中文实体关系抽取实践
前言
本篇博客主要讲NLP中的关系抽取,聚焦点中文,没有过多理论,侧重实践(监督学习)。
关于实体关系抽取的技术发展脉络,感兴趣的可以看一下:
https://www.cnblogs.com/theodoric008/p/7874373.html
关系抽取有限定关系抽取和开放关系抽取,这里主要说限定关系抽取即分类问题
其过程常常又有监督学习和半监督学习,这里主要讲利用深度学习进行的监督学习,关于半监督学习可以使用deepdive
感兴趣的可以看笔者的另一篇博客:
https://blog.csdn.net/weixin_42001089/article/details/91388707
另外有的场景没有给定实体对,需要联合抽取实体关系,这里也有一个例子是基于bert模型的,笔者进行了解读,感兴趣的可以看下:
https://blog.csdn.net/weixin_42001089/article/details/97657149

本篇全部代码:
https://github.com/Mryangkaitong/Chinese_NRE
数据
数据集简介
1. 数据来源
本次评测数据主要来源于互联网网页文本,其中验证集和测试集是通过人工进行标注的,而训练集是通过远程监督(Distant Supervision)自动生成的。
2. 数据集信息
在数据发布阶段,我们发布训练集、开发集和用于参赛者测试的测试集。总共有34类人物关系,包括一类特殊关系NA,具体见文件relation2id.txt。
3. 数据格式说明
训练集&验证集
各由三个数据文件组成,各数据文件格式如下:
sent_train/dev:sentID sentence
bag_relation_train/dev:bagID e1 e2 sentIDs relationIDs
sent_relation_train/dev:sentID relationIDs
测试集
由三个数据文件组成,其中bag_relation_test为Bag-Track的测试集,sent_relation_test为Sent-Track的测试集,各数据文件格式如下:
sent_test:sentID sentence
bag_relation_test:bagID e1 e2 sentIDs
sent_relation_test:sentID
字段说明:
- sentID为一个实体对和包含该实体对句子的唯一ID。
- sentence为一个实体对和包含该实体对的句子有序组合,实体对之间、实体对和句子之间以“ ”隔开,句子以对应句子分词结果的形式给出,该分词结果仅做参考,参赛者可视情况使用。
- bagID为实例所属包的ID,同一个包中的实例具有相同的实体对。
- e1、e2为给定的人物实体对中的头实体和尾实体。
- sentIDs为包中的句子ID集合,每个ID之间以单个空格隔开。
- relationIDs为包的标签关系ID集合,每个ID之间以单个空格隔开,每个关系的ID见文件relation2id.txt。
评价方式
关系抽取(Relation Extraction)是信息抽取的一个重要子任务,其任务是从文本内容中找出给定实体对之间的语义关系,是智能问答、信息检索等智能应用的重要基础,和知识图谱的构建有着密切的联系。在本次任务中,我们重点关注人物之间的关系抽取研究,简称IPRE(Inter-Personal Relationship Extraction)。给定一组人物实体对和包含该实体对的句子,找出给定实体对在已知关系表中的关系。我们将从以下两个方面进行评测:
1. Sent-Track:从句子级别上根据给定句子预测给定人物实体对的关系
输入:一组人物实体对和包含该实体对的一个句子
输出:该人物实体对的关系
样例一:
输入:贾玲 冯巩 贾玲,80后相声新秀,师承中国著名相声表演艺术家冯巩。
输出:人物关系/师生关系/老师
2. Bag-Track:从包级别上根据给定句子集合预测给定人物实体对的关系
输入:一组人物实体对和包含该实体对的若干句子
输出:该人物实体对的关系
样例二:
输入:
- 袁汤 袁安 从袁安起,几代位列三公(司徒、司空、太尉),出过诸如袁汤、袁绍、袁术等历史上著名人物。
- 袁汤 袁安 袁汤(公元67年—153年),字仲河,河南汝阳(今河南商水西南人,名臣袁安之孙,其家族为东汉时期的汝南袁氏。
输出:
袁汤 袁安 人物关系/亲属关系/血亲/自然血亲/祖父母/爷爷 NA
说明:若有多个关系,则输出多个关系。
Sent-Track任务
选手将结果保存为result_sent.txt,以utf-8编码格式保存,按照sentID顺序,每行2列,以“ ”分隔,第一列为sentID,第二列为该实例实体对关系的判断结果的ID,即“sentID relationIDs”。若为多个关系,则每个关系ID之间以单个空格隔开。
Bag-Track任务
选手将结果保存为result_bag.txt,以utf-8编码格式保存,按照bagID顺序,每行2列,以“ ”分隔,第一列为bagID,第二列为该实体对的关系ID,即“bagID relationIDs”。若为多个关系,则每个关系ID之间以单个空格隔开。
最终提交文件要求:
每一个参赛队需提交的材料如下:
1、测试集预测结果文件,分别用result_sent.txt和result_bag.txt命名(UTF-8格式)
2、代码及说明
3、方法描述文档(非评测论文,评测论文撰写要求见CCKS 2019官网)。
以上三个文件需在任务提交截止日期后一周内发送至邮箱:王海涛
代码及其文档需打包成一个文件(tar,zip,gzip,rar等均可),用code.xxx命名,要求提交所有的程序代码及相关的配置说明,程序应当可以运行且所得结果与result_sent.txt和result_bag.txt相符
评测平台:本次评测将依托biendata平台(https://biendata.com/)展开,请有意向的参赛队伍关注平台上的竞赛列表。
评价指标
本次任务的评价指标包括精确率(Precision, P)、召回率(Recall, R)和F1值(F1-measure, F1),分为 Sent-Track 和 Bag-Track 两个部分,每部分按F1值分别排名。只统计预测结果中非NA的数目(如果NA关系预测错误,也会计入到评价指标中计算)。
1. Sent-Track预测结果评价:
给定测试集结果,![]() 表示类别预测正确的句子数目,
表示类别预测正确的句子数目,![]() 表示系统预测的句子数目,
表示系统预测的句子数目,![]() 表示标准结果的句子数目。
表示标准结果的句子数目。
计算公式如下:

2. Bag-Track预测结果评价:
给定测试结果,![]() 表示类别预测正确的包的数目,
表示类别预测正确的包的数目,![]() 表示系统预测的包的数目,
表示系统预测的包的数目,![]() 表示标准结果的包的数目。
表示标准结果的包的数目。
计算公式如下:
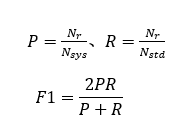
实践
该实践部分分为三大部分
第一部分主要是使用OpenNRE,这是清华开源的关系抽取API:
https://github.com/thunlp/OpenNRE
但是其目前只实现了bag方式的单标签,没有实现多标签,且没有sent方式,不过现在好像正在开发,大家可以期待,对其感兴趣的同学可以关注:
https://github.com/thunlp/OpenNRE/tree/nrekit
所以准确来说,OpenNRE并不适用该比赛,且其源码中在计算loss的时候使用了sigmoid,对于本赛题的sent方式也不适合,相反我们希望使用softmax,但是有人提出这也是一个技巧,虽然我们是多分类单标签但通过使用sigmoid可以消除类间干扰,说是这么说,直接实践看结果吧,在第二部分实践会看到
鉴于以上,为了进一步展示bag方式(多标签)和sent这种形式,这里会结合比赛的给出的baseline的代码进行实践,补充实现pcnn,rnn,cnn(目前只有sentences)等,同时恰好看到一个相关的别的比赛的答辩视频,其中提到过一些技术,这里也会结合的实现一下
baseline:https://github.com/ccks2019-ipre/baseline
还有就是GRU,其官方对比效果好于OpenNRE
https://github.com/squirrel1982/TensorFlow-NRE
这也是本篇主要参考几篇资料,第一部分和第三部分在该比赛中效果不好,这里之所以讲主要目的就是介绍一下其使用流程,以便有需要的场合使用,可以略过一三,直接看第二部分
第一部分相关的实践因为其只能处理单标签,这里就用sent的数据
统计了一下类别数量(sent):
训练集上面:
0 248850
1 8135
10 6870
4 5513
33 2900
12 2627
16 1673
30 1610
11 1383
31 1301
32 1266
13 830
19 805
17 637
34 547
18 532
7 291
5 245
2 218
3 183
29 165
23 158
26 119
21 77
20 77
6 69
27 67
14 46
8 40
24 30
28 24
22 22
15 19
25 13
9 9
测试集上面:
0 37332
10 247
1 218
4 125
12 88
32 72
11 65
33 62
13 43
31 27
16 27
6 16
17 11
2 11
22 11
19 9
7 9
30 6
3 5
34 5
14 4
18 4
5 3
9 3
15 2
24 2
29 2
27 1
25 1
28 1
8 1
21 1
23 1
26 1
20 1第一部分
OpenNRE需要训练好的词向量,所以我们首先训练词向量
训练词向量
这里使用了jieba进行分词,gensim框架进行训练,
过程是首先是生成语料库corpus.txt,最后生成word2vec.txt
两则都保存在当前文件夹
运行如下即可
Python word2vec_train.py转化成json文件
因为OpenNRE的输入文件要求是json文件格式,所以这里简单写了个脚本进行转化成要求的json格式
OpenNRE是需要实体id的,这里转化的过程中一个是将句子id+_0和句子id+_1作为实体对的id
另一个是是使用实体字典作为id,看起来后者更符合逻辑,但是预测结果就会丢失句子信息,即属于同一实体对的所有句子都是一个预测结果
运行完后会在data文件夹下产5个相应的json文件
rel2id.json , word_vec.json,train.json , dev json ,test.json
如果采用后者会多产生一个
sent_id_dict.json
其中sent_id_dict.json的的形式是19#34:['TEST_SENT_ID_027274','TEST_SENT_ID_027275']用于后续预测结果映射
运行如下即可
python txt2json.pyOpenNRE修改部分
下载上述给的github,解压得到OpenNRE-master,后面就直接使用啦
在直接调用API之前,需要做以下工作
dev/test问题:
OpenNRE给的demo中有train和test两个数据集,而我们这里有3个数据集,train,dev,test,其中train和dev对应OpenNRE demo
中的train,test而我们这里的test是没有label的,所以做以下工作:
首先在OpenNRE-master下创建文件夹 data/people_relation/ (这里将项目命名为人物关系)
然后将上述生成的train.json , rel2id.json , word_vec.json放进来
将dev.json重命名为test.json放进来
将test.json重命名为test_submit.json放进来
为了使test_submit.json也能够生成对应的npy文件(至于为什么要生成npy?可以下面的“其他说明”部分),在train.demo中加上:
test_loader_submit = nrekit.data_loader.json_file_data_loader(os.path.join(dataset_dir, 'test_submit.json'),
os.path.join(dataset_dir, 'word_vec.json'),
os.path.join(dataset_dir, 'rel2id.json'),
mode=nrekit.data_loader.json_file_data_loader.MODE_ENTPAIR_BAG,
shuffle=False)同样,test_demo.py中对应的改成:test_submit

另外预测结果时用到的是主要是OpenNRE/nrekit/framework.py / 下的__test_bag__函数的如下部分

主要是计算auc,这里的relfact_tot是指的关系数(不包括NA),因为作者的源码的test相当于dev是有标签的所有可以统计auc,但是我们的test是没有标签的,也没有必要知道这些指标,我们想要的只有结果,同时我们上面将txt转化为json的过程中将test中的所有关系都设置为了NA,所以当输入是test_submit时这里的relfact_tot就是0,会报错的,于是乎可以改成这样:

如果是test_submit,就将指标都设置为0,反正也不需要,而且也不可能知道
python版本带来的问题:
test_demo.py在将预测结果写入json文件时,如果使用的是Python3.6,使用json.dump将结果写入文件时会出错,改用ujson
首先导入ujson
import ujson然后对应部分改为
ujson.dump(pred_result, outfile)词向量维度:
上述我们的word_vec.json词向量是300维
那么对应到这里源码需要改一下即OpenNRE/nrekit/network/embedding.py /下第29行的word_position_embedding函数中将word_embedding_dim改为300

测试模型参数太多问题:
在运行到epoch=3的时候会突然报错:

这是因为在测试的时候每次都要重新生成一个Model,对应到tensorflow里面的话,张量就会越来越多,到最后就会溢出,为此这里我们就需要做一点改进,那就是判断一下之前是否已经有模型存在,存在的话直接加载就好啦
修改OpenNRE/nrekit/framework.py /,在107行加上,给类re_framework的初始化中加一个属性
self.test_model = None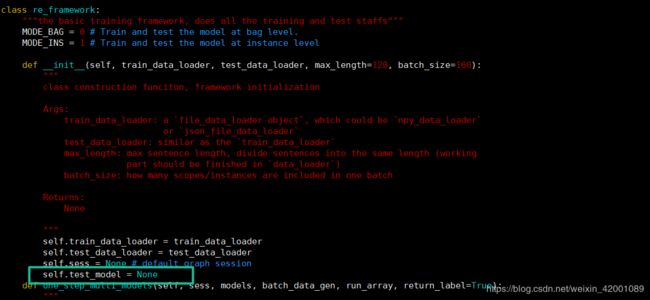
然后在 __test_bag__方法下将源码中的
model = model(self.test_data_loader, self.test_data_loader.batch_size, self.test_data_loader.max_length)改为

为了其进一步能够处理这种异常我们train方法下(283行)加上:

这样的话即使再出错,也可以在当前截止,使程序顺利结束,保存好已经训练过的模型
F1指标:
在训练的时候log给出的是准确率信息,没有f1相关的输出,这里我们顺便计算一下f1,并实时输出
在__test_bag__方法中修改:(至于为什么要这么写可参考OpenNRE/draw_plot.py中f1的计算)

同理,源码中模型是否保存的基准是auc,这里我们也替换成f1

所以,对应的test_demo.py中,这里返回的也是f1(改一下名字而已)

batch_size和max_length的设置:
原来的设置是batch_size=160,max_length=120
这里改为batch_size=128,max_length=60
具体需要修改的位置就是OpenNRE/nrekit/data_loader.py /下的
npy_data_loader和json_file_data_loader这两个类的初始化
以及OpenNRE/nrekit/framework.py /下的re_model和re_model类的初始化
和train_demo.py/test_demo.py下的相关位置例如:
画图
有的时候,效果很差,所以在draw_plot.py 绘制准确率的时候,这里还是改成从0开始吧,否则看不到结果
Selector的Maximum
源码中已经将max模型改为one,所以以后想要用在selector模式中用max,改用one就行
除此之外,对应的test_demo.py中要将如下部分

改为对应的:

---------------------------------------------------------------------------------------------------------------------------------------------------------------
训练:
这是OpenNRE给的在NYT10上面的运行结果
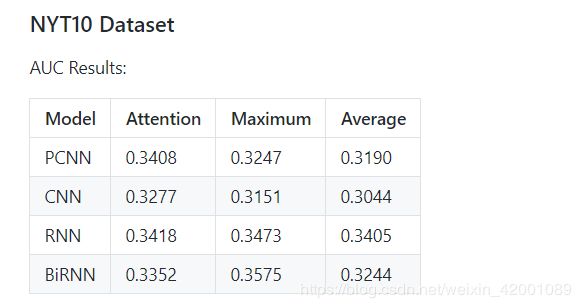
为此这里我们先来运行一下BiRNN+ Maximum模型组合
注意代码中Maximum对应的是one
python train_demo.py people_relation birnn one因为时间较长,这里就后台运行吧
nohup python -u train_demo.py people_relation birnn one > output.log 2>&1 &这里运行了15个epoch
性能
运行
python draw_plot.py people_relation_birnn_one
![]()
test_result下面会生成相应的图片

可以看到结果很差
预测
运行
python test_demo.py people_relation birnn one上述运行完会在text_result文件夹下生成相应的预测结果即people_relation_birnn_one_pred.json
转化成txt
结果生成的是json,因上述比赛,这里对应写了一个转化脚本
运行
python json2txt.py people_relation_birnn_one
即可在text_result文件夹下生成result_sent.txt
这里说明一下,模型生成的json文件是各个类别的分数,注意这里不是概率,因为其用的是softmax,且没有NA的概率,所以这里转化的时候如果各个类别(这里是34种)之间分数差别太小(小于1e-5)就认为是0,没有判别出来,否则就去最大分数的类别作为最后类别,关于该问题详细看后面的“其他说明”部分
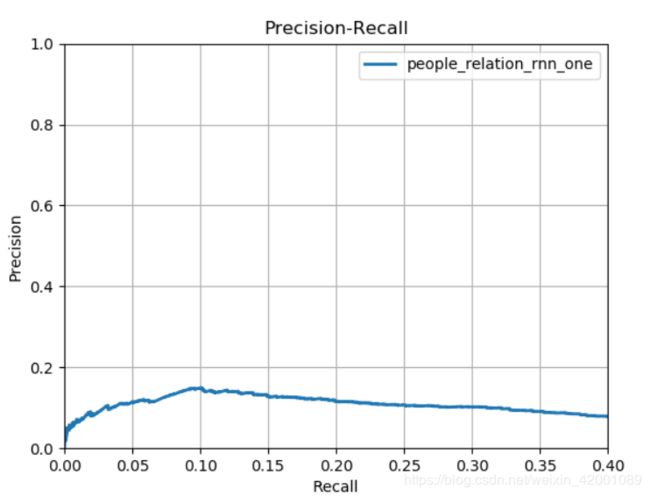
已经运行的部分结果
rnn+one:
![]()
pcnn+att:

pcnn+att:(单词做为id)
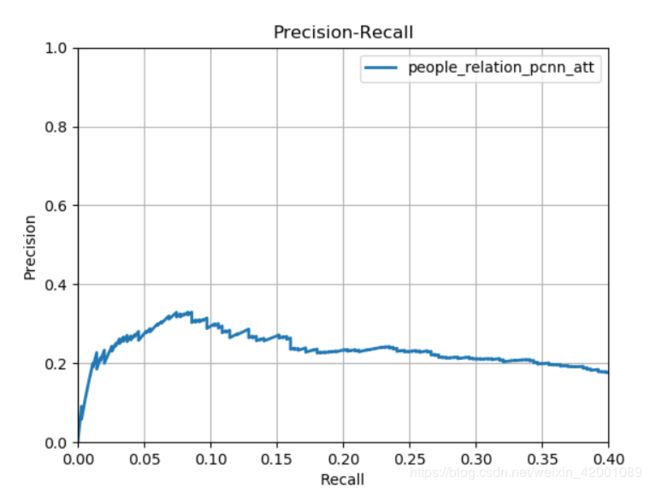
其他说明
一 :第一次运行的时候,需要所有的json文件,时间较长,加载的同时其会生成一个_processed_data文件夹
里面除了有我们原始的json文件外,还会有其对应预处理的.npy文件
![]()
假设之后需要用相同的数据重跑模型时,其会判断是否有_processed_data文件夹存在,如果存在就会使用np.load进行加载对应npy文件,而非加载json数据,这样做的目的就是加快了加载速度,经过试验加载json需要数个小时,而加载预处理对应的npy仅仅几秒。
二 :模型最后输出的是分数,其实内部源码用的是softmax,且没有NA的分数,按说应该用sigmoid比较好理解,关于这个问题的讨论作者也给出部分回答https://github.com/thunlp/OpenNRE/issues/96
三:在使用OpenNRE中进行预测后,通过转化为txt提交,线上效果很差,不知道什么原因?和这里的F1明显不一样,在转化的过程中是选取最大分数作为预测label的 ,这里需要说明:如果选用单词作为id,OpenNRE的结果是按照 head_id#tail_id 为实体对给出结果的,而不是按照句子id给出预测结果,也就是说如果一个实体对在多句话中出现,那么转化成txt的过程中是将所有句子都打标成预测的结果,这里是不是不太合理?
第二部分
该部分可以看做是OpenNRE的一个简化版本
部分说明
词向量部分:
这里既可以选择加载使用语料库预训练的词向量,也可以选择不使用,不使用的话那就初始化一个词向量矩阵,一同参与从头训练,其实就相当于使用训练集上面的样本当做语料库。
这里同时嵌入了bert模型,该模型目前较火,这里不做进一步介绍啦,网上很多,其关键核心就是句向量,相信很多同学都见过这样的解释,比如苹果一词在水果和手机环境下其实是不同的含义,以前的word2vec训练的一个词的词向量总是固定的,其不会因为语境的不同而不同,而bert就是弥补了这一点,其训练规程很复杂,所幸的是谷歌已经将训练的模型公布,我们可以直接调用,关于具体怎么调用,网上也很多,这里就给出一篇博客吧:
https://blog.csdn.net/zhylhy520/article/details/87615772
在具体使用的时候,要首先在后台开启其服务:
nohup bert-serving-start -model_dir ./nert_model/chinese_L-12_H-768_A-12 -num_worker=2 >> bert_output.log 2>&1 &可能有人这里会有疑问,就比如上述博客中的“中国”这个词,那么得到结果也不就是一个固定的词向量吗?是的,其实我们这里应该这样理解,bert这里并不是将“中国”看成是一个词而是一句话,其本身的定位就是句向量,当输入中国时,其认为中国就是一句话,那么结果对应的就是对中国这一句话的向量,可能这样理解会好一点!
那么其实在这里我们没有利用到bert句向量的优势,因为我们还是相当于得到一个个词的向量,相当于用了其经过大量训练的预模型,如果有好其他想法,可以试一下
因为该过程较慢,这里在train过程中提取后,会随便保存提取好的bert的句向量即在data文件夹下的bert_word2vec.json,后续再进行的时候就不必重新提取啦,直接使用load_bert_word2vec加载bert_word2vec.json就行
网络部分:
这里参考OpenNRE加入pcnn,rnn,birnn,后两个较简单
这里主要说一说pcnn是怎样具体实现的,其原理很简单就是根据两个实体将一句话分成左中右3段,然后分别进行进行最大池化,在代码的实现过程中,其是通过mask,即0,1,2,3对其进行编号(1,2,3是左中右,0代表补齐的部分),然后分段加100,然后整体进行池化,假设【左面+100,中,右面】,【左面,中+100,右面】,【左面,中,右面+100】,即对【【左面+100,中,右面】,【左面,中+100,右面】,【左面,中,右面+100】】进行最大池化,那么对于【左面+100,中,右面】相当于左面先天性的比中,右多出100,那么其实最大化相当于就是在左面进行了,同理【左面,中+100,右面】相当于就是在中间进行了,依次类推,最后得到3个向量那就是相当于分段在左中右进行了最大池化。
bag实现方式:
-------------------------
首先需要说明,假设我们的batch_size = 128
那么bag这种形式在网路过程中其实并不是batch_size = 128,举例来说self.embedding()的输出维度应该是
[batch_size,self.sen_len,self.word_dim+2*self.pos_dim]
对应到这里应该是[128,60,310],但是实际上是[377,60,310]
为什么呢?应该bag下一个样本可能有多个句子,代码中是将所有句子平铺,可想而知总数是大于128的,那么label的shape还是正常的[128,35],那么最后是怎么对应哪几句话属于一个bag呢?
那就是通过sen_num_batch字段,其内部记录了数量,假设样本如下:(前面代表句子,后面代表label)
[sentence_0,sentence_2,sentence_9 ] [0,1]
[sentence_8] [2]
[sentence_10,sentence_19] [6]
那么sen_num_batch中就是【0,3,4,6]即记录累加句子个数,平铺句子后是pat = 【sentence_0,sentence_2,sentence_9 ,sentence_8,sentence_10,sentence_19】
那么选取的时候,对应第一个bag就是pat[0:3]即pat[sen_num_batch[0]:sen_num_batch[1]],依次类推
当然对应的如果是sentence方式,这里的batch_size就一直是128啦
------------------------------------------------------------------------------------------------------------------------------------------
下面看一下bag具体的形式
所谓bag和sentences在实现上的不同,其实是在最后面,即在前面embedding(word2vec,bert等等)以及encoder(cnn,pcnn等等)流程都是一样的,只不过实际中bag方式下的batch_size可能要大一些
两者的正式区别是在经过上述过程后(self.sentence_reps就是上述过程的结果【self.batch_size,self.hidden_dim】)开始分道扬镳的,对应到代码中就是
bag_level和sentence_level两个分别处理的函数。
为了对比先来看下sentence_level
def sentence_level(self):
out = tf.matmul(self.sentence_reps, self.relation_embedding) + self.relation_embedding_b
self.probability = tf.nn.softmax(out, 1)
self.classifier_loss = tf.reduce_mean(
tf.reduce_sum(-tf.log(tf.clip_by_value(self.probability, 1.0e-10, 1.0)) * self.input_label, 1))很简单,这里就是通过self.relation_embedding(【self.hidden_dim, self.num_classes】即【300,35】)转化为[batch_size,self.num_classes],然后经过softmax就是结果shape就是【128,35】
下面来看下bag_level
def bag_level(self):
self.classifier_loss = 0.0
self.probability = []
if self.encoder=='pcnn':
hidden_dim_cur = self.hidden_dim*3
else:
hidden_dim_cur = self.hidden_dim
self.bag_sens = tf.compat.v1.placeholder(dtype=tf.int32, shape=[self.batch_size + 1], name='bag_sens')
self.att_A = tf.compat.v1.get_variable(name='att_A', shape=[hidden_dim_cur])
self.rel = tf.reshape(tf.transpose(self.relation_embedding), [self.num_classes, hidden_dim_cur])
for i in range(self.batch_size):
sen_reps = tf.reshape(self.sentence_reps[self.bag_sens[i]:self.bag_sens[i + 1]], [-1, hidden_dim_cur])
att_sen = tf.reshape(tf.multiply(sen_reps, self.att_A), [-1, hidden_dim_cur])
score = tf.matmul(self.rel, tf.transpose(att_sen))
alpha = tf.nn.softmax(score, 1)
bag_rep = tf.matmul(alpha, sen_reps)
out = tf.matmul(bag_rep, self.relation_embedding) + self.relation_embedding_b
prob = tf.reshape(tf.reduce_sum(tf.nn.softmax(out, 1) * tf.reshape(self.input_label[i], [-1, 1]), 0),
[self.num_classes])
self.probability.append(
tf.reshape(tf.reduce_sum(tf.nn.softmax(out, 1) * tf.linalg.tensor_diag([1.0] * (self.num_classes)), 1),
[-1, self.num_classes]))
self.classifier_loss += tf.reduce_sum(
-tf.log(tf.clip_by_value(prob, 1.0e-10, 1.0)) * tf.reshape(self.input_label[i], [-1]))
self.probability = tf.concat(axis=0, values=self.probability)
self.classifier_loss = self.classifier_loss / tf.cast(self.batch_size, tf.float32) 经过前面部分,self.sentence_reps的输出是【377,300】
这里for其实就是遍历每一个bag(batch),然后通过self.bag_sens(就是上述说的sen_num_batch)就可以得到当前bag中所有句子,假设
[sentence_0,sentence_2,sentence_9 ] [0,1]
那么后面tensor的shape依次是:
sen_reps [ 3, 300]
att_sen [ 3, 300]
score [35, 3]
alpha [35, 3]
bag_rep [ 35, 300]
out [ 35, 35]
self.probability是一列列表,每次append的是【1,35】,所以最后的shape是【128,35】
这里其实就是用了一个attention,说的高大上一点就是所谓的注意力机制,关于attention可以看一下这篇
https://blog.csdn.net/BVL10101111/article/details/78470716
对应上面博主所说的套路,我们这里的问题想将所有的的bag形状转化为[num_classes,hidden_dim]即将
sen_reps(shape多种多样,有可能是上面的【3,300】也有可能是【1,300】,【5,300】等等)转化为bag_rep(即同一转化为【35,300】)
这个就是博主说的attention解决的创建:
“你有kk个dd维的特征向量hi(i=1,2,...,k)hi(i=1,2,...,k)。现在你想整合这kk个特征向量的信息,变成一个向量h∗h∗(一般也是dd维)。”
这里的score就是打分,alpha就是score经过softmax后的权重,之后sen_reps通过乘以权重(tf.matmul(alpha, sen_reps))便得以转化为bag_rep形式
那么关键就是打分函数,这里是一个矩阵self.rel,其实就是self.relation_embedding矩阵
这里其实是[n,300] =>[n,35]=>[300,35]=>[35,35]=>取对角线得到[1,35]
一般attention逻辑来说是[n,300]=>[1,300]最后通过一个矩阵转化得到[1,35],
第二种:score是对每一句话打一个一个分数,
而第一种是采用了每一句话都对每一个类打一个分数[n,35],然后得到[35,300]相当于综合考虑了n句话得到了35类,每一类给与了300种分数,最后通过一个矩阵转化得到[35,35]取对角线得到[1,35]
------------------------------------------------------------------------------------------------------------------------------------------------------------------
以上就是两者的全过程,不论是bag形式还是sentences形式,经过上面的输出的预测结果self.probability都是【batch_size,num_classes】即【128,35】
之后再train,dev以及test函数中,对于bag和sentences形式也略有一点不同,但都是同一个套路,就看test中吧
if self.bag:
all_preds = all_probs
all_preds[all_probs > 0.9] = 1
all_preds[all_probs <= 0.9] = 0
else:
all_preds = np.eye(self.num_classes)[np.reshape(np.argmax(all_probs, 1), (-1))]如果是sentences方式就直接取35类中最大值为结果
如果是bag方式那就设置一个阈值,大于0.9的都认为是结果,当然啦这个阈值也是人为可以设定的
以下是部分运行结果(F1):
不使用经过text预训练的词向量 cnn : 线下bag 0.19 线上bag 0.16564
使用经过text预训练的词向量 cnn : 线下bag 0.312704 线上bag 0.33402 线下sent 0.21 线上sent 0.21387
使用bert句向量 cnn : 线下bag 0.33 线上bag 0.32057
使用经过text预训练的词向量 pcnn : 线上bag 0.30414
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
更新部分:
偶然发现天池上面一个已经结束的比赛,初赛是实体识别,复赛是关系抽取
https://tianchi.aliyun.com/competition/entrance/231687/introduction
答辩视频
https://tianchi.aliyun.com/course/video?spm=5176.12586971.1001.24.64ee6bac9hrJ88&liveId=40999
部分开源代码:
https://github.com/qrfaction/ruijin-kg-SuperGUTScode
https://github.com/search?q=%E7%91%9E%E9%87%91
首先归纳一下框架:
数据预处理部分:针对瑞金这个比赛,这里可以做的就是分句(滑动窗口),一般该部分可以努力的方向是数据增强
模型部分:大部分都采取了常见的birnn+attention,核心框架都是这个,只不过在其上面进行了部分改进
下面会使用答辩中提到的一些技巧来扩展我们第二部分的代码,进而看下在我们开头说的比赛上面效果,下面是笔者实验的部分结果结果(由于知道的比较晚,此时比赛已经结束了,没法进行线上验证了,下面仅给出线下分数):
一 input+双层birnn(lstm)+attention_1
首先是Q&A团队提到的
总体框架是:

Encoder部分主要就是birnn,看一下输入部分(Input):
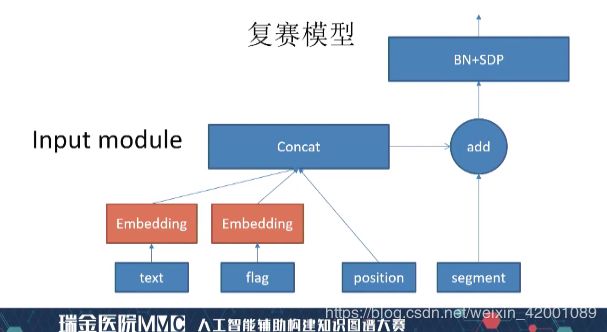
从这里可以看到多了flag和segment,其中flag是词性,segment是实体标示,第一个实体位置赋值0.1,第二个是-0.1,其余位置为0
这里笔者在具体复现的时候采用的是pyltp得到词性(笔者代码中的postagger和上图的flag是一个东西),实体位置标示改为1(没试过0.1的效果),然后经过birnn(单层GRU)+attention_1得到输出
这里所谓的attention_1指的是打分机制使用的是原text
![]()
相比于之前大概提升了4个百分点
二 input+单层birnn(gru)+attention_1
sent方式线下:![]()
这里将birnn部分换成了单层的GRU
可以看到是0.26,接近提升6个百分点(相比0.21),效果显著
当前我们的模型总结起来大体是

二 input+cnn
这里主要就是不使用birnn,而是使用一个简单的cnn,顺便看了一下其在bag方式上面的效果:
![]()
大概运行了200个epoch,可以看到还不如bag的baseline,所以说birnn还是要好点
三 input+双层birnn+attention_2
这里尝试使用双层birnn,因为第一层(底层)偏向提取语法方面的信息,第二层(高层)偏向提取语义方面的信息,至于理论语句是有一篇论文,答辩视频中也提到了,作者是通过用底层birnn的输出和高层的输出去分别做语法语义方面的任务,发现底层善于处理语法高层善于处理语义,这里我们将两层输出进行简单的加和(借鉴第一名的思路),当前模型大体框架是

其中attention_2(借鉴第二名思路)
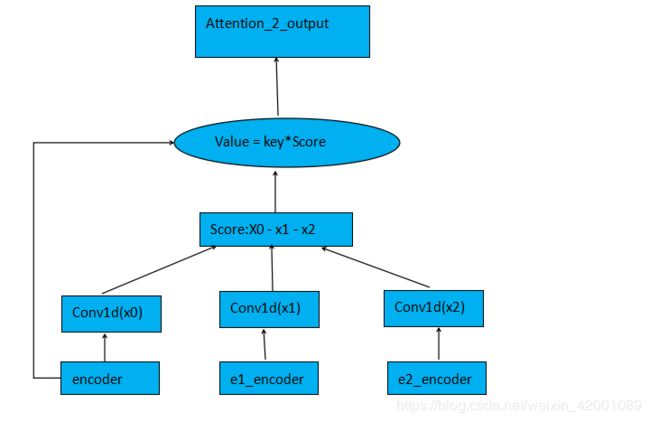
这里的x0-x1-x2的含义是用除了两个实体以外的其它文本信息去做打分机制,而上面我们的attention_1是直接使用了自身encodr作为打分机制的,所谓打分机制实际上目的就是要得到一个[batch_size,max_len,1]的向量
![]()
相比于第一个0.2693稍微提高了一点,效果不是很明显
四 input(cnn)+双层birnn+attention_2

这里主要在embedding的时候先使用cnn分别对word,位置,词性进行一次cnn提取特征
![]()
效果不好,反而下降了
四 双层birnn+attention_1+level_1
看了那几种分类,其实可以看到是有等级的比如1-29都属于一大类亲属关系,30-32社交关系,33-34师生关系,0自己属于一大类,于是这里试了一下在输出层使用一个level_1矩阵做一个四分类计算一个loss,然后再经过2两个全连接层做一个35分类计算一个Loss,将两部分loss作为最后的总loss结果:
![]()
没有效果
五 sigmoid
看到说使用sigmoid可以一定程度上屏蔽类间干扰,相当于多个二分类,然后计算loss的时候因为知道label嘛,取出对应的概率去计算,恩恩,貌似很有道理,但是实践效果极差
六 双层birnn(gru)+attention_1+MASK
这里是将实体对都替换成MASK,因为判断实体对的关系更多的是应该考虑除实体对以外的那些文本
![]()
有所提高
六 数据增强相关
一般来说数据NLP数据增强比较容易想到的就是随机drop掉一些词和shuffle随机打乱一些句子顺序
(1)双层birnn(gru)+attention_1+drop

(2)双层birnn(gru)+attention_1+drop+MASK
(3)双层birnn(gru)+attention_1+drop+shuffle
drop+shuffle![]()
(4)双层birnn(gru)+attention_1+drop+shuffle+MASK
![]()
(5)双层birnn(gru)+attention_1+shuffle+MASK
![]()
七 双层birnn(gru)+MultiHeadAttention+MASK
![]()
这里主要考虑了bert Transformer中的MultiHeadAttention,注意在具体代码实现的时候,原本多头attention,是重复多次然后concat,这里是将hidden先均分成多份,然后分别进行attention所以最后MultiHeadAttention的结果最后一维不是n*hidden而还是hidden
从上面(1)(2)来看drop带来好处,但是MASK反而降低性能
从(3)(4)来看MASK似乎又带来了性能的提高
因为数据增强这里采用的是随机选择一些词进行打乱或drop,不难想象有可能会drop掉一些关键词,而且在关系抽取中我们多次应用了位置信息,打乱位置信息的话可能也会带来一定影响,但是这样随机假如一些扰动在一定程度也可以增加模型的泛化性,说实话没有试验前,不会做出好不好的判断,上述是一部分试验结果,也许再次运行的话又会有不一样的结果,因为数据增强是随机的,drop和shffle到底有没有用?有多大的用?从上面看貌似有点作用,至于MASK能不能提高性能,为什么会出现(2)的情况,这个到后面其实还在一直运行,貌似已经收敛,截取的结果,0.276的结果也是在跑了一段时间后本以为收敛了,可是出现了0.276,总得来说感觉MASK还是很有用。
后续在做相关任务的时候,其实最好的办法就是去试一试看看效果
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
第三部分
其也是只有bag这种方式的单标签
一:将解压的数据放入origin_data目录下 二:数据预处理
python initial.py
三:训练
python train_GRU.py
其中它会自动调用test_GRU.py验证其在dev上面的性能
四:预测结果
python predict_GRU.py 2643
其中2643是加载2643模型,可以加载别的,具体看model下面有哪些即可
运行结果:

遇到的问题和一些总结:
一 : 上述都是基于tensorflow实现的,这里偶然间看到一个基于pytorch实现的类似OpenNRE,想要开发pytorch版 本可以参考一下https://github.com/ShulinCao/OpenNRE-PyTorch
二 :经过试验可得,使用gensim或是bert预训练的词向量总体上会有大幅度提高,但对比word2vec,bert貌似在当前(NRE)问题中没有看到显著优势(其主要在文本分类上面优势比较明显),线下有稍微提高,线上反而效果又欠佳
三:pcnn相比于rnn有做了__piecewise_pooling改进,但是效果在该数据集上却比cnn差一点
六:这里也没有进行调参,而且在确定了最后要用的模型后,为了提高一点可以同时使用train和dev数据集去训练,然后预测test,当然啦这没什么技术层面的技巧,纯粹是为了扩大点数据量增加分数,以上结果都是单纯训练train数据集的结果
总结一下其它比较好的几个思路:
1 人工打标
2 先对NA和非NA做一个而分类,有关系的话再进行多种关系的多分类,这其实就是前面说的多级分类
3 对bag进行句子合并
4 调整远程监督的打标的结果

模型的话大部分都是bert,将实体对放在句首,用:隔开,必须是:,真是玄学
