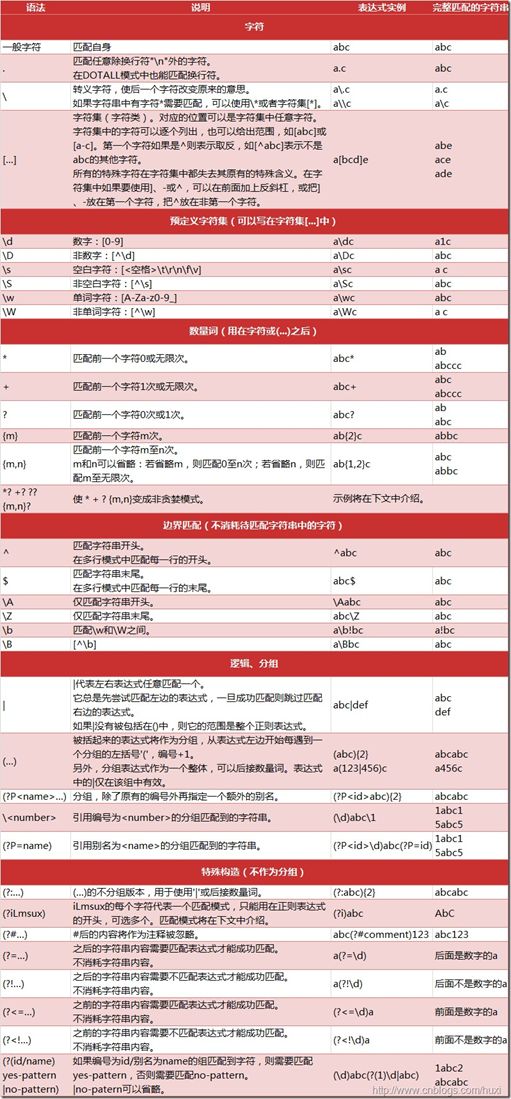
Python爬虫心得
一、前言
学习了爬虫之后,突然对crawler这个词产生了浓厚的兴趣,爬虫,很形象,很生动,在python中,爬虫的使用更加的快捷和方便,在这里将自己的一些心得予以记忆,加深印象!!!!!!
二、python爬虫
要点一:
python版本的选取,这里选取的是3.*,我们知道每一个版本很多的库和函数都做了相应的调整,如果不好好的掌握这一点,我们可能拿到别人的程序也无法使用。比如print函数,在3.*中是print(),具体的改动可以参考网址http://www.jb51.net/article/57956.htm来进行相关的学习。
要点二:
选择一个好的编译器,这点非常重要,这里选择的是pycharm,功能强大,支持调试等各种手段。
要点三:
理解python3.*的一些库函数,比如抓取网页用的urllib.request,用于正则表达式的re等,以及时间库函数time,随机数库函数random。
要点四:python的主函数
1 If __name__=’__main__’: 2 3 /*函数体*/
要点五:编码转换。
1 import re 2 from urllib.request import urlopen 3 def catchAllInfoFromNet( myUrl): 4 html = urlopen(myUrl).read().decode('utf-8','ignore') 5 #print(html) 6 #nameList = re.compile(r'(.*?) ', re.DOTALL).findall(html) # 列表形式 7 #nameList = re.compile(r'href="(.*?)"', re.DOTALL).findall(html) # 列表形式 8 #nameList = re.compile(r'"name": "(.*?)"', re.DOTALL).findall(html) # 列表形式 9 nameList = re.compile(r'(.*?)
', re.DOTALL).findall(html) # 列表形式 10 for i in range(0, len(nameList)): 11 print("第%d个名字为: %s"%(i,nameList[i]))
上面是一段源码,我们看到需要将字节转换成字符,这点非常重要。
要点六:对于如何下载网页。
这里有两种方法,一种如上面的代码所示,使用from urllib.request import urlopen来直接使用urlopen来抓取。
第二种是使用urllib.request来获得,代码如下:
1 import urllib.request 2 import re 3 def catchAllInfoFromNet(url): 4 #模拟浏览器,打开url 5 headers = ('User-Agent','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11') 6 opener = urllib.request.build_opener() 7 opener.addheaders = [headers] 8 data = opener.open(url).read().decode('utf-8','ignore') 9 nameList = re.compile(r'(.*?)
', re.DOTALL).findall(data) # 列表形式 10 for i in range(0, len(nameList)): 11 print("第%d个名字为: %s" % (i, nameList[i]))
这种方式我们要伪装成浏览器进行网页抓取。
当然也可以:
1 import urllib.request 2 import re 3 def catchAllInfoFromNet(url): 4 data = urllib.request.urlopen(url).read().decode('UTF-8') 5 nameList = re.compile(r'(.*?)
', re.DOTALL).findall(data) 6 for i in range(0, len(nameList)): 7 print("第%d个名字为: %s" % (i, nameList[i]))
要点六:正则表达式
可以参考http://blog.csdn.net/peace1213/article/details/48950593进行学习。
三、Python实现登录爬虫代码
最近,对python的研究几乎是到了上瘾的地步,一个工具如果好到了一定的程度,就算没有人去宣传它,推广它,这个工具也会成为大家心里最喜爱的工具的,用了python之后才感觉到以前的C/C++,C#和Java实在是不够简练,可能是术业有专攻吧,可是python的哲学色彩真的很浓厚,有很多值得我们去学习和借鉴的地方,正如工具的本质就是继承大量固有的操作,只留一些接口,从而来方便大家的操作和使用,在这一点上,我深有同感,特别是对于网络爬虫来说,python可以说真的封装到了一种瓶颈了,用其他语言需要几百行实现的代码,python只需要我们做几十行的工作,这一点就深深值得我们去思考和借鉴。下面就写一下这几天我是用python爬虫的体会。正如以前所言,爬虫的几个要点都已经说过了,可是正当我高兴的那前人的代码去爬取网页数据的时候,一个问题才出现了,需要登录,现在很多网站都有这个功能,不登录就不能使用爬虫来抓取自己需要的数据了,这不得不说是魔高一尺,道高一丈。这对于网站来说当然是一种进步了,可是对于我们爬虫族来说实在是一个既刺激又烦恼的消息,刺激在于我们就是要和这些网站斗智斗勇,烦恼在于面对与一次次的失败我们是否能平淡视之,不断地积累经验教训,不断地完善自己,这一点至关重要。下面就开始我的心得体会了。
难点一:登录需要的参数都有些什么?
首先一定要有的就是账号和密码了,除此之外或许还有验证码,说到了验证码,我们就有犯难了,可能是网站看到我们很容易的破解了他们的登录阻挡策略,而又想出的新一代安全手段吧。因为验证码多种多样,用代码识别也是可以的,不过要付出很多的代价,而我们自己看的话,也可以,这样对我我们初学者不失为一种好的方法。
难点二:如果只是简单的账号密码性的网站,我们怎么模拟账号和密码?
这一点我们不得不学习一下浏览器是怎么实现这样的功能的,其实很简单,一切都在应用层协议里,比如HTTP,HTTPS协议,在这些协议里封装了一些特殊的字段,用来识别用户的一些信息,比如所用的浏览器,发送的账号密码等等,于是我们就可以根据这些信息来进行伪造从而迷惑服务器了,这点我们再上一次已经讲过,我们的程序也就是这样做的,那在这里,这些账号密码肯定也是放在这些字段中的,我们要做的是将这些数据提交到那些包里面,因此,在这里我们就需要用到cookie了,cookie英文意思是小点心,它确实是我们的“小点心”呀,它的里面存储的东西是非常重要的,如果我们在浏览器上保存了账号,密码等信息,那么就会被存到浏览器对应的cookie里,放在本地主机,比如说firefox浏览器的cookie就在选项——》隐私——》自定义设置——》显示cookie里,如下图所示,不同的浏览器可能有所不同,cookie存储的内容也很简单易懂,就是一个映射,Map(key,value),一个键值对的映射,比如我们的账户,Account:Account Value,这就是一种映射,因此,我们要搞定用户名和密码,就要知道在实际传输中,当前网站所有的这些信息,一般情况下账号名是不加密的,而密码一定是加密传输的,不过这并不影响我们去识别它,那么问题来了,我们怎么去识别账户名和密码的字段呢?至于真正的账户名和密码,我们可以自己注册一个,这都无关紧要,可是我们怎么知道我们的键(key)呢?!

这些往往在python登录的教程里没讲,而我们确实真正要用到的,因此这里我一定着重讲一下,不然这对初学者来说是极其痛苦的,很难理清思路,很困惑,楼主都被困了整整一个上午才找到解决方案,不过也学到了一些知识,在这里给大家分享:
首先,让我们思考,我们可不可以在浏览器中,用F12来调用网页自带的开发工具来查找呢?!在网上也有这样的例子,比如:在firefox中有一个插件叫做firebug,我们可以安装它之后来捕捉:
下面我们都用人人网为例来进行实验,无它,没有验证码也!!!
首先我们安装firebug,重启浏览器,之后我们在人人网上按F12进入开发者模式,如下图所示:

我们点击cookie可以看到如下的字段,这里放大:

很自然地惊讶这些东西都是什么,是cookie呀,我们还能看到这些是来自那个网页的cookie,不过我们怎么从这些字段中知道那些是我们要找的账号和密码呢?很难,并且我可以告诉大家的是这些都不是,网上的很多文章真的是够混帐的,弄出来浪费我们的时间?!其实可能有其他的用吧,可是却是对于我们的工作帮助不大。比如说下面的一个cookie显示的内容是我的账号,我当时还高兴了很久,觉得总算找到了一个字段了,可是仔细看看,In_uact这个是什么鬼?!我们也不得而知,只能说你是不是在逗我,当然了这些背后肯定有具体的含义,可在这里与我们无关呐。

当然我们辛辛苦苦下载的firebug也不是一无是处嘛,只是我们可以看到一些浏览器的参数,包的header,等信息。在调试器的“网络”中,我们可以看到。这些信息或许对我们以后的学习有用,反正先记着吧。这些就是网上能够看到的内容了,下面我介绍一下,我的方法,当时我也认为没办法了,这些东西一点都不直观明了,并且感觉总有些不对的感觉,幸好我在网上看到了抓包分析的方法,恰好,我也在想可不可以用抓包的方法来检测呢?!沿着这个思路,我又开始了进一步的探索!!!

网络抓包有很多种方法,比如wireshark、fiddler等,这里我用惯了前者,就用用后者吧,后来发现网上对它的评论还不错,尤其是对https协议来说,fiddler确实是一个比较不错的选择,比较小,短小精悍。Fiddle的本意是“小提琴”或者“胡扯,无聊,欺诈,欺骗”,不能理解为什么小提琴会和欺诈扯上关系,我想fiddler肯定是借鉴了欺诈的意义,因为抓包本来就是一种窃取信息的行为,甚至还可以伪造成新的包,因此名字起的还是很形象。下载并安装fiddler,之后如图所示:
然后,我们首先打开fiddler,注意一定要先打开,然后切换浏览器到人人网页面,用自己的账号密码登录网站,此时fiddler就开始抓取我们和服务器进行交互的信息了,如下图所示:

点击登录,就进入下面界面:

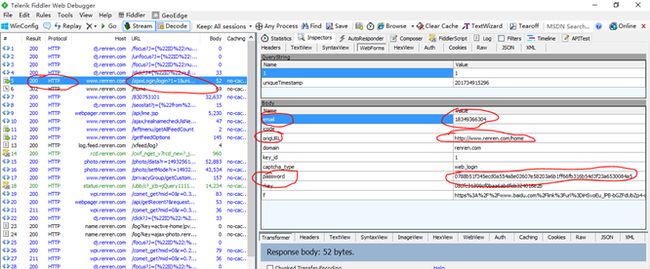
此时可以看到fiddler中的信息:

其中result为200的说明是抓取成功的,我们一个个的点击查看,观看右边Inspect上面的webforms来观看,直到点击到第五个url为“/ajaxLogin/。。。”的这一个包的时候,我们发现右边的结果如下图所示:(账号名是email,没加密,密码是加密的,为password)

终于我们找到了这个东西,我们需要的cookie,那大家有可能会说有可能是浏览器迷惑我们,故意写的这些字段呢,其实是把别的伪装成了这样呢,确实有可能,比如淘宝就有两个密码TPL_password和TPL_password_2,经过我的观察,后者才是真正的密码,前者为空,当然具体问题具体分析,我们一个一个试探,总能出结果的,这就是黑客的基本素质了,不气馁,一直积累经验,不断尝试。同理,我们还可以在这个包中读出cookie,看来,我们刚开始认为的字段的名称在cookie里根本就没有呀,这一点到底是为什么,我相信在以后的学习中会渐渐理解的。

找到了重要的两个信息,我们是不是很兴奋,因为,我们可以在python程序中模拟网页登录,并且爬取网页了!!!!!!
先看程序:
1 import http.cookiejar 2 import urllib.request 3 import urllib 4 #利用cookie模拟网站登录 5 filenameOfCookie ='renren_cookie.txt' 6 cookie=http.cookiejar.MozillaCookieJar(filenameOfCookie) 7 headler=urllib.request.HTTPCookieProcessor(cookie) 8 opener=urllib.request.build_opener(headler) 9 data={"email":"18349366304","password":"XXXXXXXXXX"} 10 postdata=urllib.parse.urlencode(data).encode(encoding='UTF8') 11 loginurl='http://www.renren.com/PLogin.do' 12 request=opener.open(loginurl,postdata) 13 print (request) 14 cookie.save(ignore_discard=True, ignore_expires=True) 15 geturl='http://friend.renren.com/managefriends' 16 result=opener.open(geturl).read().decode('utf-8') 17 print (result) 18 filenameOfHtml ='renren.html' 19 fileToWrite=open(filenameOfHtml,'w') 20 fileToWrite.write(result) 21 fileToWrite.close()
看到了吗,我们首先使用了MozillaCookieJar等工具来创建了cookie之后创建了opener来承载我们的处理引擎,之后就是重点了,我们伪造cookie的post数据,也就是data={"email":"18349366304","password":"XXXXXXXXXX"},因此我们就可以模拟输入账户密码登录了,前面的工作就是为了这一步,经过一些编码处理之后,我们通过request=opener.open(loginurl,postdata)来真正的将这些信息应用到具体的数据包中,模拟浏览器进行登录,最后我们将获得的cookie信息保存起来,写入文本文件中。并且为了测试,我们访问了一个不登录就不能访问的网页,抓取了这个网页的信息打印并写入本地,程序结束。运行结果如图:

不信的话,我们进入人人网的这个链接http://friend.renren.com/managefriends来看一下:可以看到结果完全一样!!!
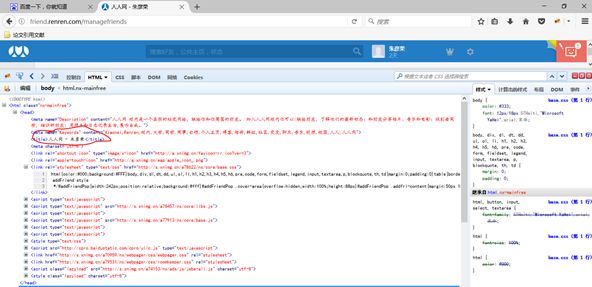
顺便可以看一下,我们退出了就进不去这个网页了,点击回车显示需要登录:

难点三:如何攻破https格式的网页登录。
这里我用淘宝网进行测试。得到的效果是时好时坏,正在不断地优化,淘宝网也是没有验证码的。不过对于这种失败,我觉得是应该的,要是这么容易就让我蒙混过关了,我都有点不敢用了呢,呐呐~~~这里首先是https协议,我们的fiddler如果不经过配置都不能识别,更不说去解析了,于是我们首先要让fiddler拿到操纵https包的优先权,于是我们需要提升权限,只能用证书的方式了,让fiddler自动生成根证书然后安装到浏览器中,这样我们就可以抓取信息了。过程如下:

在工具中找到该窗口,选中那两个对号,然后点击actions,选择“truest root certificate”选择yes,
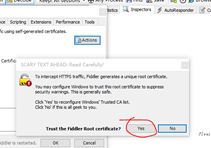


之后一直确认,然后点击actions的导出到桌面:我们可以在桌面上看到相应的根证书了。

然后我们将证书导入到浏览器:在火狐中我们选择证书,如图所示:


在查看证书的导入中,将证书导入浏览器,之后就可以抓取https的包了,让我们抓取淘宝网。
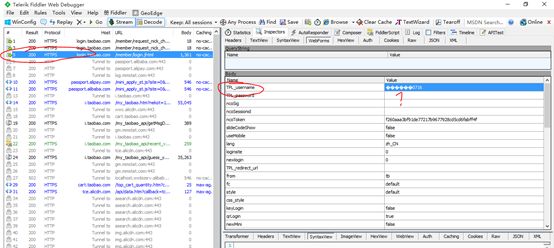
好了,我们找到了用户名的post,那么密码为什么是空的呢,我们继续往下查找,总算找到了TPL_passwprd_2这个东西,这就是我们的密码了,这也是一种安全策略吧。

让我们用程序测试一下:
1 import urllib.request 2 import urllib 3 import http.cookiejar 4 filename = 'taobao_cookie.txt' 5 cookie = http.cookiejar.MozillaCookieJar(filename) 6 headler = urllib.request.HTTPCookieProcessor(cookie) 7 opener = urllib.request.build_opener(headler) 8 data = {"TPL_username": "朱彦荣0716", "TPL_password_2": "XXXXXXXXXX"} # 你的用户名密码 9 postdata = urllib.parse.urlencode(data).encode(encoding='UTF8') 10 loginurl = 'https://login.taobao.com/member/login.jhtml?' 11 request = opener.open(loginurl, postdata) 12 print('登录成功!!!') 13 cookie.save(ignore_discard=True, ignore_expires=True) 14 geturl='https://i.taobao.com/my_taobao.htm?' 15 geturl='http://mm.taobao.com/687471686.htm' 16 result=opener.open(geturl) 17 print (result.read().decode('gbk','ignore'))
结果没成功,这波土我吃的服!
不过这不代表没办法进去了,我们还可以用PlantomJS+Selenium来真正的模拟一个人的登录过程来测试,这里需要慢慢学习,可以说这只是第一步罢了,就算进去了也破坏不了系统的什么东西的。
难点四、如何保存cookie,在以后的登录中读取cookie即可?
代码如下:
1 import http.cookiejar 2 3 import urllib.request 4 5 import urllib 6 7 #创建MozillaCookieJar实例对象 8 9 cookie = http.cookiejar.MozillaCookieJar() 10 11 #从文件中读取cookie内容到变量 12 13 cookie.load('renren_cookie.txt', ignore_discard=True, ignore_expires=True) 14 15 #创建请求的request 16 17 req = urllib.request.Request("http://friend.renren.com/managefriends") 18 19 #利用urllib2的build_opener方法创建一个opener 20 21 opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie)) 22 23 response = opener.open(req) 24 25 print (response.read().decode('utf-8','ignore'))
关于爬虫的心得就先到这里为止!!!!!!