二分类模型评价方法
二分类模型是输出只有0,1的分类模型。本文介绍二分类模型的评价指标。
from sklearn import metrics
y_pred = [0, 1, 0, 0] #模型的预测输出
y_true = [0, 1, 0, 1] #真实值
二分类模型中可能的分类结果如下图的混淆矩阵,混淆矩阵涵盖了二分类模型所有可能的输出。
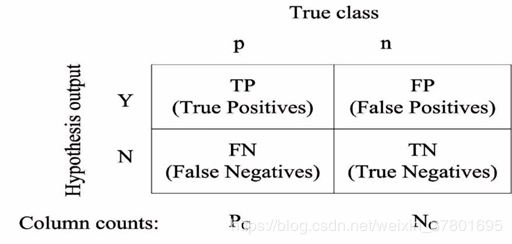
Sklearn计算混淆矩阵
metrics.confusion_matrix(y_true=y_true, y_pred=y_pred)
1、准确率
![]()
准确率表示所有正确分类的数据的概率,对各个类平等对待,对于数据分布不平衡情况下,大类别主导了准确率的计算。
metrics.accuracy_score(y_true=y_true, y_pred=y_pred)
2、平均准确率
![]()
针对不平衡数据,对n个类,分别计算每个类别的准确率,然后求平均值。
metrics.average_precision_score(y_true=y_true, y_score=y_pred)
3、 精确率(Precision)
精确率也叫查准率![]()
metrics.precision_score(y_true, y_pred)
4、 召回率(Recall)
![]()
召回率也叫查全率
metrics.recall_score(y_true, y_pred)
5、 F1-score
![]()
精确率反映了模型对负样本的区分力,召回率反映了模型对正样本的识别力,F1-score是两者的综合,F1-score值越大,分类模型越稳健。
metrics.f1_score(y_true, y_pred)
metrics.fbeta_score(y_true, y_pred, average=None, beta=0.5) # beta为精确度的权重。
6、 ROC曲线(Receiver Operating Characteristic)和AUC
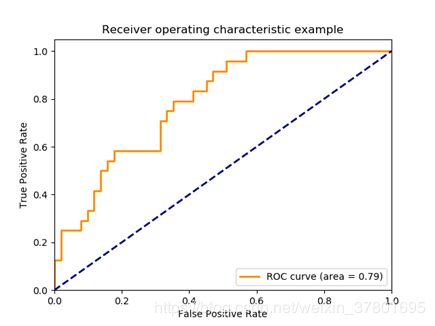
ROC曲线的横轴为False Positive Rate(FPR),纵轴为True Positive Rate(TPR)。
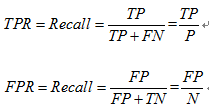
AUC为曲线下面的面积,作为评估指标,AUC值越大,说明模型越好。
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
metrics.roc_auc_score(y_test, dataset_pred)
7、 对数损失(Log-loss)
二分类的损失函数
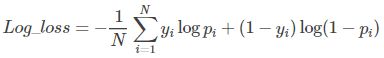
针对分类输出不是类别,而是类别的概率,使用对数损失函数进行评价。yi表示第i个样本类别0或1。pi表示其输入类别1的概率。其实就是真实值与预测值的交叉熵,包含了真实分布的熵加上假设与真实分布不同的分布的不确定性,最小化交叉熵,便是最大化分类器的准确率。
y_true, y_pred = [0,0,1,1], [[0.9,0.1],[0.8,0.2],[0.3,0.7],[0.01,0.99]]
log_loss = metrics.log_loss(y_true,y_pred)
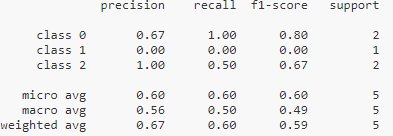
8、分类报告
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 1, 0]
target_names = [‘class 0’, ‘class 1’, ‘class 2’]
print(classification_report(y_true, y_pred, target_names=target_names))