深度学习笔记之基于InceptionV3架构的深度学习方法进行肺炎诊断
前言
X线胸片,通俗地被称为“拍片”,也列为常规体检的检查项目之一。X线摄影的快捷、简便、经济的优势日渐突出,成为胸部检查的优先选择。X线胸片能清晰地记录肺部的大体病变,如肺部炎症、肿块、结核等,利用人体组织的不同密度可观察到厚度和密度差别较小部位的病变。
肺炎是由感染性病原体引起的肺组织炎症和实变,在X线胸片上可见双肺斑片状阴影,阴影模糊不清,双肺呈毛玻璃状;传统的阅片方式为医生人工查看,凭借经验进行判断。但根据相关研究表明:中国每年医学影像增速达到了30%,而放射科医生的年增长率仅为4.1%, 远远低于影像数据的增长,需求缺口不断加大,医生数量的不足导致工作量繁重,超负荷工作也会导致误诊率和漏诊率提高。同时个体差异较大。医生阅片能力的高低严重依赖个人经验。
为了解决该问题,可提出由图片识别模型(深度学习方法)完成初步筛选、判断.交由医生完成最后判断。人工智能能够快速完成初筛,交由医生进行判断,能够大幅缩短医生阅片时间。其优点在于一张图片医生会根据经验挑重点可疑区域来现察.而机器可以完整地观察整张切片而无遗漏; 稳定性。机器不需要休息,不会受到疲劳状态影响。其诊断结果能保持完全的客观、稳定和复现。
数据情况
两个文件夹代表两个分类,正常(上)和患有肺炎(下),图片大小不一,格式均为为jpeg。
操作步骤
1.同样是在colab上进行深度学习训练,需要对谷歌云盘进行挂载,并移动当前位置到数据目录下:
from google.colab import drive
drive.mount("/content/gdrive")
# 必要时可重启kernal
import os
os.kill(os.getpid(), 9)
import os
path = "/content/gdrive/My Drive/chest_xray/"
os.chdir(path)
os.listdir(path)
2.导入所有标准库
# 导入所有标准库
import glob
# glob库用于查找符合特定规则的文件路径名,"*"匹配0个或多个字符;"?"匹配单个字符;"[]"匹配指定范围内的字符,如:[0-9]匹配数字
import numpy as np
import cv2
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
from keras import utils,losses,optimizers
from keras.models import Sequential
from keras.layers.core import Dense ,Dropout,Activation,Flatten,Lambda
from keras.layers import Input,BatchNormalization
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping,ModelCheckpoint
from keras.layers import Conv2D ,MaxPooling2D,GlobalAveragePooling2D
from keras.models import Model
import skimage
from skimage.transform import resize
SEED=2019
img_size=224
3.加载图片名并输出训练集,测试集肺炎和正常类别数据量的大小:
DATA_DIR_train='/content/gdrive/My Drive/chest_xray/train/'
PNEUMONIA_train=glob.glob(DATA_DIR_train+"PNEUMONIA/*.jpeg")
NORMAL_train=glob.glob(DATA_DIR_train+"NORMAL/*.jpeg")
print("num of PNEUMONIA_train:{} ; num of NORMAL_train:{}".format(len(PNEUMONIA_train),len(NORMAL_train)))
# 测试集
DATA_DIR_val='/content/gdrive/My Drive/chest_xray/test/'
PNEUMONIA_val=glob.glob(DATA_DIR_val+"PNEUMONIA/*.jpeg")
NORMAL_val=glob.glob(DATA_DIR_val+"NORMAL/*.jpeg")
print("num of PNEUMONIA_val:{} ; num of NORMAL_val:{}".format(len(PNEUMONIA_val),len(NORMAL_val)))
4.为实现“无限次”批量读入数据,创建python生成器,批量读入图片数据
# 批量读入训练数据
def batchgen(PNEUMONIA,NORMAL,batch_size,img_size=img_size):
batch_images=np.zeros((batch_size,img_size,img_size,3)) # 初始化数组
batch_label=np.zeros(batch_size)
while 1:
n=0
while n < batch_size:
if np.random.randint(2)==1:
i = np.random.randint(len(PNEUMONIA))
img=cv2.imread(PNEUMONIA[i],cv2.IMREAD_GRAYSCALE)
if img is None:
break
img = skimage.transform.resize(img, (img_size,img_size, 3))
# img = img.astype(np.float32)/255.
img = np.asarray(img)
# 图像具有不同的大小,将其全部整到image_size*image_size
y = 1
else:
i = np.random.randint(len(NORMAL))
img=cv2.imread(NORMAL[i],cv2.IMREAD_GRAYSCALE)
if img is None:
break
img = skimage.transform.resize(img, (img_size,img_size, 3))
# img = img.astype(np.float32)/255.
img = np.asarray(img)
y = 0
batch_images[n]=img
batch_label[n]=y
n+=1
yield batch_images,batch_label # 生成器
5.加载InceptionV3架构,定义loss,优化器以及评价指标
# 利用imageNet的VGG16进行迁移学习
# 加载模型
# from keras.applications.vgg16 import VGG16
from keras.applications.inception_v3 import InceptionV3
# from keras.applications.inception_resnet_v2 import InceptionResNetV2
base_model = InceptionV3(weights='imagenet', include_top=False,input_shape = (img_size, img_size, 3))
#print(base_model.output_shape) # 模型输出,(batch_size,3,3,512)
#print(base_model.summary())
#print(base_model.output_shape)
# 自定义全连接部分
user_defined = base_model.output
user_defined = Dropout(0.5)(user_defined)
user_defined = GlobalAveragePooling2D()(user_defined)
user_defined = Dense(1024, activation='relu')(user_defined)
user_defined = BatchNormalization()(user_defined)
user_defined = Dense(1, activation='sigmoid')(user_defined)
'''
user_defined = BatchNormalization()(user_defined)
user_defined = Conv2D(64,(5,5),activation='relu')(user_defined)
user_defined = MaxPooling2D(pool_size=(2,2))(user_defined)
user_defined = Flatten()(user_defined)
# user_defined = Flatten(input_shape=base_model.output_shape[1:])(base_model.output)
user_defined = Dropout(0.5)(user_defined )
user_defined = Dense(1024,activation='relu')(user_defined)
user_defined = Dropout(0.5)(user_defined)
user_defined = Dense(1,activation='sigmoid')(user_defined)
'''
# 串联
model = Model(input=base_model.input, output=user_defined)
#for layer in base_model.layers:
#layer.trainable = False
print(model.summary())
''''''
#model=create_model(init_type='glorot_normal')
# 编译模型,loss,优化器,评价指标
model.compile(loss="binary_crossentropy",
optimizer=optimizers.Adam(lr=0.0001),
metrics=['binary_accuracy'])
6.训练模型
# 此处训练用fit_generator而非fit,因为输入数据为生成器,返回history对象,记录了运行输出
# History类对象包含两个属性,分别为epoch和history,epoch为训练轮数;根据compile参数metrics,history属性包含不同的内容(字典形式表示)
history=model.fit_generator( aug.flow(next(train_generator)),
epochs=n_epochs,
validation_steps=1,
steps_per_epoch=steps_per_epoch,
validation_data=val_generator,
callbacks=callbacks)
训练结果如下:
似乎有点过拟合,可能是因为训练样本的不足(3964幅肺炎胸片及 1440幅正常肺胸片)所导致的,尽管做了数据增强(白化,平移,剪切)

7.评价模型
# 取出所有测试集图片进行预测分类
DATA_DIR_val='/content/gdrive/My Drive/chest_xray/test/'
PNEUMONIA_val=glob.glob(DATA_DIR_val+"PNEUMONIA/*.jpeg")
NORMAL_val=glob.glob(DATA_DIR_val+"NORMAL/*.jpeg")
sample_size1=len(PNEUMONIA_val)
sample_size2=len(NORMAL_val)
print(sample_size1,sample_size2)
def AllSamples(PNEUMONIA,NORMAL,sample_size1,sample_size2,img_size=img_size):
images=np.zeros((sample_size1+sample_size2,img_size,img_size,3)) # 初始化数组
label=np.zeros(sample_size1+sample_size2)
for i in range(sample_size1):
img=cv2.imread(PNEUMONIA[i],cv2.IMREAD_GRAYSCALE)
if img is None:
break
img = skimage.transform.resize(img, (img_size,img_size, 3))
img = np.asarray(img)
# 图像具有不同的大小,将其全部整到image_size*image_size
y = 1
images[i]=img
label[i]=y
for i in range(sample_size2):
img=cv2.imread(NORMAL[i],cv2.IMREAD_GRAYSCALE)
if img is None:
break
img = skimage.transform.resize(img, (img_size,img_size, 3))
img = np.asarray(img)
y = 0
images[sample_size1+i]=img
label[sample_size1+i]=y
return images,label.reshape([-1,1])
test_image ,test_label =AllSamples(PNEUMONIA_val,NORMAL_val,sample_size1,sample_size2,img_size=img_size)
print(test_image.shape ,test_label.shape)
from sklearn.metrics import confusion_matrix
pred = model.predict(test_image)
# pred = np.argmax(pred,axis = 1)
y_true =test_label
# 制作混淆矩阵,并计算精度和召回率
cm = confusion_matrix(y_true, np.around(pred))
from mlxtend.plotting import plot_confusion_matrix
fig, ax = plot_confusion_matrix(conf_mat=cm , figsize=(5, 5))
plt.show()
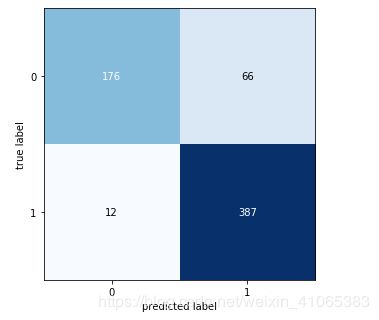
tn, fp, fn, tp = cm.ravel()
precision = tp/(tp+fp)
recall = tp/(tp+fn)
print("Recall of the model is {:.2f}".format(recall))
print("Precision of the model is {:.2f}".format(precision))
Recall of the model is 0.97
Precision of the model is 0.85
可以看得到召回率达0.97,精度达0.85,模型还有待进一步提高,如何让它特征提取更强大、分类更准确、速度更快,从网络结构、loss function、activation function等入手,还是基于已有的其他架构,用已有的优秀的神经网络算法,侧重于研究解决专业领域(如上面所讨论的肺炎诊断)问题的框架,当然很多时候需要对已有的算法做些微调,当然数据质量也是建模很重要的一点,数据量少也是这次建模效果一般的重要因素之一。