目录
-
大数定律
-
中心极限定理
-
置信区间
-
峰度、偏度检验
-
箱线图
-
单分布卡方拟合检验
大数定律 返回目录
弱大数定律(辛钦大数定律):
设 $X_{1},X_{2},\cdots$ 是相互独立,服从同一分布的随机变量序列,且具有数学期望 $E(X_{k})=\mu(k=1,2,\cdots)$,作前 $n$ 个变量的算术平均 $\frac{1}{n}\sum_{k=1}^{n}X_{k}$ ,则对于任意 $\varepsilon>0$,有
$\lim_{n\rightarrow\infty}P\left\{ |\frac{1}{n}\sum_{k=1}^{n}X_{k}-\mu|<\varepsilon\right\} =1$.
解释:大量实验证实,随机事件$A$ 的频率 $f_{n}(A)$ 当重复实验次数 $n$ 增大时总呈现出稳定性,稳定在某一个常数附近,频率的稳定性是概率定义的可观基础。通俗地说,辛钦大数定律是说,对于独立同分布且具有均值的随机变量 $X_{1},X_{2},\cdots,X_{n}$, 当 $n$ 很大时它们的算术平均 很可能接近于它们的期望值 $\mu$.
伯努利大数定律(辛钦大数定律的推论):
设 $f_A$ 是 $n$ 次独立重复实验事件中 $A$ 发生的次数,$p$ 是事件 $A$ 在每次试验中发生的概率,则对于任意正数 $\varepsilon>0$,有
$\lim_{n\rightarrow\infty}P\left\{ |\frac{f_{A}}{n}-p|<\varepsilon\right\} =1$
或
$\lim_{n\rightarrow\infty}P\left\{ |\frac{f_{A}}{n}-p|\geq\varepsilon\right\} =0$.
解释:事件 $\left\{ |\frac{f_{A}}{n}-p|<\varepsilon\right\} $ 是一个小概率事件,这一事件在一次试验中实际上几乎是不发生的,但是当 $n$ 充分大时,该事件几乎是必定发生,也就是说对于给定的任意小的正数 $\varepsilon$, 在 $n$ 充分大时,事件“频率 $\frac{f_{A}}{n}$ 与概率 $p$ 的偏差小于 $\varepsilon$”实际上几乎必定要发生。在实际应用中,当实验次数很大时,便可以用事件的频率来替代事件的概率.
中心极限定理 返回目录
在客观实际中有许多随机变量,它们是由大量的相互独立的随机因素的综合影响所形成,而其中每一个别因素在总的影响中所起的作用都是微小的。这种随机变量往往近似地服从正态分布。这种现象就是中心极限定律的可观背景。
独立同分布的中心极限定理
设随机变量 $X_{1},X_{2},\cdots,X_{n},\cdots$ 相互独立,服从同一分布,且具有数学期望和方差:$E(X_{k})=\mu,D(X_{k})=\sigma^{2}>0(k=1,2,\cdots)$,则随机变量之和 $\sum_{k=1}^{n}X_{k}$ 的标准化变量
$Y_{n}=\frac{\sum_{k=1}^{n}X_{K}-E(\sum_{k=1}^{n}X_{k})}{\sqrt{D(\sum_{k=1}^{n}X_{k})}}=\frac{\sum_{k=1}^{n}X_{k}-n\mu}{\sqrt{n}\sigma}$
近似地服从正态分布$N(0,1)$.
换成另外一种容易理解的说法:均值为 $\mu$, 方差为 $\sigma^{2}>0$ 的独立同分布的随机变量 $X_{1},X_{2},\cdots,X_{n}$ 的算术平均 $\bar{X}=\frac{1}{n}\sum_{k=1}^{n}X_{k}$, 当 $n$ 充分大时近似地服从均值为 $\mu$,方差为 $\frac{\sigma^{2}}{n}$ 的正态分布.
中心极限定理表明,在相当一般的条件下,当独立随机变量的个数不断增加时,其和的分布趋于正态分布,这一事实阐明了正态分布的重要性,也揭示了为什么在实际应用中会经常遇到正态分布,也就是揭示了产生正态分布变量的源泉. 另一方面,他提供了独立同分布随机变量之和$\sum_{k=1}^{n}X_{k}$(其中$X_{k}$的方差均存在)的近似分布,只要和式中加项的个数充分大,可以不必考虑和式中的随机变量服从什么分布,都可以用正态分布来近似,这在应用上是有效和重要的。
中心极限定理的内容包含极限,因而称它为极限定理是很自然的,又由于它在统计中的重要性,称它为中心极限定理,这是波利亚(Polya)在1920年取的名字.
置信区间 返回目录
设总体 $X$ 的分布函数 $F(x;\theta)$ 含有一个未知参数 $\theta$, $\theta\in\varTheta$, ($\varTheta$ 是 $\theta$ 可能取值的范围), 对于给定值 $\alpha$ ($0<\alpha <1$), 若由来自 $X$ 的样本 $X_1, X_2, ..., X_n$, 确定的两个统计量 $\bar{\theta}=\bar{\theta}(X_{1},X_{2},\cdots,X_{n})$ 和 $\underline{\theta}=\underline{\theta}(X_{1},X_{2},\cdots,X_{n})$ ($\underline{\theta}<\bar{\theta}$), 对于任意 $\theta\in\varTheta$ 满足
$P\{\underline{\theta}(X_{1},X_{2},\cdots,X_{n})<\theta<\bar{\theta}(X_{1},X_{2},\cdots,X_{n})\}\geq1-\alpha$
则称随机区间 $(\underline{\theta},\bar{\theta})$ 是 $\theta$ 的置信水平为 $1-\alpha$ 的置信区间,$\bar{\theta}$ 和 $\underline{\theta}$ 分别称为置信水平为 $1-\alpha$ 的双侧置信区间的置信下限和置信上限,$1-\alpha$ 称为置信水平.
解释:若反复多次抽样(各次得到的样本容量相等,都是 $n$).每一个样本值确定一个区间 $(\underline{\theta},\bar{\theta})$,每个这样的区间要么包含 $\theta$ 的真值,要么不包含 $\theta$ 的真值. 按照伯努利大数定理,在这么多区间中,包含 $\theta$ 真值的约占 $100(1-\alpha)\%$,不包含 $\theta$ 真值的约占 $100\alpha\%$. 例如 $\alpha=0.01$,反复抽样 1000 次,则得到的 1000 个区间中不包含 $\theta$ 真值的约仅为 10 个.
对于一个未知量,人们在测量或计算时,常不以得到近似值为满足,还需要估计误差,即要求知道近似值的精确程度(亦即真值所在的范围). 类似地,对于未知参数 $\theta$,除了求出它的点估计 $\hat{\theta}$ 外, 我们还需要估计出一个范围,并希望知道这个范围包含参数 $\theta$ 真值的可信程度. 这样的范围通常以区间估计的形式给出,同时还给出此区间包含参数 $\theta$ 真值的可信程度。
峰度、偏度检验 返回目录
由中心极限定理可知,正态分布是较广泛地存在的,因此,当研究一连续型总体时,人们往往先考察它是否服从正态分布, 在正态性检验方法中,总的来说,以“偏度、峰度检验法”及“夏皮罗-威尔克法”较为有效.
随机变量 $X$ 的偏度和峰度指的是 $X$ 的标准化变量 $[X-E(X)]/\sqrt{D(X)}$ 的三阶矩和四阶矩:
$\nu_{1}=E\left[\left(\frac{X-E(X)}{\sqrt{D(X)}}\right)^{3}\right]=\frac{E[(X-E(X))^{3}]}{(D(X))^{3/2}}$
$\nu_{2}=E\left[\left(\frac{X-E(X)}{\sqrt{D(X)}}\right)^{4}\right]=\frac{E[(X-E(X))^{4}]}{(D(X))^{2}}$
当随机变量 $X$ 服从正态分布时, $\nu_{1}=0, \nu_{2}=3$.
设 $X_{1},X_{2},\cdots,X_{n}$ 是来自总体 $X$ 的样本, 并分别称 $G_{1},G_{2}$ 为样本的偏度和样本峰度.
若总体 $X$ 为正态变量,则可证当 $n$ 充分大时,近似地有
$G_{1}\sim N\left(0,\frac{6(n-2)}{(n+1)(n+3)}\right)$
$G_{2}\sim N\left(3-\frac{6}{n+1},\frac{24n(n-2)(n-3)}{(n+1)^{2}(n+3)(n+5)}\right).$
设 $X_{1},X_{2},\cdots,X_{n}$ 是来自总体 $X$ 的样本. 现在来检验假设
$H_{0}$: $X$ 为正态总体.
记
$\sigma_{1}=\sqrt{\frac{6(n-2)}{(n+1)(n+3)}},\sigma_{2}=\sqrt{\frac{24n(n-2)(n-3)}{(n+1)^{2}(n+3)(n+5)}},$
$\mu_{2}=3-\frac{6}{n+1},U_{1}=G_{1}/\sigma_{1},U_{2}=(G_{2}-\mu_{2})/\sigma_{2}.$ 当 $H_{0}$ 为真且 $n$ 充分大时,近似地有
$U_{1}\sim N(0,1),U_{2}\sim N(0,1).$
由抽样分布中关于“矩”的知识可以知道,样本偏度 $G_1$, 样本峰度 $G_2$ 分别以概率收敛于总体偏度 $\nu_{1}$ 和总体峰度 $\nu_{2}$. 因此当 $H_{0}$ 为真且 $n$ 充分大时,一般来说,$G_1$ 与 $\nu_{1}=0$ 的偏离不大,而 $G_2$ 与 $\nu_{2}=3$ 的偏离不应该太大. 故从直观来看当 $|U_{1}|$ 的观察值 $|u_{1}|$ 或 $|U_{2}|$ 的观察值 $|u_{2}|$ 过大时就拒绝 $H_{0}$. 取显著水平为 $\alpha$,$H_{0}$的拒绝域为:
$|u_{1}|\geq k_{1}$ 或 $|u_{2}|\geq k_{2}$
其中 $k_{1},k_{2}$ 由以下两式确定:
$P_{H_{0}}\{|U_{1}|\geq k_{1}\}=\frac{\alpha}{2},P_{H_{0}}\{|U_{2}|\geq k_{2}\}=\frac{\alpha}{2}.$
这里记号 $P_{H_{0}}\{\bullet\}$ 表示当 $H_{0}$ 为真时事件 $\{\bullet\}$ 的概率,即有 $k_{1}=z_{\alpha/4},k_{2}=z_{\alpha/4}.$ 于是得拒绝域为
$|u_{1}|\geq z_{\alpha/4}$ 或 $|u_{2}|\geq z_{\alpha/4}$
下面来验证当 $n$ 充分大时上述检验法近似地满足显著水平为 $\alpha$ 的要求.
事实上当 $n$ 充分大的时候有
$P${当 $H_{0}$ 为真拒绝 $H_{0}$ }
$=P_{H_{0}}\{(|U_{1}|\geq z_{\alpha/4})\cup(|U_{2}|\geq z_{\alpha/4})\}$
$\leq P_{H_{0}}\{|U_{1}|\geq z_{\alpha/4}\}+P_{H_{0}}\{|U_{2}|\geq z_{\alpha/4}\}=\frac{\alpha}{2}+\frac{\alpha}{2}=\alpha.$
例 下面列出了 84 个男子的头颅的最大宽度(mm), 现在来分析这些数据(下载:headWidth.rar)是否来自正态总体(取显著水平$\alpha=0.1$).
解 现在来检验假设
$H_0$:数据来自正态总体.
这里 $\alpha=0.1,n=84,\sigma_{1}=\sqrt{\frac{6(n-2)}{(n+1)(n+3)}}=0.2579,\sigma_{2}=\sqrt{\frac{24n(n-2)(n-3)}{(n+1)^{2}(n+3)(n+5)}}=0.4892,\mu_{2}=3-\frac{6}{n+1}=2.9294.$
下面计算样本中心矩$B_2,B_3,B_4$,计算时可以利用以下关系式:
$B_{2}=A_{2}-A_{1}^{2},B_{3}=A_{3}-3A_{2}A_{1}+2A_{1}^{3},$
$B_{4}=A_{4}-4A_{3}A_{1}+6A_{2}A_{1}^{2}-3A_{1}^{4},$
其中 $A_{k}=\frac{1}{n}\sum_{i=1}^{n}X_{i}^{k},(k=1,2,3,4)$ 为 $k$ 阶样本矩. 经计算的 $A_k (k=1,2,3,4), B_k (k=2,3,4)$ 的观察值分别为
$A_1=143.7738, A_2=20706.13, A_3=2987099, A_{4}=4.136426\times10^{8}, B_2=35.2246, B_3=-28.5, B_4=3840.$
样本的偏度和峰度的观察值分别为
$g_1=-0.1363, g_2=3.0948.$
而 $z_{\alpha/4}=z_{0.025}=1.96.$ 所以拒绝域为:
$|u_{1}|=|g_{1}/\sigma_{1}|\geq1.96$ 或 $|u_{2}|=|g_{2}-\mu_{2}|/\sigma_{2}\geq1.96.$
现在算得 $|u_{1}|=0.528<1.96,|u_{2}|=0.338<1.96$, 故接受 $H_0$,认为数据来自正态分布的总体.
上述检验法称为"偏度(skewness)、峰度(kurtosis)检验法",使用这一检验法时,以样本数大于100为宜.
偏度直观上表征分布曲线相对于平均值的不对称程度的特征数,负偏度也称左偏态,此时数据位于均值左边的个数要比位于右边的个数少,使得曲线左侧尾部拖的很长,正偏度也称右偏态,直观上右边的尾部相对于左边的尾部要长,因为少数变量值很大,使得曲线右侧尾部拖得很长,正态分布是对称的,偏度为 0.
峰度直观上描述了分布曲线的陡峭程度。峰度为 3 表示与正态分布相同,峰度大于 3 表示比正态分布陡峭,峰度小于 3 表示比正态分布平缓。
在实际使用过程中,我们当然不会自己去手动计算,这里使用SPSS来对上面的数据进行“偏度、峰度检验“,但是在统计软件进行计算峰度时,通常将峰度的作值减 3 处理,使得正态分布的峰度为 0.
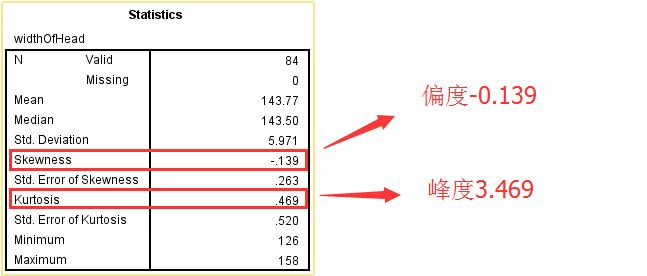
计算结果与上面手动计算结果基本一致,说明可以认定该数据来自正态总体. 画出上面数据的频率分布曲线,来直观看一下:
 可以看出频率分布曲线与图中正态分布曲线(红色)基本相符合!
可以看出频率分布曲线与图中正态分布曲线(红色)基本相符合!
箱线图 返回目录
首先介绍样本分位数.
定义 设有容量为 $n$ 的样本观察值 $x_1,x_2,x_3,\cdots,x_n$, 样本的 $p$ 分位数($0
样本 $p$ 的分位数可按照以下法则求得.将 $x_1,x_2,\cdots,x_n$ 按照自小到大的次序排成 $x_{(1)}\leq x_{(2)}\leq\cdots\leq x_{(n)}$.
1. 若 $np$ 不是整数,则只有一个数据满足定义中的两点要求,这一数据位于大于 $np$ 的最小整数处,即为位于 $[np]+1$ 处的数. 例如, $n=12,p=0.9, np=10.8,n(1-p)=1.2$,则 $x_p$ 的位置应满足至少有 10.8 个数据 $\leq x_p$ ($x_p$ 应位于第 11 或者大于第 11 处);且至少有 1.2 个数据 $\geq x_p$ ($x_p$ 应位于第 11 或者小于 第 11 处), 故 $x_p$ 应位于第 11 处.
2. 若 $np$ 是整数. 例如在 $n=20, p=0.95$ 时,$x_p$ 的位置应满足至少有 19 个数据 $\leq x_p$ ($x_p$ 应位于第 19 或者大于第 19 处)且至少有 1 个数据 $\geq x_p$($x_p$ 应位于第 20 或者小于第 20 处), 故第 19 或第 20 的数据均符合要求,就取这两个数的平均值作为 $x_p$.
综上,
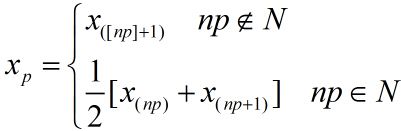
特别,当 $p=0.5$ 时, 0.5 分位数 $x_{0.5}$ 也记为 $Q_2$ 或 $M$, 称为样本中位数. 0.25 分位数 $x_{0.25}$ 称为第一四分位数,又记为 $Q_1$;0.75 分位数 $x_{0.75}$ 称为第三四分位数,又记为 $Q_3$,$x_{0.25},x_{0.5},x_{0.75}$在统计中是很有用的.
下面介绍线箱图.
数据集的线箱图是由箱子和直线组成的图形,它是基于以下 5 个数的图形概括:最小值 $Min$,第一四分位数 $Q_1$, 中位数 $M$,第三四分位数 $Q_3$ 和最大值 $Max$. 它的作法如下:
(1)画一水平(或垂直)数轴,在轴上标上 $Min,Q_1,M,Q_3,Max$. 在数轴上方画一个上下侧平行于数轴的矩形箱子,箱子的左右两侧分别位于 $Q_1,Q_3$ 的上方,在 $M$ 点的上方画一条垂直线段. 线段位于箱子内部.
(2)自箱子左侧引一条水平线直至最小值 $Min$;在同一水平高度自箱子右侧引一条水平线直至最大值. 这样就将箱线图作好了.
还是上面头颅宽度的数据,我们利用SPSS作出箱线图.
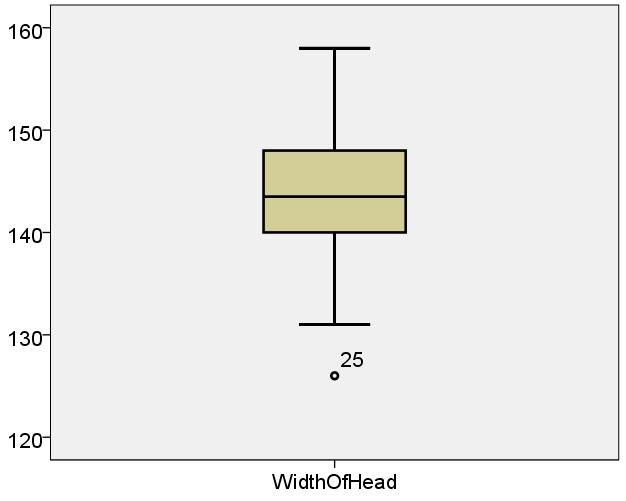
在数据集中某一个观察值不寻常地大于或小于该数据集中的其他数据,称为疑似异常值. 疑似异常值会对随后的计算结果产生不适当的影响. 检测意思异常值并加以适当处理是十分重要的. 线箱图只要稍加修改,就能用来检测数据集是否存在疑似异常值.
第一四分位数 $Q_1$ 与第三四分位数 $Q_3$ 之间的距离:$Q_{3}-Q_{1}=IQR$ 称为四分位数间距. 若数据小于 $Q_{1}-1.5IQR$ 或大于 $Q_{3}+1.5IQR$, 就认为它是疑似异常值,将上述箱线图的作法(1),(2),(3)作如下改变:
(1')同(1)
(2')计算 $IQR=Q_{3}-Q_{1}$,若一个数据小于 $Q_{1}-1.5IQR$ 或大于 $Q_{3}+1.5IQR$,则认为它是一个疑似异常值. 画出疑似异常值,并以 * 表示.
(3')自箱子下侧引一垂直线段直至数据集中除去疑似异常值后的最小值,又自箱子上侧引出一竖直线直至数据集中除去疑似异常值后的最大值.
按照(1')(2')(3')做出的图形称为修正箱线图. 实际上上面用SPSS画出的就是一个修正箱线图,只不过该软件中使用圆圈表示疑似异常值,而不是 *,25表示第25个样本值异常.
线箱图特别适合用于比较两个或者两个以上的数据集的性质,只需将多个箱线图画在同一个数轴上,就可以比较数据集的记作位置和分散情况,如下:
下面分别给出了25个男子和25个女子的肺活量(以升计,已排序),画出二者的箱线图.
男子组
| 4.1 | 4.1 | 4.3 | 4.3 | 4.5 | 4.6 | 4.7 | 4.8 | 4.8 | 5.1 | 5.3 | 5.3 |
| 5.3 | 5.4 | 5.4 | 5.5 | 5.6 | 5.7 | 5.8 | 5.8 | 6 | 6.1 | 6.3 | 6.7 | 6.7 |
女子组
| 2.7 | 2.8 | 2.9 | 3.1 | 3.1 | 3.1 | 3.2 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 |
| 3.5 | 3.5 | 3.5 | 3.6 | 3.7 | 3.7 | 3.7 | 3.8 | 3.8 | 4 | 4.1 | 4.2 | 4.2 |
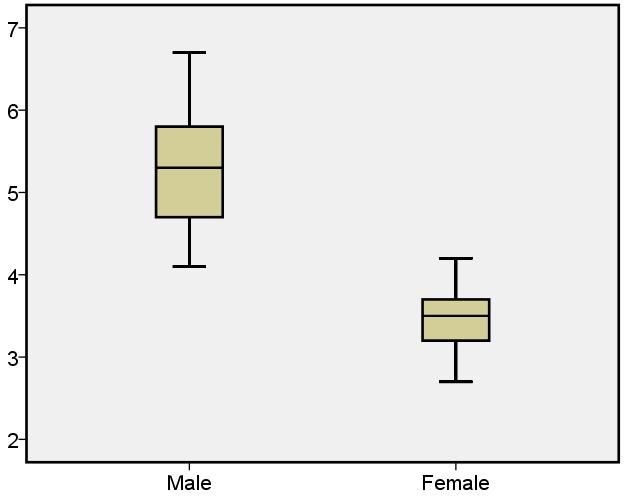
从上图可以较明显低看出男子的肺活量要比女子大,男子的肺活量要比女子的肺活量分散.
单个分布的卡方($\chi^{2}$)拟合检验 返回目录
设总体 $X$ 的分布未知,$x_{1},x_{2},\cdots,x_{n}$ 是来自 $X$ 的样本值. 我们来检验假设
$H_0: 总体 X 的分布函数为 F(x).$
$H_1: 总体 X 的分布函数不是 F(x).$
其中设 $F(x)$ 不含未知参数. (也常以分布律或概率密度代替).
下面来定义检验统计量. 将在 $H_0$ 下的 $X$ 可能取值的全体 $\varOmega$ 分成互不相交的子集 $A_{1},A_{2,}\cdots,A_{k}$, 以 $f_{i} (i=1,2,\cdots,k)$ 记录样本观察值 $x_{1},x_{2},\cdots,x_{n}$ 中落在 $A_i$ 的个数,这表示事件 $A_{i}={X 的值落在子集 A_i 内}$ 在 $n$ 次独立试验中发生 $f_i$ 次, 于是在这 $n$ 次试验中事件 $A_i$ 发生的频率为 $f_{i}/n.$ 另一方面,当 $H_0$ 为真时,我们可以根据 $H_0$ 中所假设的 $X$ 的分布函数来计算事件 $A_{i}$ 的概率,得到 $p_i=P(A_{i}), i=1,2,\cdots,k.$ 频率 $f_{i}/n$ 与概率 $p_i$ 会有差异,但一般来说,当 $H_0$ 为真, 且试验次数又甚多时,这种差异不应太大,因此$\left(\frac{f_{i}}{n}-p_{i}\right)^{2}$ 不应太大,采用形式如:
$\sum_{i=1}^{k}C_{i}\left(\frac{f_{i}}{n}-p_{i}\right)^{2}$
的统计量来度量样本与 $H_0$ 中所假设的分布吻合程度, 其中 $C_{i} (i=1,2,\cdots,k)$ 为给定的常数. 皮尔逊证明,如果选取 $C_i=n/p_{i} (i=1,2,\cdots,k)$, 则有如下性质:
若 $n$ 充分大($n\geq50$), 则当 $H_0$ 为真时,统计量 $\sum_{i=1}^{k}C_{i}\left(\frac{f_{i}}{n}-p_{i}\right)^{2}$ 近似服从 $\chi^{2}(k-1)$ 分布.
于是采用:
$\chi^{2}=\sum_{i=1}^{k}\frac{n}{p_{i}}\left(\frac{f_{i}}{n}-p_{i}\right)^{2}=\sum_{i=1}^{n}\frac{f_{i}^{2}}{np_{i}}-n$
作为检验统计量.
据以上讨论,当 $H_0$ 为真时, 上述统计量 $\chi^{2}$ 不应太大,如 $\chi^{2}$ 过分大就拒绝 $H_0$, 拒绝域的形式为
$\chi^{2}\geq G (G为正常数).$
对于给定的显著水平 $\alpha$, 确定 $G$ 使
$P{当 H_{0} 为真时拒绝 H_{0} }=P_{H_{0}}\{\chi^{2}\geq G\}=\alpha.$
所以 $G=\chi_{\alpha}^{2}(k-1)$. 即当样本观察值中的 $\chi^{2}$ 的值有
$\chi^{2}\geq\chi_{\alpha}^{2}(k-1),$
则在显著水平 $\alpha$拒绝 $H_0$,否则就接受 $H_0$. 这个就是单个分布的 $\chi^{2}$ 拟合检验法.
$\chi^{2}$ 拟合检验法拟合检验法时基于上面的定理得到的,所以使用时必须注意 $n$ 不能小于 50. 另外 $np_{i}$ 不能太小,应有 $np_{i}\geq5$, 否则应适当合并 $A_i$, 以满足这个要求.
例题 下表列出了某一地区在夏季的一个月中 100 个气象站报告的雷暴雨次数.
| $i$ | 0 | 1 | 2 | 3 | 4 | 5 | $\geq6$ |
| $f_i$ | 22 | 37 | 20 | 13 | 6 | 2 | 0 |
| $A_i$ | $A_0$ | $A_1$ | $A_2$ | $A_3$ | $A_4$ | $A_5$ | $A_6$ |
解 按题意需检验假设
$H_{0}:P\{X=i\}=\frac{\lambda^{i}e^{-\lambda}}{i!}=\frac{e^{-1}}{i!},i=0,1,\cdots.$
在 $H_{0}$ 下 $X$ 所有可能值为 $\varOmega=\{0,1,2,\cdots\},$, 将 $\varOmega$ 分成如表所示的两两不相交的子集 $A_{0},A_{1},\cdots,A_{6}$, 则有
$P\{X=i\}$ 为
$p_{i}=P\{X=i\}=\frac{e^{-1}}{i!},i=0,1,\cdots,5.$
例如
$p_{0}=P\{X=0\}=e^{-1}=0.36788,$
$p_{3}=P\{X=3\}=\frac{e^{-1}}{3!}=0.06131,$
$p_{6}=P\{X\geq6\}=1-\sum_{i=0}^{5}p_{i}=0.059,$
$n=100$.
$\chi^{2}拟合检验计算表$ $A_{i}$ $f_i$ $p_i$ $np_{i}$ 是否合并 $f_{i}^{2}/(np_{i})$ $A_{0}:{X=0}$ 22 $e^{-1}$ 36.788 否 13.16 $A_{1}:{X=1}$ 37 $e^{-1}$ 36.788 否 37.21 $A_{2}:{X=2}$ 20 $e^{-1}/2$ 18.394 否 21.75 $A_{3}:{X=3}$
$A_{4}:{X=4}$
$A_{5}:{X=5}$
$A_{6}:{X\geq6}$
13
6
2
0
$e^{-1}/6$
$e^{-1}/24$
$e^{-1}/120$
$1-\sum_{i=0}^{5}p_{i}$
6.131
1.533
0.307
0.059
合并:8.03
54.92 计算结果如上表所示, 其中有些 $np_i<5$ 的组合予以适当合并,使得每组均有 $np_i\geq5$, 如上表所示. 并组后 $k=4$,$\chi^{2}$ 的自由度为 $k-1=4-1=3.\chi_{0.05}^{2}(k-1)=\chi_{0.05}^{2}(3)=7.815.$ 现在 $\chi^{2}=13.16+37.21+21.75+54.92-100=27.04>7.815,$ 故在显著水平 0.05 下拒绝 $H_0$, 认为样本不是来自均值为 $\lambda=1$ 的泊松分布.