【3】https://github.com/jakezhaojb/toy-cnn/tree/master/matlab