A Model of Saliency-Based Visual Attention for Rapid Scene Analysis

- 题目:A Model of Saliency-Based Visual Attention for Rapid Scene Analysis
- 作者:Laurent Itti, Christof Koch, and Ernst Niebur
- 领域:视觉显著性
- 类型:新问题,新方法
核心思想
从人类视觉心理学的角度入手来研究该问题,采用方法包含了两部分,一是提取显著图(Saliency Map, SM),二是动态更新关注点(Focus of Attention, FOA)。

受生物学启发,该方法模仿人类自下而上的视觉选择性注意过程,提取图像的底层特征,构造相应的显著图。
显著图的构造基于“特征集成理论”(feature integration theory),每一种特征都会有自己的显著图,在某个特征下,不同位置的像素之间互相竞争,最终会有一些像素脱颖而出,成为该特征中的显著点。
处理流程

提取显著图(Saliency Map, SM)
- 显著图的构造基于“特征集成理论”(feature integration theory),每一种特征都会有自己的显著图,在某个特征下,不同位置的像素之间互相竞争,最终会有一些像素脱颖而出,成为该特征中的显著点。
- 作者根据“中心-周围”拮抗理论,算出每一个像素点(作为中心点)相对于周围的像素点的显著值,所有点的显著值就构成了一副显著图。而不同特征下的显著图经过某种方式,汇集成最终的场景显著图。
作者在这里采用了三种特征:亮度,颜色(根据“颜色双对立”系统[color double-opponent]),角度(使用Gabor滤波器),为了生成这些特征的显著图(Conspicuity Maps),作者先对原图像进行尺度变换,生成九层高斯金字塔.
这一方面增强了该方法的尺度不变性,另一方面也模拟了层级感受野的机制。
我们可以把金字塔中的低层级图像的像素点看成“中心”,把高层级图像的对应像素点看成“周围”。然后把高层级图像通过插值的方式变成和低层级图像相同的大小,最后,把两个图像对应像素点的某种特征的值,进行逐点相减,产生一个尺度下某种特征的显著图。
中央周边差操作,是根据人眼生理结构设计的。人眼感受野对于视觉信息输入中反差大的特征反应强烈,例如中央亮周边暗的情况、中央是绿色周边是红色的情况等,这都属于反差较大的视觉信息。
在高斯金字塔中,尺度较大的图像细节信息较多,而尺度较小的图像由于高斯平滑和减抽样操作使得其更能反映出局部的图像背景信息,因而将尺度较大的图像和尺度较小的图像进行跨尺度减操作(across-scale),能得到局部中心和周边背景信息的反差信息。
最后还要把得到的不同特征的不同尺度的显著图进行合并,得到最终的显著图.
首先是合并同一特征不同尺度的显著图.
- 作者把它们都放缩到金字塔的第四层级(最开始选择的时候,中心点只取2,3,4这三级,所以得到的显著图只有这三级的,因此在这里就是把这些级通过降采样到第四级)
- 然后把每张显著图的每一个像素点的显著值进行归一化
作者归一化的方式比较特别,原则就是去除不同特征因为幅值不同而带来的不均衡性,以及尽可能地让最显著的点突出出来(加大“贫富差距”)
- 最后,把所有图对应点的显著值相加,得到最终该特征的显著图。要注意的是,对于角度特征,作者采用了四个角度,因此实际上可以看成是四个特征,所以在对角度特征进行显著图合并时
- 作者是先对各个角度做一次显著图合并
- 然后把合并好的四个图直接叠加起来得到角度特征的显著图
接下来是合并不同特征的显著图.
- 作者先把三个特征的显著图都做再一次上述的归一化
- 然后进对三者求平均,便得到最终的显著图
有趣的是,作者把得到的结果记为,而不是SM (Saliency Map),这是因为重头戏在接下来的部分.
亮度特征通道

颜色特征通道
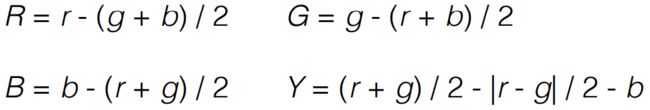
其中表示黄色的Y: negative values are set to zero.
方向特征通道
通过利用方向Gabor金字塔从I中获得(I即为第一个特征图Intensity), 其中σ∈[0..8]表示参数范围, 表示涉及到的方向.
Gabor滤波器是余弦栅格和二维高斯包络的产物, 这个可部分约等于在灵长动物的定位选择神经系统中, 视觉皮层接收信息的敏感度(脉冲响应) Gabor filters, which are the product of a cosine grating and a 2D Gaussian envelope, approximate the receptive field sensitivity profile (impulse response) of orientation-selective neurons in primary visual cortex [A.G. Leventhal, The Neural Basis of Visual Function: Vision and Visual Dysfunction, vol. 4. Boca Raton, Fla.: CRC Press, 1991.].
center-surround differences
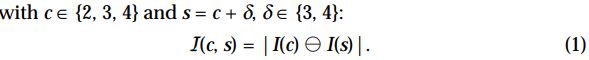
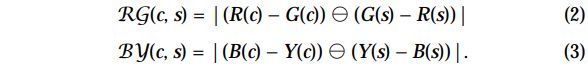
![]()
注意
- 公式中的运算符. 表示先对b进行插值扩张, 调整大小到a的尺寸, 再进行像素级差值计算.
- 这里得到的几个特征图大小只有三种尺度, 即2, 3, 4.
a new map normalization operator
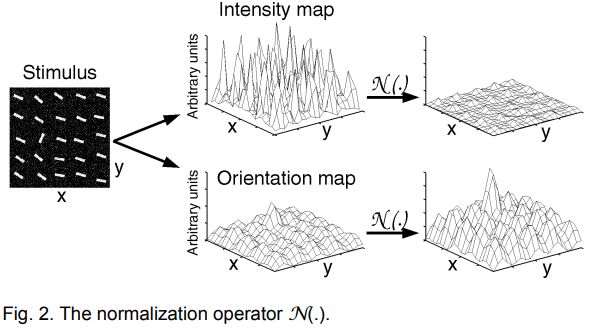
- normalizing the values in the map to a fixed range , in order to eliminate modality-dependent amplitude differences;
- finding the location of the map's global maximum and computing the average of all its other local maxima;
- globally multiplying the map by .
如果一个特征图只有部分值非常突出的话,那么就会很大,特征图整体乘以就会增强整个特征图,如果普遍值都较高的话就会很小,因此乘以平方后会抑制整个特征图。
组合不同的特征图的难点之一在于不同的特征图表示了不可比较的模态的先验信息,有不同的动态范围和提取机制。42个特征图结合时,在一些特征图中表现非常强的显著目标可能被其它更多的特征图的噪声或不显著的目标所掩盖。
在缺少top-down监督的情况下,作者提出了一个归一化操作算子,整体提升那些有部分强刺激峰值(醒目位置)的特征图,而整体抑制那些包含大量可比峰值响应。
图解见上图,对于亮度特征图,普遍的值都较高,因此进行整体抑制,而对于方向特征图,只在某一小部分区域有着较大的值,因此进行整体提升。
conspicuity maps

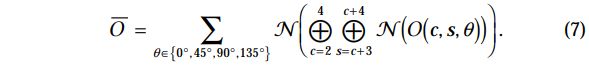
The three conspicuity maps are normalized and summed into the final input to the saliency map:

注意
- 公式中的中的运算符表示进行像素级加和. 而且这里注意, 只操作了c+3, 没有考虑+4的情况.
- 这里的公式中, 在进行归一化计算之前, 所有的得到的特征图先放缩到等级4的尺度上(原本只2, 3, 4).
- 从上式我们可以看出一个很重要的思想:作者假设了相似的特征之间对于显著性竞争很强,而不相似的特征对于显著性图的贡献没有竞争,是互相独立无关的。
动态更新关注点(Focus of Attention, FOA)
一般而言,我们得到上一步的显著图就完事了,而作者又增加了一个动态更新关注点的过程,目的就是为了模拟人类视觉注意力转移的过程,从而生成更具表现力的显著图。
此处,作者把真显著图(SM)类比成一个动态更新的神经层,它的初始输入是上一步得到的尺度等级静态显著图(S), 并且都是独立的.
在任何给定的时间,显著性图(SM)的最大值定义了最显著的图像位置 ,而关注焦点(FOA)应该指向该位置.
然后作者又定义了一个激活神经网络:“胜者为王”网络(winner-take-all), 其中单元之间的突触相互作用确保仅保留最活跃的位置,而所有其他位置被压制.
S、SM、WTA网络三者的大小是一致的,并且每一个点都是一一对应的。
初始时,SM的值由S决定(通过类似神经信号传导的方式),而之后它又会在WTA网络的影响下进行更新。
- S中最显著的点会给SM中对应的点最大的初始激励值
- SM中每一个点又会刺激WTA网络中对应的点
- 当WTA网络中的某个点首先达到激活阈值时,一个真注视点(FOA)就产生了
SM中的神经元的电位在更为显著的区域会增长得更快,这些神经元不会fire.
fire的意思是当神经元的电位超过一个阈值的时候,电位就会立刻降到一个固定的较低的值去,然后重新开始增长电位, 不会fire也就是说这里的神经元仅仅充当一个积分电路的角色,用来累积电位,但电位永远不会超过设定的阈值
这个机制很好地模拟了当有多个显著点时,人类是怎样产生注意的:第一个引起注意的就是注视点.
至于哪个会是第一个,就仁者见仁智者见智了,毕竟WTA网络的激活方式并没有指定,比如可以所有的点同步变更,也可以先变更中心区域的点
当WTA网络出现了一个胜者时,将会同时执行以下三个过程:
SM中的每一个神经元都会刺激与它相连的WTA神经元,所有的WTA神经元都各自发展,互相独立,直到有一个WTA神经元率先达到了电位阈值,然后fire了。
- 将FOA转移到胜者对应的点上,即更新注视点
- 重置WTA网络(清零),为下一次注视点变更做准备
- 在SM中对注视点周围的区域做一定时间的局部抑制,确保能够发生注视点转移,并且确保注视点不会立刻返回来
这样做的好处是在下一次的电位累积中,显著性稍微比最强的差一点的区域可以成为新的winner,从而可以使得FOA(focus of attention)动态变化,因为我们关注的东西可能不只一处,同时还防止下一次的FOA又是上一次检测到的显著性区域。
这种机制被称为“inhibition of return”,它已经在一些研究中被证明是确实存在的.
说得通俗一点,就是本次称为FOA的区域在下一次直接在相应的SM图中的值变为0,让其他区域有机会称为新的FOA。
最后值得说明的一点是,在每一次胜者为王的竞争中,最后胜出的是一个像素,那么如何根据这个像素来定义FOA区域呢? 本文采用的方法是以这个像素为中心,半径是SM图长宽中较小的那个边长的1/6,形成一个圆形区域作为FOA区域。而关于leaky integrate-and-fire neuron模型中阈值的选择在本文引用的论文中有介绍,这里就不做具体介绍了。
为了模拟“近邻优先”(proximity preference)的原则,作者还在SM上对注视点周围(除了抑制区域外)的点加了一个短时间的激励。
当然作者对它的模型进行调参了,以便使注视点转移的过程更接近人类视觉系统的行为。
结论
- The authors showed that this model is superior to previous spatial frequency content (SFC) based models in the presence of noise
- Resulting FOA trajectories were not directly compared against human visual trajectories, but agreed with other models when identifying regions of high saliency
眼见为实!让程序跑出来的结果和我们人类的判断作比较就好。作者将他人做过的根据眼动观测仪的结果(Spatial Frequency Content),与自己用程序跑出来的结果进行对比,可以看出来结果还是不错的。
当然这个模型也是有缺点的:
- 太依赖特征的选择了,没有考虑到的特征就不会产生出显著性,太过于human-design,比较适合专用系统。
- 此外,由于最终的显著图是在第四级高斯金字塔下呈现的,这就导致了分辨率的降低,也就损失了一些图像的信息。作者之所以这样做,是因为他不关心精确的分割问题,只是找出显著点,然后大致画一块区域。
补充内容
显著性
人在用眼睛看到一个场景的时候,会首先注意到场景中非常特别、吸引人的部分。
举个例子,有十个陌生人朝你走过来,从左到右第八个人穿的黑色衣服,其他九个人穿的白色衣服,除了衣服颜色不一样,其他一模一样。不带任何主观目的地看,你会首先注意到谁?一般来说我们会注意到穿黑色衣服的那个人,为什么呢?因为他和其他九个人衣服颜色不一样,即他在这十个人里面是显著的,人类会首先注意到显著的东西。
那我们说人首先会注意到显著的东西这句话有没有科学依据呢?论文中提到说经过前人的一些研究发现,中级和高级的视觉处理过程会首先选取当前场景的一个子集,然后再进一步进行处理,比如进行分类识别等,这样做的目的是减少场景分析的复杂度。那么这个子集会包括什么内容呢?主要包括的就是“focus of attention”, 后文称为FOA,即注意的焦点。
自下而上/自上而下
选取这些焦点是通过两种方式的结合,一种是自下而上(bottom-up)的、基于显著性驱动的与任务无关的方式,这种方式是快速的,另一种是自上而下(top-down)的,受到我们意志力控制的、与任务相关的方式,这种方式是相对较慢的。
在本文的“十个人”的例子,如果你不带任何目的的看这十个人,那你首先注意到的一般会是黑色衣服的那个人,这就是bottom-up的方式.
我对这里bottom-up的理解是bottom指的是场景,up指的是大脑,即场景中什么东西最特别,那我的大脑就先注意到什么东西。
bottom-up的前提是你不带任何目的的看,那假如说现在我接到了一个任务,告诉我说事实上这十个人里面,最左边的那个是一位特工,其他9个人都是他的替身,用来掩人耳目的而已,而我要做的事情是和真正的特工接头,比如说走到那个特工面前然后对念两句唐诗就完成了接头。那么当这十个人朝你走过来的时候,你会首先注意到哪个人?
可以类比你去机场或者车站接朋友的时候,在人群中我们一定会先注意到朋友在哪儿,而不会是其他人在哪儿。这就是top-down的方式,即我们大脑中已经有了一个目的或者说任务要找谁,然后当场景出现的时候自然就会基于这个任务去选择首先注意到谁。
leaky integrate-and-fire neuron
它是一种神经元的模型,关于这种神经元模型的细节可以参考 SPNM,里面有详细的介绍和数学推导。本文是将最后的SM建模成为一个在尺度为4的情况下的二维leaky integrate-and-fire neuron的模型。
论文里所说的电位以及fire等词汇都是来自leaky integrate-and-fire neuron模型中的。
讨论
- 在灵长类视觉系统中,显著性图可以作为计算机视觉中低级系统和高级系统之间的过滤器。
- 这里提出的模型相当复杂(在SIFT特征提取的顺序上)。
- 作为更先进的cv算法的先驱,可能是有用的。
参考链接
- 翻译:
- https://blog.csdn.net/weixin_40740160/article/details/84640669
- https://blog.csdn.net/chenjiazhou12/article/details/39456589
- 笔记:
- 简练: http://yugnaynehc.github.io/2016/04/23/a-model-of-saliency-based-visual-attention-for-rapid-scene-analysis/
- 细致: https://blog.csdn.net/xbcReal/article/details/53590039
- PPT: http://www.ee.unlv.edu/~b1morris/ecg782/sp14/docs/kauke_saliency_20140410.pdf
- 论文: http://ilab.usc.edu/publications/doc/Itti_etal98pami.pdf