优化基于FPGA的深度卷积神经网络的加速器设计
英文论文链接:http://cadlab.cs.ucla.edu/~cong/slides/fpga2015_chen.pdf
翻译:卜居
转载请注明出处:http://blog.csdn.net/kkk584520/article/details/47450159
【0. 摘要】
CNN已经广泛用于图像识别,因为它能模仿生物视觉神经的行为获得很高识别准确率。最近,基于深度学习算法的现代应用高速增长进一步改善了研究和实现。特别地,多种基于FPGA平台的深度CNN加速器被提出,具有高性能、可重配置、快速开发周期等优势。
尽管目前FPGA加速器已经展示了相比通用处理器更好的性能,加速器设计空间并没有很好发掘。一个严重的问题是,一个FPGA平台的计算吞吐并未很好匹配内存带宽。因此,已有的方案要么未充分利用逻辑资源,要么未充分利用内存带宽,都不能获得最佳性能。同时,深度学习应用不断增加的复杂度和可扩展性让这个问题更加严重。
为了克服这个问题,我们利用roofline模型提出一种设计分析方法。对于任意CNN设计方案,我们量化分析它使用不同优化技术(循环分块、变换)的计算吞吐和所需内存带宽。在roofline模型帮助下,我们可以发现最好性能和最低FPGA资源需求的解决方案。
作为案例研究,我们在VC707 FPGA板卡上实现了一个CNN加速器,并将它与之前的方案对比。我们的实现在100MHz工作频率下可获得61.62GFLOPS的峰值处理能力,大大优于之前的方案。
【1. 简介】
CNN是著名的深度学习架构,从人工神经网络扩展而来,它已经大量用于不同应用,包括视频监控,移动机器人视觉,数据中心的图像搜索引擎等【6】【7】【8】【10】【14】
受生物视觉神经行为的启发,CNN用多层神经元相连处理数据,在图像识别中可获得很高准确率。最近,基于深度学习算法的现代应用快速增长进一步改善了DCNN的研究。
由于CNN的特殊计算模式,通用处理器实现CNN并不高效,所以很难满足性能需求。于是,最近基于FPGA,GPU甚至ASIC的不同加速器被相继提出【3】【4】【9】以提升CNN设计性能。在这些方案中,基于FPGA的加速器由于其更好的性能,高能效,快速开发周期以及可重配置能力吸引了越来越多研究者的注意【1】【2】【3】【6】【12】【14】。
对于任意CNN算法实现,存在很多潜在解决方案,导致巨大的设计空间。在我们的实验中,我们发现使用同样FPGA逻辑资源的不同方案性能有最大90%差距。寻找最优解不无价值,尤其当考虑FPGA平台计算资源和内存带宽限制时。实际上,如果一个加速器结构并未仔细设计,它的计算吞吐与内存带宽不匹配。未充分利用逻辑资源或内存带宽都意味着性能下降。
不幸的是,FPGA技术进步和深度学习算法同时将该问题复杂化了。一方面,当前FPGA平台不断提升的逻辑资源和内存带宽扩大了设计空间,采取不同FPGA优化技术(如循环分块、变换)会进一步扩大设计空间。另一方面,为了满足现代应用需求,深度学习可扩展性和复杂性在持续增长。因此,在巨大的设计空间中寻找最优解就更加困难,亟需一种高效检索基于FPGA的CNN设计空间的方法。
为了高效检索设计空间,本文提出了分析设计的方法。我们的工作优于以前的方法,原因有二:
首先,【1,2,3,6,14】主要关注计算引擎优化,要么忽视了外部存储器操作,要么直接将他们的加速器接入外部存储器。我们的工作则考虑了缓冲区管理和带宽优化。
其次,【12】通过数据重用减少了外部数据获取从而获得加速。但是这种方法不必导致最优全局性能。另外他们的方法需要对每层重新配置,不太方便。我们的加速器无需重编程FPGA就能执行不同层的计算。
本文主要贡献如下:
* 量化分析可能解决方案的计算吞吐和所需内存带宽;
* 在计算资源和内存带宽限制下,我们用roofline模型识别所有可能的解决方案,讨论了不同层如何寻找最优解;
* 我们提出一种CNN加速器设计,对每层使用统一的循环展开因子;
* 实现了CNN加速器,获得61.62GFLOPS处理性能,是目前最优的;
【2. 背景】
2.1 CNN基础
CNN受神经科学研究的启发,经过长达20多年的演变,CNN在计算机视觉、AI(【11】【9】)领域越来越突出。作为一种经典有监督学习算法,CNN使用前馈处理用于识别,反馈用于训练。在工业实践中,很多应用设计者离线训练CNN,然后用训练好的CNN实现实时任务。因此,前馈计算速度是比较重要的。本文关注用基于FPGA的加速器设计前馈计算加速。
一个典型CNN由两部分组成:特征提取器 + 分类器。
特征提取器用于过滤输入图像,产生表示图像不同特征的特征图。这些特征可能包括拐角,线,圆弧等,对位置和形变不敏感。特征提取器的输出是包含这些特征的低维向量。
该向量送入分类器(通常基于传统的人工神经网络)分类器的目的是决定输入属于某个类别的可能性。
一个典型CNN包括多个计算层,例如,特征提取器可能包括几个卷积层和可选的下采样层。图1展示了卷积层的计算。
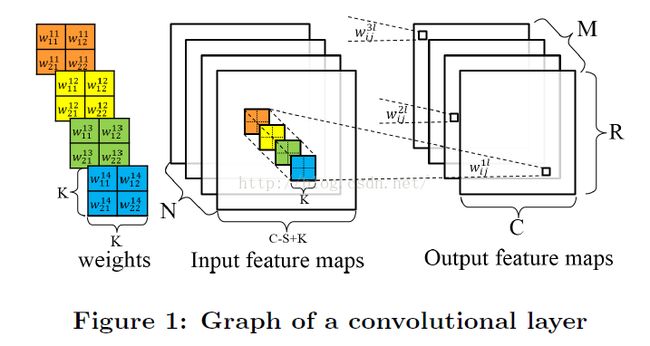
卷积层收到N个特征图作为输入,每个输入特征图被一个K * K的核卷积,产生一个输出特征图的一个像素。滑动窗的间隔为S,一般小于K。总共产生M个输出特征图用于下一卷积层。卷积层的伪代码如下:
for(row = 0; row < R; row ++)
{
for(col = 0; col < C; col ++)
{
for(to = 0; to < M; to ++)
{
for(ti = 0; ti < N; ti ++)
{
for(i = 0; i < K; i++)
{
for(j = 0; j < K; j++)
{
output_fm[to][row][col] += weights[to][ti][i][j] * input_fm[ti][S * row + i][S * col + j];
}
}
}
}
}
}在前馈计算角度,之前的论文【5】证明卷及操作会占据超过90%的总计算时间,所以本文我们关注加速卷积层。后面会考虑集成其他可选层,如下采样层、最大池化层。
一个真实的CNN
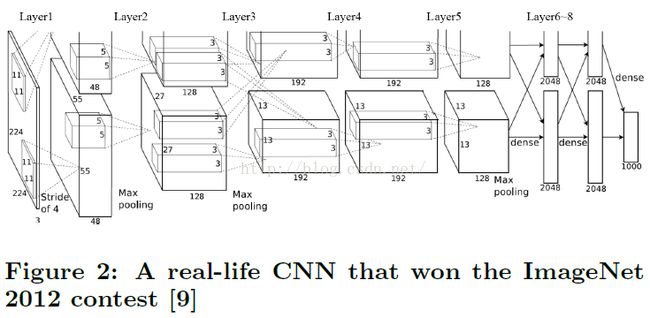
图2展示了一个真实CNN应用,摘自【9】。该CNN包括8层,前5层为卷积层,第6~8层为全连接人工神经网络。该算法接收3通道224x224输入图像(从原始256x256三通道RGB图像变换而来),输出1000维向量表示1000个类别的可能性。
第一层输入为3个224x224分辨率的特征图,输出96个55x55分辨率的特征图,输出分为两个集,每个48组特征图。表1记录了该CNN的配置。
2.2 Roofline模型
计算和通信是系统吞吐优化的两个基本限制。一个实现可能是计算受限的或访存受限的。【15】开发了roofline性能模型来将系统性能同片外存储带宽、峰值计算性能相关联。
公式(1)表示了特定硬件平台的可达吞吐率,用GFLOPS作为评估指标。
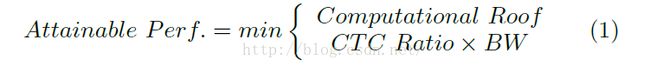
一个应用实际GFLOPS不会高于这两项中的最小值:第一项为所有可用计算资源提供的峰值计算能力(计算上限),第二项为给定计算-通信比时系统访存带宽可支持的最大浮点性能(IO带宽上限)。计算-通信比,又称每DRAM传输运算量,表示特定系统实现所需的DRAM访问量。
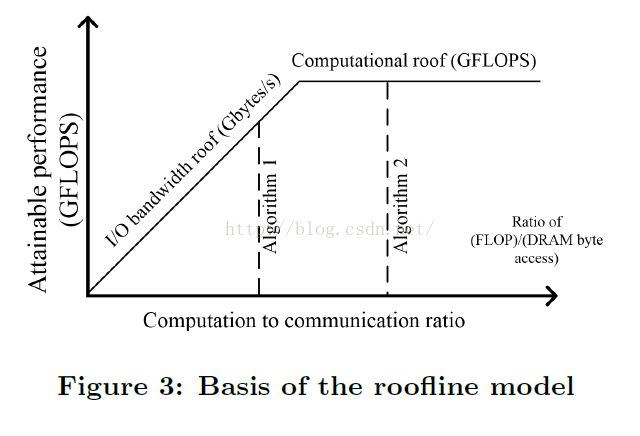
图3将roofline模型可视化,分别展示了计算上限和IO带宽上限。算法2相比算法1有更高计算-通信比,或更好的数据重用.从图中看到算法2充分利用所有硬件计算资源,性能优于算法1。
【3. 加速器设计探索】
本节首先提供了我们的加速器结构概览,介绍了FPGA平台上的几个设计挑战。为了克服这些挑战,我们提出了相应的优化技术。
3.1 设计概览
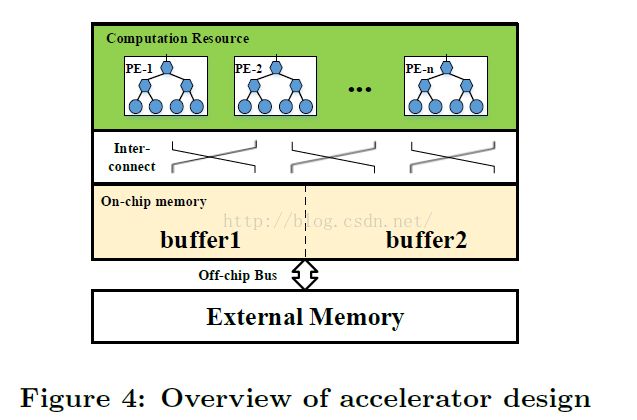
如图4所示,一个CNN加速器设计包括:处理单元(PE),片上缓存,外部存储器以及片内外互联。PE是卷积的基本计算单元。用于处理的所有数据放在外部存储器。由于片上资源限制,数据首先缓存到片上buffer,之后送入PE。这里使用双缓冲将传输时间掩盖于计算时间。片上互联用于PE和片上缓冲的通信。
在FPGA平台上有这样几个设计挑战阻碍了高效的CNN加速器设计:首先,片上数据只有很小一部分,故循环分块(loop tiling)是必要的,不合适的循环分块可能降低数据重用和数据并行处理效率。
其次,PE和缓冲区组织及其互联应仔细考虑,这样能高效处理片上数据。第三,PE的数据处理吞吐应该匹配FPGA平台的片外访存带宽。
本节我们从Code1开始优化,提供了连续步骤获得最优处理效率。
使用了循环分块的代码如下:

注意到循环变量i和j并未分块,因为CNN中卷积层kernel尺寸K太小(3~11)。
第二,我们讨论了计算引擎优化并将计算性能与分块系数建立联系。
第三,我们使用数据重用技术减少外存访问,建立了计算-访存比和分块系数的联系;
第四,利用上述两个变量,我们定义了设计空间,在FPGA平台上找最优解;
第五,我们讨论了怎样为多层CNN应用选择最好的加速器。
3.2 计算优化
本节使用标准基于多面体的数据相关性分析【13】来通过循环调度和循环分块尺寸穷举法衍生出一系列等效CNN设计实现。
计算优化目标是使用有效的循环展开、流水线,将计算资源完全利用。本节假设所有需要的数据都在片上。片外存储带宽限制将在3.3节讨论。
循环展开:用于增加海量计算资源利用率。在不同循环层次展开会产生不同实现。展开的执行单元是否共享数据以及共享到什么程度会影响生成硬件的复杂性,最终影响展开的复制品数量和硬件运行频率。某个循环维度中对一个数组的共享关系可以分为三种类型:
* 无关,如果循环变量i不出现在数组A的任何访问函数,则称相应循环维度对数组A是无关的;
* 独立,如果数组A沿着某个循环维度i是完全可分的,称i对数组A独立;
* 相关,如果数组A沿某个循环维度i不可分,称i对数组A依赖;
图6显示了不同数据共享关系时产生的硬件实现。
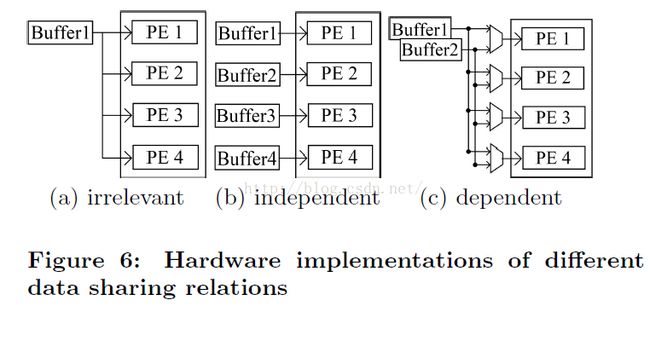
独立数据共享关系:buffer和计算引擎直接连接;
无关:生成广播式连接;
相关:产生带多路开关的互联;
对图5中代码分析相关性,结论如下表:
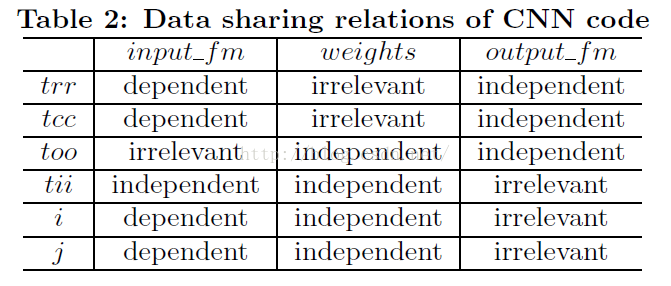
最终,选择too和tii两个循环维度做循环展开,从而避免生成复杂硬件拓扑。我们需要将循环嵌套次序做修改,让too和tii到最内层循环,简化HLS代码生成。生成的硬件实现如图7所示。
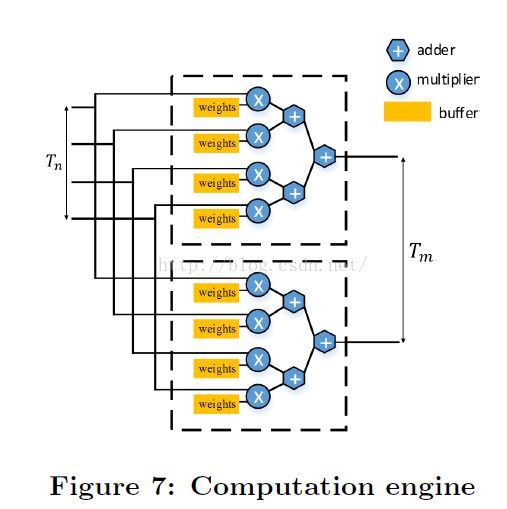
循环流水线: 是HLS里一项重要优化技术,通过将不同循环层次操作执行交叠,可提高系统吞吐。可获得的吞吐受资源和数据相关性限制。loop-carried相关性会导致循环不能完全流水线。
经过循环展开和流水线优化的代码如图所示。

分块尺寸选择:将循环结构固定后,不同循环分块尺寸变化会有巨大性能变化。代码3中有效的循环分块尺寸由公式(2)确定:
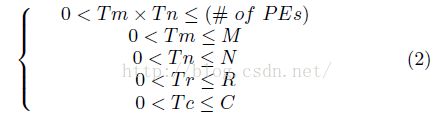
(卜居注:后面4个条件是显然的,第一个是由于循环展开、流水线的要求而必须加以限制,为了获得高计算能力,必须付出增加硬件面积的代价)
给定特定分块尺寸组合(Tm, Tn, Tr, Tc),计算性能(或roofline模型中的计算上限)可以由公式(3)计算得到。从公式中看到,计算上限是Tm和Tn的函数。

(卜居注:计算上限的单位是GFLOPS,也就是计算量除以耗时。公式分子为完成代码(1)的总乘、加计算量,分母为完成计算所需的时钟周期,由于使用了循环分块,所以括号内的时钟周期数目为流水线从开始到结束的总周期,括号外为分块外循环次数。)
3.3 访存优化
在3.2节,我们讨论了如何衍生设计变种使用不同计算上限,假设计算引擎所有数据访问都是片上已经缓存的。但是,当考虑内存带宽限制时,高计算上限的设计变种不一定能达到更高计算上限。本节我们将展示如何通过高效数据重用降低所需通信量。
图9展示了一个CNN层的内存传输操作。输入/输出特征图和权值在计算引擎开始之前就已经载入,产生的输出特征图写回主存。

本地存储提升:如果最内层循环的通信部分(图9循环变量为ti)与某个数组是无关的,那么该循环会有冗余内存操作。本地存储提升【13】可以用于降低冗余操作。
在图9中,最内层循环ti与output_fm是无关的,所以访问output_fm的操作可以提升到外层循环。注意到提升操作可以一直执行,直到与循环变量相关。
利用该技术,对output_fm的访存需求从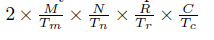 降低至
降低至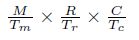 。
。
为了数据重用而实行循环变换:为了最大可能进行数据重用,我们使用基于多面体的优化框架来发现所有有效的循环变换。表3显示了循环层次和数组之间的数据共享关系。本地存储提升方法用到每个可能的循环调度中,尽可能减少总通信量。
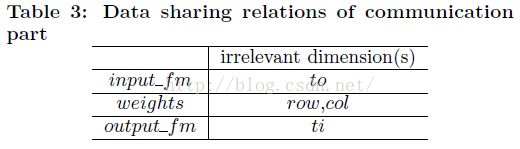
计算-通信比:用来描述每次访存的计算操作。数据重用优化会降低总的访存次数,进而提升计算-通信比。
图9代码的计算-通信比可以由公式(4)计算:

里面变量较多,分别表示如公式(5)~(11)
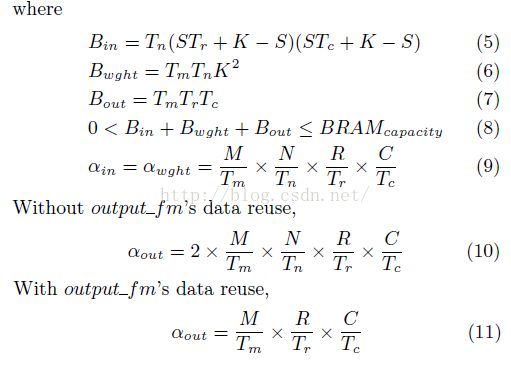
给定一个特定循环结构和分块尺寸组(Tm, Tn, Tr, Tc),计算-通信比可以通过上述公式计算得到。
3.4 设计空间探索
综上所述,给定(Tm, Tn, Tr, Tc),可以计算该设计的计算能力上限和计算-通信比。枚举所有可能的循环次序和分块尺寸可以产生一系列计算性能和计算-通信比对,图8(a)显示了例子CNN第5层在roofline模型中的所有有效解,X轴表示计算-通信比,或者每DRAM字节访问的浮点处理性能。Y轴表示计算性能(GFLOPS)。任意点与原点(0, 0)的连线斜率表示该实现的最低访存带宽需求。
例如,设计P的最低访存带宽需求和P' 是相同的。
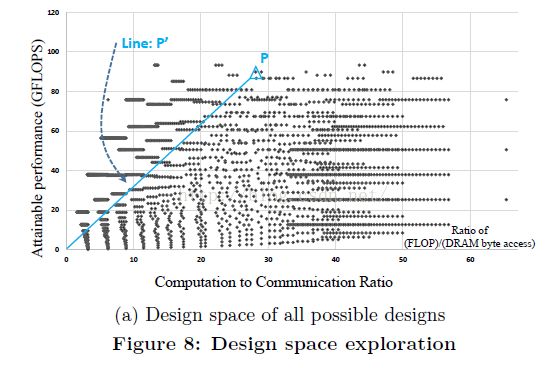
在图8(b)中,带宽上限线和计算上限是由特定平台决定的。在带宽上限线左侧的点需要比平台能提供的访存带宽更高,因此不可实现,即图中虽然设计A取得了最高的计算性能,但平台内存带宽不能满足该设计的需求,所以平台上可以获得的性能落到A' 位置。

平台支持的设计定义为:位于带宽上限线右侧的集合。位于带宽上限线的是左侧点的投影。
我们探索平台支持最优方案的策略如下:最高性能,最高计算-通信比(这样有最小的访存需求)。该准则基于我们可以使用更少IO口,更少LUT和硬件连线,数据传输引擎有更低带宽需求。因此,点C是CNN第5层的最终选择,它的带宽需求为2.2GB/s。
3.5 多层CNN加速器设计
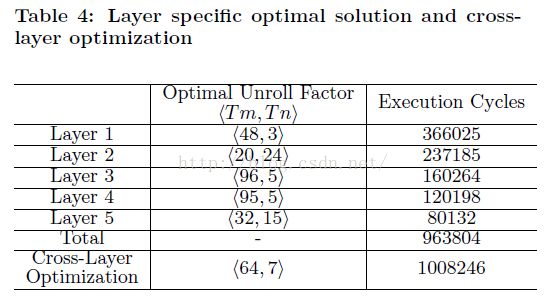
前几节我们讨论了如何为每个卷积层寻找最优实现参数。在CNN应用中,这些参数可能在不同层之间变化。表4显示了例子CNN中每层最优展开系数(Tm和Tn):
设计一个支持不同展开系数的多个卷积层的硬件加速器将会非常有挑战性,因为需要设计复杂的硬件架构来支持重配置计算引擎和互联。
一种替代方案是所有层都用同一套展开系数。我们枚举了所有可行的解来选择最优的全局设计参数。使用统一展开系数易于设计实现,但对某些层是次优解。表4表明使用统一展开系数(64, 7),性能下降不超过5%。因此我们的实验选择了这个展开系数。
枚举空间大约98,000,使用普通笔记本大约10分钟就能完成。
【4. 实现细节】
本节描述我们解决方案的具体实现。
4.1. 系统概述
图10 显示了我们的实现概述。
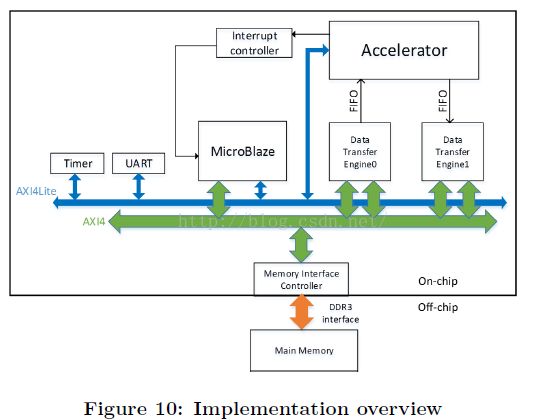
全部系统都放在了单个FPGA芯片,使用DDR3 DRAM用于外部存储。
MicroBlaze是一个RISC处理器软核,用于帮助CNN加速器启动,与主机CPU通信,以及计时。
AXI4lite总线用于传输命令,AXI4总线用于传输数据
CNN加速器作为AXI总线上一个IP。它从MicroBlaze接收命令和配置参数,与定制的数据传输引擎通过FIFO接口通信,该数据传输引擎可以获取通过AXI4总线外部存储。
MicroBlaze和CNN加速器使用中断机制来提供精确的计时。
4.2 计算引擎
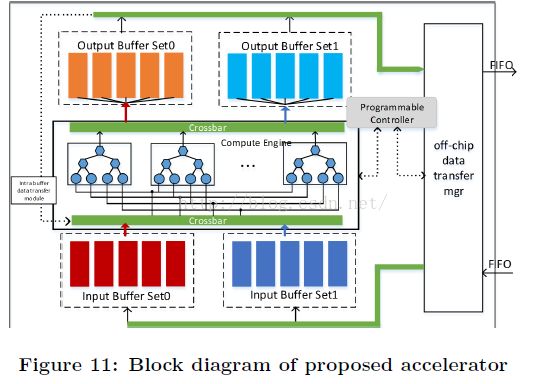
图11的计算引擎部分显示了我们实现的模块图。它们是基于第三节分析结果而设计的。
二级循环展开(图2中的Tm和Tn)实现为并行执行计算引擎,使用了类似图7的树状结构。对于最优的跨层设计(Tm, Tn)=(64,7),单个引擎接收来自输入特征图的7个输入,以及7个来自权值的输入以及一个bias输入。64个复制的结构用来展开Tm。
(卜居注:由于使用了64个相同的计算引擎,每个消耗35个dsp,有7个乘法器和7个加法器组成,每个加法器消耗2个dsp,每个乘法器消耗3个dsp)
4.3 存储子系统
片上缓冲区是基于双缓冲设计的,工作在乒乓模式来掩盖数据传输时间到计算时间中。它们一共有4组,两组用于输入特征图、权值,两组用于输出特征图。我们先介绍每个缓冲区的组织,随后介绍乒乓数据传输机制。
每个缓冲区包括几个独立的缓冲区bank,每个输入缓冲区的bank数目等于Tn(input_fm的分块尺寸)。输出缓冲区的bank数目等于Tm(output_fm的分块尺寸)。
双缓冲用于实现乒乓操作。为了简化讨论,我们使用图9的具体例子来展示乒乓操作机制。见图9中的代码。“off-load”操作只有在[N/Tn]次“load”操作后才会发生一次。但每个output_fm传输的数据量大于input_fm,比例大约为Tm/Tn = 64/7 = 9.1,为了提高带宽利用率,我们实现了两套独立通道,一个用于load操作,另一个用于off-load操作。
图12显示了计算和数据传输阶段的时序图。

第一个阶段时,计算引擎处理输入缓冲区0同时拷贝下一阶段数据到输入缓冲区1,下一阶段做相反的操作。这是输入特征图、权值的乒乓操作。
当[N/Tn]个阶段之后,输出特征图写入DRAM,"off-load"操作会将位于输出缓冲区0的结果写回DRAM,直到输出缓冲区1产生新的结果。这是输出特征图的乒乓操作。注意这两个独立存取通道机制适用于该框架下任何其他数据重用的场景。
4.4 外部数据传输引擎
使用外部数据传输引擎的目的有两个:(1)可以提供加速器和外部DRAM之间的数据传输;(2)可以隔离加速器和平台、工具相关带宽特性。
图13展示了一个实验,在Vivado 2013.4中的AXI4总线带宽。
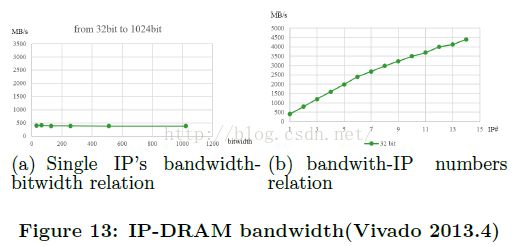
两幅图中,我们设置两个参数,AXI总线到DRAM控制器的位宽,和DRAM控制器的外部带宽,在它们最高配置下单改变IP-AXI接口数目和每个IP的位宽。
在图13(a)中,增加IP-AXI接口位宽不影响带宽(400MB/s在100MHz频率下)。
在图13(b)中,更多IP接口加入AXI总线,它的带宽几乎线性增长,最高带宽大约4.5GB/s。
在我们CNN加速器设计中,最小带宽需要1.55GB/s。根据图13,4个IP接口足够用于这个设计。我们使用两个AXI-IP接口用于数据传输引擎0,两个用于数据传输引擎1,如图10所示。
【5. 评估】
本节首先介绍我们实验环境设置,然后提供了全面的实验结果。
5.1 实验设置
加速器设计用Vivado HLS(v2013.4)实现。该工具允许用C语言实现加速器,并导出RTL为一个Vivado IP核。CNN设计C代码通过增加HLS定义的编译向导实现并行化,并行化版本通过时序分析工具进行了验证。快速综合前仿真使用该工具的C仿真和C/RTL联合仿真完成。综合前资源报告用于设计空间探索和性能估计。导出的RTL使用Vivado v2013.4进行综合、实现。
我们的实现基于VC707板卡,有一片Xilinx FPGA芯片Virtex 7 485t。它的工作频率为100MHz,软件实现运行在Intel Xeon CPU E5-2430(@2.2GHz),15MB Cache。
5.2 实验结果
本小节我们先汇报资源占用,之后对比软件实现(CPU上)和我们的加速器实现(FPGA上)。最后,给出了我们的实现和已有FPGA实现的对比情况。
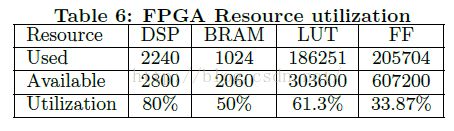
布局布线由Vivado工具集提供。之后,工具会汇报资源占用情况,如表6所示。可以看出我们的CNN加速器已经差不多完全利用了FPGA的硬件资源。
我们的加速器和基于软件的实现性能对比如表7所示。
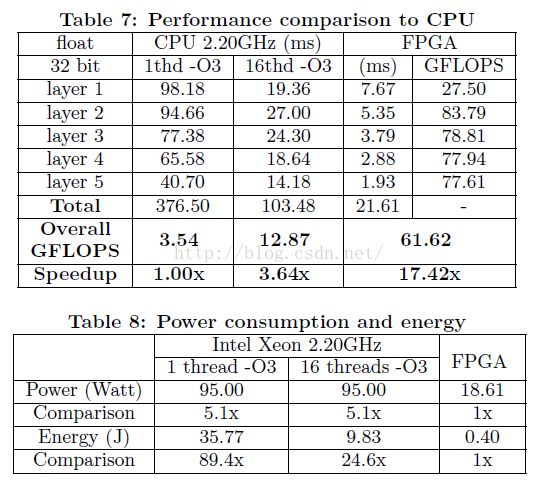
我们选择本文提出的跨层加速器作为对比。软件在单线程和16线程使用gcc带-O3优化选项实现。我们的FPGA实现相比单线程软件实现获得了17.42x加速比,同时相比16线程软件实现获得4.8x加速比。我们的加速器总性能达到61.62GFLOPS。
图14显示了我们板卡实现图。

一个功率计用来测量运行时功率特性,大约18.6瓦特。CPU的热设计功率为95瓦特。因此,我们可以粗略估计软件和FPGA的功率。
表8显示了能耗相差至少24.6倍,FPGA实现消耗更少能量。
在表5中列出了已有的不同基于FPGA的CNN加速器同我们实现的对比情况。
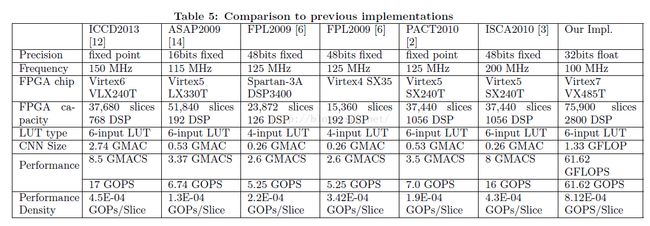
之前的方法是用GMACS,而我们用GFLOPS作为性能指标。我们首次将所有结果数字表示为GOPS,实现同等对比。注意每个乘加操作包括两个整数操作。表5的第9行显示,我们的加速器具有61.62GOPS吞吐,相比其他实现至少有3.62倍加速。
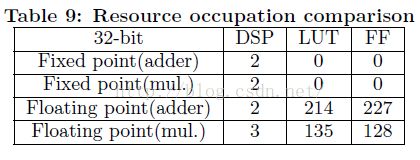
由于不同工作使用了不同并行策略和不同FPGA平台,很难有一个直接对比。为了提供公平对比,我们进一步给出“性能密度”结果,定义为单位面积(每slice)的GOPS,可表示一个设计的效率而无需考虑所用的FPGA平台,最终结果如表5最后一行所示,我们的设计获得最高性能密度,比第二名高1.8倍。另外,如果使用定点计算引擎,我们的方法可以获得更好性能和性能密度,因为定点处理单元使用更少的资源(如表9所示)。
(卜居注:定点评估有问题,加法器不需要DSP,乘法器所需资源不比浮点少)
【6. 相关工作】
本节,我们讨论不同设计方法,参考其他之前的基于FPGA的CNN加速器设计工作。
首先,很多CNN应用加速器都聚焦在优化计算引擎上。实现【6】【14】【3】是三个代表。
最早的方法【6】主要用软件搭起CNN应用,而是用一个硬件脉动结构加速器完成滤波卷积工作。这个设计省下大量硬件资源,用于自动驾驶机器人的嵌入式系统。
【14】【2】【3】在FPGA上实现了完整CNN应用,但采取了不同并行措施。【14】【2】主要利用了特征图内部卷积核的并行性。【3】使用了输出内、输出间的并行性。我们的并行方法类似,但他们并未使用片上缓冲区做数据重用,而是用很高带宽和动态重配置来提高性能。我们的实现合理进行数据重用,平衡了带宽限制和FPGA计算能力。
其次,【12】考虑了CNN的通信问题,选择最大化数据重用,将带宽需求降至最低。但他们的方法并未考虑最大化计算性能,另外当换到下一层计算时他们需要为FPGA重编程(大约10秒),而我们的方案秩序消耗不到1us来配置几个寄存器。
【7. 结论】
本文中,我们提出了基于roofline模型的CNN FPGA加速方法。首先优化CNN的计算和访存,之后将所有可能涉及在roofline模型下建模,为每层寻找最优解。我们通过枚举发现了最好的跨层设计。最终,我们在Xilinx VC707板卡上实现,性能优于以往的实现。
【8. 致谢】
【9. 参考文献】