MATLAB+二值贝叶斯分类器的手写汉字识别(简易实现)
写在前头
~~~~ ~~~ 本文以二值贝叶斯作为分类器,利用MATLAB编程工具,实现对9个手写汉字的识别。训练样本是本人手写,数量不大,所以重在描述个人对其工作原理的理解,仅供大家参考和指正。
模式识别基本概念
~~~~ ~~~ (重于过程实现的可以跳过本部分)
这里参考杨淑莹老师的《模式识别与智能计算》一书,对模式识别作简单的介绍:
模式识别(Pattern Recognition)就是机器识别、计算机识别或机器自动识别,目的在于让机器自动识别事物。例如,手写汉字的识别,是将手写的汉字分到具体的汉字类别中;以及车牌识别、语音识别、图像中物体识别等等,实际上都是一个分类的过程。
在本文的9个手写汉字识别中,就是要比较待识别对象和这些汉字中的哪一个最为相似或接近。因此首先要能够提取不同汉字之间的差异,才能够分辨当前要识别的汉字。
模式识别的过程由数据获取、预处理、特征提取、分类决策、分类器设计组成:
1.数据获取:
用计算机可以运算的符号来表示所研究的对象,一般获取的数据类型有二维图像(文字、指纹、地图),一维波形(脑电图、心电图),物理参量和逻辑值(体温、化验数据)。
2.预处理:
对输入测量仪器或其他因素所造成的退化现象进行复原、去噪声,提取有用信息。
3.特征提取和选择:
对原始数据进行变换,得到最能反应分类本质的特征。将维数较高的测量空间(原始数据组成的空间)转变为维数较低的特征空间(分类识别赖以进行的空间)。
4.分类决策:
在特征空间中用模式识别方法把被识别对象归为某一类别。
5.分类器设计:
基本做法是在样品训练集基础上确定判别函数,改进判别函数和误差检验。
在这整个过程中,特征提取和选择以及分类器设计这两个部分,是经常作为重点讨论和分析实现的部分。对于汉字识别来讲,常用的特征选择方法有网格特征、外轮廓特征、内轮廓特征等,本文采用的是网格特征。常见的分类器有模板匹配分类器、基于概率统计的贝叶斯分类器、几何分类器、神经网络分类器等,本文采用的是二值贝叶斯分类器。
手写汉字识别的实现
1.特征选择和提取
1.1 特征选择和提取方式
本文采用网格特征的选择,定义一个10x10模板,在每个汉字图形上提取特征值,即将每个样品的长和宽进行十等分,则共有100个等份,如下图所示:

模板的大小是可更改的,分成的等份越多,在比较分类的过程中结果也会更加精确,但其计算量也会随之变得十分巨大,但本文识别的样本库只有9类汉字,计算量再大也上不了天。但是如果要做大做强,再创辉煌…模板的大小就不得不考虑。
不过,这还没完…特征选择之后需要进行特征提取,前面提到要和那9个字比较看最接近哪一个,那这把一张图片分成100份,怎么比啊?比什么啊?
首先,我们要明确的是,一张手写汉字图片上面的所有像素点的值,要么是黑(0),要么是白(255),那么要比较的东西肯定和这些像素点的值有关。本文对分出的这100个区域,计算黑色像素点占比,也就是黑色像素点的个数/总像素点个数,因此得到了100个介于0~1的小数。我们将其用100x1的向量表示,这个,就是图片的特征向量。如下图是我样本库中一个汉字的一个特征向量,为了方便将它展示为20x5的特征矩阵:

1.2 样本库设计
样本库设计分为9个类别,即分别代表“昆明理工大学信自院”这9个汉字,如下图所示:

每个汉字我们设置了5个学习样本,样本是利用系统的画图工具手写的汉字,也有使用MATLAB创建的手写面板(为了丰富报告搬过来的GUI),图片都为bmp格式,大小为120px*90px,学习样本图片如下图所示(内含标准样本图片):

这些字在我写的时候比较潦草,是为了丰富样本的笔迹,大家其实可以自己创建训练样本。当然如果需要识别大量的汉字,可以到网上自行查找脱机汉字手写库去使用。
有了样本图片,接下来是对每个样本的特征进行提取,本文是基于MATLAB进行实现,提取工作时所需数据结构如下:
- 所有的样本数据保存在一个templet.mat文件中;
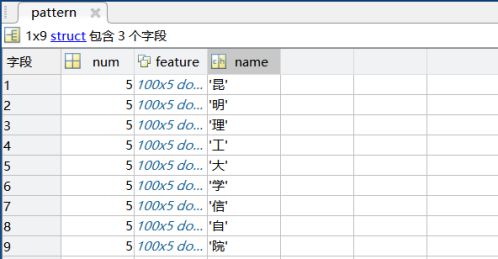
- 每一个汉字都使用一个结构体保存信息,因此需要一个长度为9的结构体数组pattern;
- 每个结构体中有变量
- num,表示该类手写汉字特征数量(即该汉字中样本的数量);
- feature,100*num的特征矩阵(即num个样本就有num个100x1的特征向量,上文已经说明);
- name,示该汉字代表的汉字字符。
提取特征代码和效果如下:
function sampleTraining(cla,fea,dataSet)
%学习单个样本特征
%cla表示第几个类即汉字个数,fea表示第几个特征即特征向量,dataSet为学习的字符集
%每个样本图片被分成10*10=100个cell
%需要注意图片的的长和宽都需被定义成10的倍数,因为后面要被10除
clc; %清屏
load templet pattern; %加载汉字特征
A=imread(['C:\Users\Hubery\Desktop\File\Hubery\大作业\测试\样本集\',dataSet(cla),num2str(fea),'.bmp']);
figure(1),imshow(A) %显示读取的手写灰度图
B=zeros(1,900); %创建1列100行的数组
pattern(cla).feature(:,fea)=zeros(900,1); %初始化当前类的第fea个初始化特征向量
[row col] = size(A); %获取样本图片的行列
cellRow = row/30; %除以10得到1/100的小格子
cellCol = col/30;
count = 0; %每1/100个格子中为0的像素点个数
currentCell = 1; %当前计算为第1个1/100格子部分
for currentRow = 0:29
for currentCol = 0:29
for i = 1:cellRow %计算每1/100部分中为0的数量
for j = 1:cellCol
if(A(currentRow*cellRow+i,currentCol*cellCol+j)==0)
count=count+1;
end
end
end
ratio = count/(cellRow*cellCol); %计算1/100部分中黑色像素的占比
B(1,currentCell) = ratio; %将每个占比统计在B特征向量中
currentCell = currentCell+1; %新的1/100部分开始计算
count = 0; %像素点计数置0
end
end
pattern(cla).num=5; %类的特征数量(feature中的列数)
pattern(cla).name=dataSet(cla); %当前类代表的汉字字符
pattern(cla).feature(:,fea)=B'; %当前类第fea列特征向量
save templet pattern %保存学习样本的汉字特征
function studyData()
%自动学习所有训练样本集
%通过循环对每一个学习样本调用学习函数
load templet pattern; %清空学习特征
dataSet = '昆明理工大学信自院'; %学习的字符集
for i = 1:9 %9个汉字
for j = 1:5 %每个汉字需要5个特征向量即5个样本集
sampleTraining(i,j,dataSet); %循环学习样本集
end
end
提取之后,pattern数组获取了所有汉字的特征信息:
至此,整个特征选择和提取的过程,才算结束,接下来是分类器设计,分类器通过对这些汉字的特征进行处理和比较,对待识别对象进行分类,得到识别出来的汉字结果。
2.分类器设计
2.1贝叶斯公式
直接上公式8:
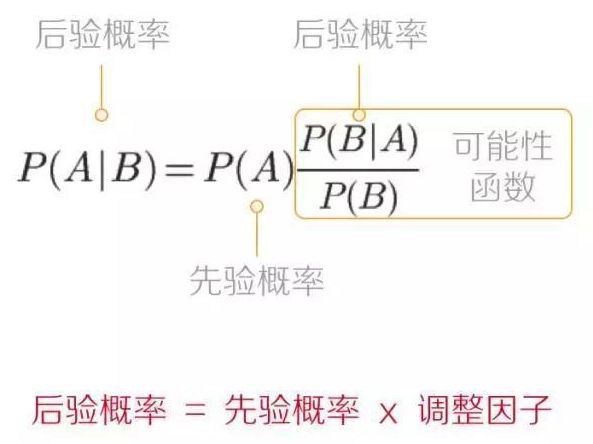
所谓先验概率就是根据已有的知识和经验的出的概率分布,即此事发生的概率,多为均匀分布。后验概率是指经过一些后天的实际观测统计后,得到的概率。换句话说,先验概率是事情还没发生之前计算的可能性大小,后验概率可以认为求事情发生的原因是由某个因素引起的可能性大小。
2.2分类器设计过程
~~~~ ~~~ 贝叶斯公式和现拥有的特征数据如何建立联系?

在特征情况为待测对象X状态时,不同汉字类别 ω的后验概率最大,即属于该类别。
- 先验概率P(ωi) 由各类样品数和样品总数近似计算,Ni为汉字i的样品数,N为样品总数:
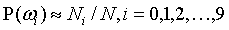
- 计算Pj(ωi),再计算类条件概率P(X|ωi)

其中i=0,1,2,…,9,j=0,1,2,…,99。在此设置阈值为0.05,当这100个特征分量的值大于0.05时,认为特征值取1,否则取0。Pj(ωi)表样品X(x0,x1,x2,…,x99)属于ωi类条件下,待测对象X的第j个分量为1(xj=1)的概率估计值。由此可以计算

其中i=0,1,2,…,9,j=0,1,2,…,99。我们不妨这样理解,假设X不论属于哪一类汉字,这些类的所有样品特征中,第一个分量即第一个1/100格子的概率值都为0,那么可以认为X的特征值也一定为0,取反的概率下才为1。贝叶斯注重样本是固定的,频率是随机的,根据样本来影响后验概率。因此,待测对象X的类条件概率为

其中i=0,1,2,…,9,a=0或1。 - 应用贝叶斯公式求后验概率,即待测对象X属于ωi的可能性,得
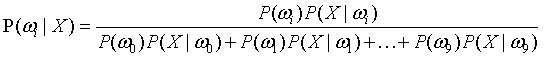
其中i=0,1,2,…,9,P(X)的大小就是上式分母中,所有X属于不同类别的情况相加得到的和。 - 计算得到后验概率的最大值的类别,就是手写汉字所属的类别。
2.3分类器代码实现
分类器设计:
function y = bayesBinary(sample)
%基于概率统计的贝叶斯分类器
%sample为要识别的图片的特征(1列100行的概率)
clc; %清屏
load templet pattern; %加载汉字特征
sum = 0; %初始化sum
prior = []; %先验概率
p = []; %各类别代表点
likelihood = []; %类条件概率
pwx = []; %贝叶斯概率
%%计算先验概率
for i=1:9
sum = sum+pattern(i).num; %特征总数
end
for i=1:9
prior(i) = pattern(i).num/sum; %出现每个汉字的可能性(先验概率)
end
%%计算类条件概率
for i=1:9 %9个汉字
for j=1:100 %100个模块
sum = 0;
for k=1:pattern(i).num %特征数
if(pattern(i).feature(j,k)>0.05) %概率大于阈值0.05则数量+1
sum = sum+1;
end
end
p(j,i) = (sum+1)/(pattern(i).num+2);%计算概率估计值即Pj(ωi),注意拉普拉斯平滑处理
end
end
for i=1:9
sum = 1;
for j=1:100
if(sample(j)>0.05)
sum = sum*p(j,i);%如果待测图片当前概率大于0.05认为特征值为1,直接乘Pj(ωi)
else
sum = sum*(1-p(j,i));%如果待测图片当前概率小于0.05认为特征值为0,乘(1-Pj(ωi))
end
end
likelihood(i) = sum; %将类条件概率赋值给likelihood
end
%%计算后验概率
sum = 0;
for i=1:9
sum = sum+prior(i)*likelihood(i); %求和即得P(X)
end
for i=1:9
pwx(i) = prior(i)*likelihood(i)/sum; %贝叶斯公式
end
[maxval maxpos] = max(pwx); %计算最大值和其所在位置
y=maxpos; %返回类的下标即汉字的类号
测试:
function bayesBinaryTest()
%利用贝叶斯分类器对手写图片识别
load templet; %加载汉字特征
%A = imp; %得到待识别图片
A=imread('C:\Users\Hubery\Desktop\File\Hubery\大作业\测试\样本集\昆.bmp');%待测图片
figure(1),subplot(121),imshow(A),title(['待识别的汉字:']);
B=zeros(1,100); %创建1列100行的特征向量
[row col] = size(A); %得到待测样本的行列
cellRow = row/10; %将其降维10x10的特征图片
cellCol = col/10;
count = 0; %每1/100个格子中为0的像素点个数
currentCell = 1; %当前计算为第1个1/100格子部分
for currentRow = 0:9
for currentCol = 0:9
for i = 1:cellRow %计算每1/100部分中为0的数量
for j = 1:cellCol
if(A(currentRow*cellRow+i,currentCol*cellCol+j)==0)
count=count+1;
end
end
end
ratio = count/(cellRow*cellCol); %计算1/100部分中黑色像素的占比
B(1,currentCell) = ratio; %将每个占比统计在B特征向量中
currentCell = currentCell+1; %新的1/100部分开始计算
count = 0; %像素点计数置0
end
end
class = bayesBinary(B'); %将该特征利用贝叶斯分类器分类,返回类的个数
subplot(122),imshow(['C:\Users\Hubery\Desktop\File\Hubery\大作业\测试\样本集\',num2str(class),'.jpg']),title(['该汉字被识别为:']);
disp(['该汉字被识别为:',pattern(class).name]);
总结
由于方法的简单原始以及样本集不够丰富等原因,本程序的识别精确度主要受图片中字体的位置、大小的限制。由于特征提取的方法,请尽量保证学习样本和测试样本图片大小等同。以上程序代码和样本集已经上传到github:
https://github.com/HuberyIsAHero/BayesBinaryHandwritingRecognition_BC_20190220
- 除了以上的程序外,并搬运了现成的GUI,所以程序直接启动GUI即可,但要根据情况更改每个m函数中地址。
- 如本文或程序有问题请不吝指正,谢谢~
- 参考文献:杨淑莹. 模式识别与之智能计算—Matlab技术实现. 电子工业出版社, 2008,1