论文阅读:【RetinaNet】Focal Loss for Dense Object Detection
论文地址:https://arxiv.org/pdf/1708.02002.pdf
代码: Pytorch , tensorflow
创新点:
这篇文章重新定义目标检测中loss损失函数,引入一种新的Focal loss 用来替代 one-stage中的损失函数,作者分析 two-stage 检测方法精度优于one-stage主要由于 e a s y easy easy识别样本类别与 h a r d hard hard识别样本不均导致。
对于two-stage解样本不均的方法采用:(1).选择性搜索产生大量区域框, RPN网络建议阶段迅速缩小了区域框(1~2K个)。(2)区域框分类阶段,前景和背景比率设定为1:3,检测目标候选对象位置的数目进一步变小。
对于one-stage方法来说: (1).单级检测器对图像特征图的像素产生长宽比例不同区域框进行回归,大约为100K个框,覆盖图像区域。 文中作者说one-stage没有区分前景框和背景框的比例,造成 e a s y easy easy样本类别与 h a r d hard hard样本不均衡,导致识别精度差,提出使用 h a r d hard hard样本挖掘的方法来提高one-stage模型的识别精度。
RetinaNet高效、准确;我们最好的模型,基于一个ResNet-101-FPN主干网,在运行速度为5帧/秒的情况下,实现了COCO test-dev AP 39.1 。
( 这 个 速 度 还 是 慢 呀 , M A P 可 以 与 Y O L O V 3 一 比 这个速度还是慢呀,MAP可以与YOLOV3一比 这个速度还是慢呀,MAP可以与YOLOV3一比)

Focal Loss
设计了Focal Loss损失通过降低内部加权来解决类不平衡问题,例如对 e a s y easy easy样本: h a r d hard hard样本 =1000:1来说, e a s y easy easy样本对全部损失的贡献是即使数量很大,Focal Loss对其加权减小Loss比重。
二元分类的交叉熵损失

令y={ ± \pm ± 1 }代表标签类别 , p ϵ \epsilon ϵ [0,1] 是代表y=1时的概率,简化CE公式为:

![]()
下图蓝色的线表示CE Loss曲线,从中看出P>0.5的样本(理解为 e a s y easy easy样本,占loss在0-1的轴长很大,表明CE loss对样本类别不均没有好的处理)

平衡交叉熵(Balanced Cross Entropy)
在CE loss的基础上添加权重因子a ϵ \epsilon ϵ [0,1], 当y为1时,权重因子a,y为-1时,权重因子为1-a。

焦损失函数(Focal Loss)
在密集探测器训练过程中遇到的样本类不均衡压倒了交叉熵损失。 容易分类的负样本包括大部分损失并主导梯度。 虽然a因子平衡了正/负样本示例的权重,但它并没有区分简单/困难样本。 Focal Loss重塑损失函数定义如下:
1 − p t 1-p_{t} 1−pt 表示权重因子, p t p_{t} pt越接近1,表示易分类样本,影响因子越接近于0, 相反, p t p_{t} pt越接近0,表示难分类样本,则权重因子占比重越大。
r r r 调制因子减少了来自简单示例的损失贡献,并扩展了接受低损失的范围。 r r r=0, Focal Loss=CE loss ,,论文中将 r r r=2,实验结果最好
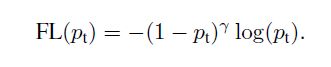
作者又在此基础上说,增加一个平衡变量因子 a t a_{t} at,效果会好点 [疑惑?], a t = 0 : 25 a_{t}= 0:25 at=0:25 works best

RetinaNet Detector
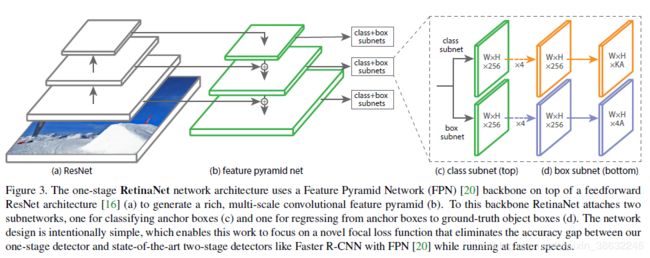
RetinaNet 网络架构 (a)ResNet提取特征图。(b)前端采用FPN(Feature Pyramid Network,金字塔池化)网络,FPN改进FCN的多尺度预测。(c)后接分类子网络和bounding box回归的子网络。
要点:FPN通道数256,从P3~P7(P表示层),从 3 2 2 32^2 322到 51 2 2 512^2 5122每层缩小一倍像素数,Anchors个数, 长宽比率设置为{1:2; 1:1, 2:1}三种, 每种再细分为{ 2 0 , 2 1 / 3 , 2 2 / 3 {2^0,2^{1/3}, 2^{2/3}} 20,21/3,22/3}的不同size大小, 即每个像素9个Anchor, IOU与其他CNN算法一样,阈值0.5,不过直接忽略(0.4-0.5)的box。0.4以下为背景。
Classification Subnet 和 Box Regression Subnet附加在FPN的每层进行预测,9个Anchor预测属于K类物体的概率,则分类产生9K向量, Box Regression 对每个Anchor 产生4个坐标预测,总共9X4个向量。
实验结果

AP50,AP60,AP75……等等指的是取detector的IoU阈值大于0.5,大于0.6,大于0.75……等等。可以看到数值越高,精确率越低,表明越难.
图a CE loss 中 a = 0.75 a=0.75 a=0.75,AP 最高,图b FL loss将 a = 0.25 , r = 2 a=0.25,r=2 a=0.25,r=2 获得最高AP 34.0
其他图对网络微调(样本挖掘),AP提升到36-37.0

与经典网络对比一下,RetinaNet AP比SSD,YOLOV2 都要高,作者在这里没有比较速度,RetinaNet 的速度如前面图一是不及SSD和YOLO的。但MAP确实有一些提升吧。