由浅入深学习:图模型->无向图模型->马尔可夫网络->CRF模型->CRF++工具
关于CRF模型网络中资料很多,但没有一篇感觉能彻底看透CRF,所以在广泛阅读的过程中总结此文,本文是建立在对其他资料(见本文结尾)的学习基础上,加入了一些个人的理解,若有不对之处欢迎批评指正。
文章目录
- 一、整体知识结构
- 二、图模型
- 三、无向图模型
- 四、马尔可夫网络
- 五、CRF模型
- 六、CRF++工具
- 六、补充
一、整体知识结构
对于小白来讲,在学习CRF模型时,首先要对知识的整体结构有一个理解,哪怕里面所有的细节你都不知道,也要有先了解有哪些概念词语,后期才有补习的可能。
整体知识结构,如下图所示:
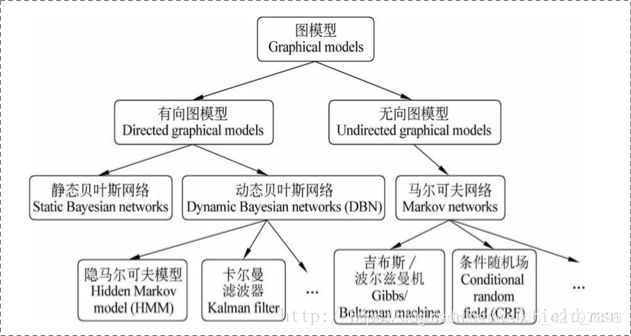 可以看出:
可以看出:
1.图模型主要分为两种:
- 一种是有向图模型(directed graphical model),也就是贝叶斯网络( Bayesian network)。这种图模型的特点就是链接是有方向的,画出来就是带个箭头
- 另一种是无向图(undirected graphical models),也就是马尔科夫随机场(Markov random fields)。这种模型的的链接没有箭头,没有方向性质。
2.我们要学习的CRF模型是属于图模型当中的无向图模型下的马尔可夫网络下一个分支CRF模型。本文将依次探究这条线上的这几个概念(也就是加粗的这些概念)。
二、图模型
这里的图模型又称为概率图模型。
首先,为什么会产生概率图模型?
对于一般的统计推断问题,概率模型能够很好的解决,那么引入概率图模型又能带来什么好处呢?
简而言之,就是图使得概率模型可视化了,这样就使得一些变量之间的关系能够很容易的从图中观测出来;同时有一些概率上的复杂的计算可以理解为图上的信息传递,这是我们就无需关注太多的复杂表达式了。
另外,对于特定的一些任务,比如词性标注,给定一个句子「I like machine learning」,然后标注每个词的词性(名词、代词、动词、形容词等),我们不能通过单独处理每个词来解决这个任务,需要根据上下文的情况来处理,但是标准的分类模型来处理这些问题并没有什么优势,相比之下概率图模型(PGM/probabilistic graphical model)是一种用于学习这些带有依赖(dependency)的模型的强大框架。
其次,什么是图模型?
下面这张图片描述的就是图,它是由一些带有数字的圆圈和线段构成的,其中数字只是一种标识。我们将圆圈称为节点,将连接圆圈的节点称为边,那么图可以表示为G(V,E)

如果边有方向,称图为有向图,否则为无向图;
再次,什么是概率图模型?
对于上述普通图模型而言,在概率图模型中,节点和边有特殊的意义:
- 每个结点表示一个(或一组)随机变量。
- 边则表示两个随机变量概率的相互影响关系,或者说是条件概率关系(有向图),关于边含义的具体理解建议看下下面这个实例,思索之后得出你自己的感悟。
下面举三个概率图模型的例子,你最少要看懂举例1。
举例1:(这个例子为了弄懂概率图是什么)
通过最开始的体系图,我们了解到概率图模型分为有向图和无向图,在这里我们以有向图为例(因为我觉得下面有向图这个实例更好理解,该图是贝叶斯网络的一个典型案例:学生网络student network),进行说明,一个概率图模型(有向)如下图所示:
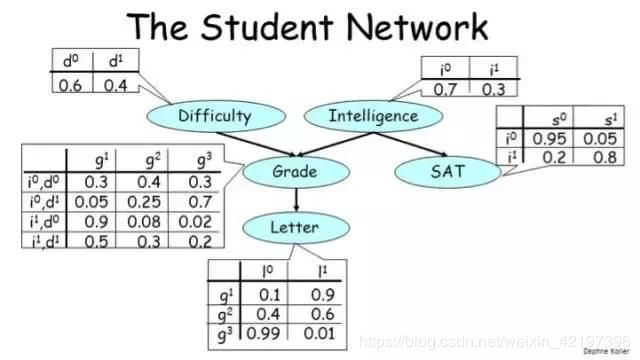
可以看到,图中的5个节点表示5个随机变量:
- 本门课程的难度(Difficulty):可取两个值,d0=0 表示低难度,d1=1 表示高难度
- 学生智力水平(Intelligence):可取两个值,i0=0 表示不聪明,i1=1 表示聪明
- 学生本门课程成绩(Grade):可取三个值,g1=1 表示差,g2=2 表示中,g3=3 表示优
- 学生从教授那里所得到的推荐信的质量(Letter):可取两个值,L0=0 表示推荐信不好,L1=1 表示推荐信很好
- 学生 SAT 成绩(SAT):可取两个值,S0=0 表示低分,S1=1 表示高分(特意查了下, SAT是由美国大学委员会(College Board)主办的一场考试,其成绩是世界各国高中生申请美国大学入学资格及奖学金的重要参考,感觉类似我们的高考)
可以看到,图中的4条边表示两个随机变量之间的概率影响关系:
- Grade 取决于课程的 Difficulty 和学生的 Intelligence;
- Grade 决定了学生能否从教授那里得到一份好的 Letter;
- Intelligence 除了会影响他们的 Grade,还会影响他们的 SAT 分数。
箭头的方向表示了影响的因果关系——Intelligence 会影响 SAT 分数,但 SAT 不会影响 Intelligence
可以看到,每个节点关联的表格,则是该节点随机变量的概率分布(Difficulty 节点、Intelligence节点)或者条件概率分布CPD/conditional probability distribution(Grade节点、Letter节点、SAT节点)
另外,贝叶斯网络的一个基本要求是图必须是有向无环图(DAG/directed acyclic graph)。
举例2(这个例子为了说明图的联合概率分布)
举例1我们了解了概率图是什么,和它能够表示出随机变量和随机变量之间的影响关系,但是光表示给人看,除了让你觉得可视化效果不错欣喜一会儿之外,没多大意义,所以,我们还需要计算这张图成立的概率,也就是图的联合概率分布。第二个例子如下:
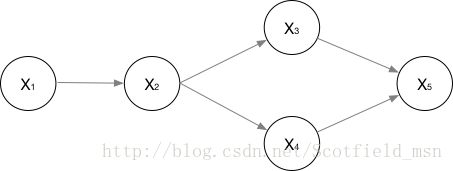
有了举例1,我们容易理解上述图中,从X1指向X2的箭头,也就是边,是指X1对X2的概率有影响,那么这种影响或者这条边可以表示为p(X2|X1)。
根据伟大的乘法准则:
![]()
这张图的整个联合概率分布,就是图中这些结点变量所关联的概率之积:
P(x1,⋯,xn)=P(x1)⋅P(x2|x1)⋅P(x3|x2)⋅P(x4|x2)⋅P(x5|x3,x4)
由此,则得出下面公式:
![]()
那么按这种方法,对于举例1来说,所有节点都为最差(Difficulty=d0,Intelligence=i0,Grade=g1,Letter=L0,SAT=s0)的概率如下:
P(Difficulty,Intelligence,Grade,Letter,SAT)
=P(Difficulty)*P(Intelligence)*P(Grade/Difficulty,Intelligence)*P(Letter/Grade)*P(SAT/Intelligence)
=0.6 * 0.7 * 0.3 * 0.1 * 0.95
=0.01197
举例3(一个特殊情况)
譬如有一组变量X1,X2…Xn,如果每个变量只与其前一个变量有关,这种情况为1阶马尔可夫过程,那么如何用图来表示这一关系呢?如下

有了上面的概念和三个例子我相信你对图模型有了一定理解,再往下走,我们来看图模型下层的无向图模型。
三、无向图模型
上述有向图模型的例子,我们可以看出有向图之间的边是随机变量之间概率的相互影响,或者说是条件概率关系,但是,很多时候我们知道两个变量之间一定是相关的,但我们不知道到底是怎么相关的(这种情况又称为弱假设)。这时候我们也可以用其相关性来构造概率图模型。相关是不分方向的,此时我们应该选择无向图来表示。
1.无向图定义
- 每个结点表示一个(或一组)随机变量。
- 边则表示两个随机变量概率的相互影响关系,只是这种关系不明朗。
2.无向图的联合概率分布
既然关系不明朗,那么如何计算无向图的联合概率分布呢?一般的做法,是对无向图进行分解,分解成团,再计算最大团的势函数乘积(这里你就需要弄懂各种公式了)
举例:
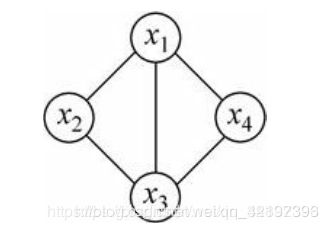
该无向图有X1,X2,X3,X4,共4个节点,首先将它们分解为团clique。
- 什么是团?
任何两个结点均有边连接的结点子集(完全子图)称为团。例如,上图中由2个节点构成的团有5个:
{x1,x2},{x2,x3},{x3,x4},{x1,x3},{x1,x4}
- 什么是最大团?
若 C 是无向图 G 的一个团,且不能加进任何一个 G 的结点使其成为一个更大的图案,则称此 C 为最大团。例如,上图中有两个最大团
{x1,x2,x3},{x1,x3,x4}
而{x1,x2,x3,x4} 不是一个团因为X2和X4没有连接。
- 什么是团的势函数?(重要)
在无向图中,对每个团定义一个势函数,用来表示团内随机变量之间的相关关系。势函数取自物理学中的势能概念,势能在物理中指的是储存于一个系统内潜在的能量。在无向图中的势函数使团内随机变量偏向于具有某些相关关系。(势能函数也称为因子、团因子、特征函数)
例如,假设团 {x1,x2} 具有势函数
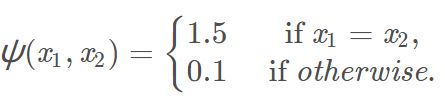
则说明该团的势函数偏向使 x1和 x2具有相同的取值。势函数刻画了局部变量之间的相关关系,它应该是非负的函数,为了满足非负性常用指数函数来定义势函数,即

H(x) 是一个定义在变量 x上的实值函数,又被称为能量函数,这样可以让我们把乘积变为加和。 常见形式为(里面u不等于v那个符号有点模糊):
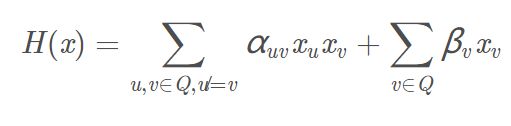
上式中的 Q是团内所有结点的集合,第一项需考虑所有结点的关系,第二项只要考虑单结点。αuv 和 βv 是需要通过学习来确定的参数。
- 怎样求联合概率分布?(重要)
记团块为C,将团块中的变量的集合记作xC。联合概率分布可以写成图的最大团块的势函数(potential function)ψC(xC)的乘积的形式: 如果下面这个公式你还不理解,先记住它吧。

这里, Z被称为划分函数(partition function),是个归一化常数, 势函数并不要求是具有概率意义的函数,故需要有一个划分函数对最后结果归一化,等于:
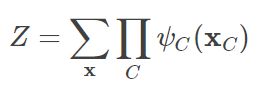
那么对于刚才那个举例(无向图有X1,X2,X3,X4)来说,联合概率分布:

ψ c ( Y c ) ψ_c(Y_c) ψc(Yc)为最大团上的势函数,一般取指数函数

那么概率无向图的联合概率分布可以在因子分解下表示为:
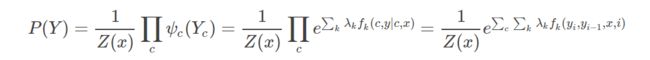
上述内容遵循的数学定义:
汉莫斯定义:假设有一堆势函数(因子函数),将所有的势函数相乘,再除以归一化因子,这个概率分布描述的是无向图的概率图模型的联合概率分布,这也叫做吉布斯分布。
3.有向图无向图对比分析
(1)无向图不需要是无环的,这一点和有向图不一样。
(2)为什么我们需要有向图,也需要无向图?
原因是有些问题使用有向图表示会更加自然,比如上面提到的学生网络,有向图可以轻松描述变量之间的因果关系——学生的智力水平会影响 SAT 分数,但 SAT 分数不会影响智力水平(尽管它也许能反映学生的智力水平)。
而对于其它一些问题,比如图像,你可能需要将每个像素都表示成一个节点。我们知道相邻的像素互有影响,但像素之间并不存在因果关系;它们之间的相互作用是对称的。所以我们在这样的案例中使用无向图模型。
总结,一方面无向图可以表示有向图无法表示的一些依赖关系,如循环依赖;另一方面,它不能表示有向图能够表示的某些关系,如推导关系。
(3)总的来说,有向图和无向图都是用来描述概率分布的形式,有向图可以转化为无向图表示(从无向图转化到有向图表示不太常用)
四、马尔可夫网络
1.什么是马尔可夫网络
如果上述无向图图退化成线性链的方式,则得到马尔可夫模型 ;因为每个结点都是随机变量,将其看成各个时刻(或空间)的相关变化,以随机过程的视角,则可以看成是马尔可夫过程 。
若上述网络是无向的,称马尔可夫随机场或者马尔可夫网络 。
简单的来说,马尔可夫网络由无向图表示,并且图上的随机变量具有马尔可夫性质,马尔可夫网络也叫马尔可夫随机场。
2.什么是马尔可夫性
马尔可夫性质指的是将一个随机变量状态序列按时间先后顺序展开后,在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定随机变量现在状态时,它的取值与过去状态(即状态转移的历史路径)无关,那么此随机过程即具有马尔可夫性质。简单说就是在已知“现在”的条件下,“未来”与“过去”彼此独立的特性(显然这样可能导致很多重要的信息都丢失了。)
P(Xn+1=xn+1/X1=x1,…Xn=xn)=P(Xn+1=xn+1/Xn=xn)
包括全局马尔可夫性、局部马尔可夫性和成对马尔可夫性。
(1)全局马尔科夫性举例如下:

设结点集合 A,B 是在无向图 G 中被结点 C 分开的任意结点集合,结点集合 A ,B 和 C 所对应的随机变量组分别是 YA ,YB和YC。全局马尔可夫性是指在给定随机变量组 YC 条件下随机变量组 YA 和 YB 是条件独立的,即
![]()
(2)局部马尔可夫性:
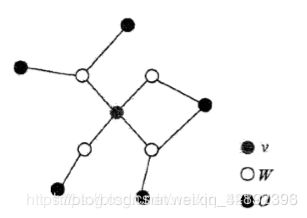

(3)成对马尔可夫性

3.什么是马尔可夫随机场
(1)什么是随机场
当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。
我们不妨拿种地来打个比方。其中有两个概念:位置(site),相空间(phase space)。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
(2)马尔可夫随机场
还拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
五、CRF模型
1.什么是CRF
CRF(conditional random field,条件随机场)
- 如果在给定某些条件的前提下,研究这个马尔可夫随机场,则得到条件随机场 。
- 如果进一步将条件随机场中的网络拓扑变成线性的,则得到线性链条件随机场 。
《统计学习方法》中条件随机场的定义

CRF的数学语言描述:设X与Y是随机变量,P(Y|X)是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔可夫随机场,则称条件概率分布P(Y|X)是条件随机场。
linear-CRF的数学定义:设 X = ( X 1 , X 2 , . . . , X n ) , Y = ( Y 1 , Y 2 , . . . , Y n ) X=(X_1,X_2,...,X_n),Y=(Y_1,Y_2,...,Y_n) X=(X1,X2,...,Xn),Y=(Y1,Y2,...,Yn)均为线性链表示的随机变量序列,在给定随机变量序列X的情况下,随机变量Y的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)构成条件随机场,即满足马尔可夫性: P ( Y i ∣ X , Y 1 , Y 2 , . . . , Y n ) = P ( Y i ∣ X , Y i − 1 , Y i + 1 ) P(Y_i|X,Y_1,Y_2,...,Y_n)=P(Y_i|X,Y_{i-1},Y_{i+1}) P(Yi∣X,Y1,Y2,...,Yn)=P(Yi∣X,Yi−1,Yi+1),则称P(Y|X)为线性链条件随机场。
一般说CRF为序列建模,就专指CRF线性链(linear chain CRF),先来看它的可视化样子如下,和刚才的举例3有点像,只不过是无向图,而且下面多了一排节点。

线性链条件随机场的参数化形式:
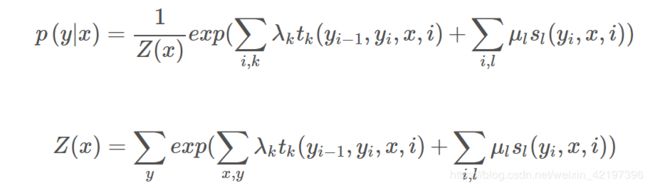
t k t_k tk和 s l s_l sl是取值为0,1的特征函数(也就是后面我们要介绍的定义在边上的转移特征函数和定义在节点上的状态特征函数), λ k λ_k λk和 μ l μ_l μl是对应的权值
里面的i和k、l表示双层循环相加,i表示某一个字符的位置,k、l表示不同的特征函数
里面的x为输入的文本句子,y为某一个标注序列,则P(Y/X)则表示在给定的一条观测序列X的情况下,某一组标注序列(隐状态序列)Y的概率
注意:上述的公式是在无向图的基础上推导过来的,推导过程如下:


2.什么是CRF特征函数
举例:Bob drank coffee at Starbucks
标注:名词,动词,动词,介词,名词
显然不靠谱,因为它把第二、第三个单词都标注成了动词,动词后面接动词,这在一个句子中通常是说不通的。假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们可以定义一个特征函数:凡是标注中出现了动词后面还是动词的标注序列,要给它负分!
可以看出,每一个特征函数都可以用来为一个标注序列评分,**把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。**有了这个值,CRF就可以给所有结果排序
特征函数的输出:标注序列的分值:0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。
特征函数的输入:四个参数
- 句子s(就是我们要标注词性的句子)
- i,表示句子s中第i个单词
- l_i,表示标注序列中第i个单词标注的词性
- l_i-1,表示标注序列中第i-1个单词标注的词性
3.用特征函数求概率
定义好一组特征函数后,我们要给每个特征函数 f j f_j fj赋予一个权重 λ j λ_j λj。现在,只要有一个句子s,有一个标注序列l,我们就可以利用前面定义的特征函数集来对l评分。
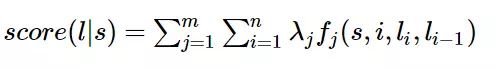
上式中有两个求和,外面的求和用来求每一个特征函数f_j评分值的和,里面的求和用来求句子中每个位置的单词的的特征值的和。
对这个分数进行指数化和标准化,就可以得到标注序列l的概率值p(l|s):
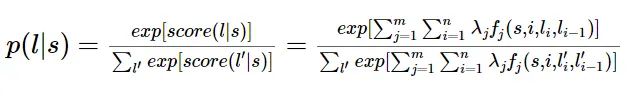
特征函数举例:
- 当l_i是“副词”并且第i个单词以“ly”结尾时,我们就让f1 =
1,其他情况f1为0。不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列 - 如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。
- 当l_i-1是介词,l_i是名词时,f3 = 1,其他情况f3=0。λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。
- 如果l_i和l_i-1都是介词,那么f4等于1,其他情况f4=0。这里,我们应当可以想到λ4是负的,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
有了多个特征函数后,一个条件随机场就建立起来了,总结一下:
为了建一个条件随机场,我们首先要定义一个特征函数集,每个特征函数都以整个句子s,当前位置i,i-1的标签为输入。然后为每一个特征函数赋予一个权重,然后针对每一个标注序列l,对所有的特征函数加权求和,必要的话,可以把求和的值转化为一个概率值。
六、CRF++工具
在CRF++工具中,定义特征模板,模板自动批量产生大量的特征函数(if语句,成立返回1,不成立返回0)。
Unigram和Bigram模板分别生成CRF的状态特征函数 ![]() 和转移特征函数
和转移特征函数 ![]() 。其中 y_i 是标签, x 是观测序列, i 是当前节点位置。每个函数还有一个权值
。其中 y_i 是标签, x 是观测序列, i 是当前节点位置。每个函数还有一个权值
CRF++的模板有U系列(unigram)、B系列(bigram)
例如:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# Bigram
B
下面进行解释:
1.unigram
举例如下
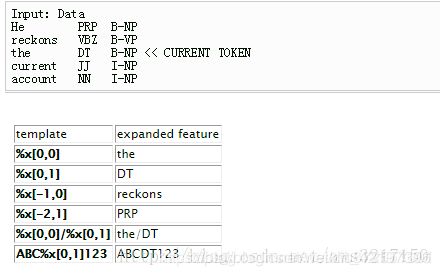
“%x[row, column]” 代表获得当前指向位置向上或向下偏移|row|行,并指向第column列的值。指的要考虑哪个位置的词。 且90%的例子中我们看到的特征模版中的column都是=0的,这意味着column=0,我们只把字/词当作特征。
格式规则:
- 每行模版可使用多个位置。例如:U18:%x[1,1]/%x[2,1]
- 字母U后面的01,02是唯一ID,并不限于数字编号。如果不关心上下文,甚至可以不要这个ID
上图中,当前指向位置为 “the DT B-NP”,那么:
”%x[0,0]”代表获得当前指向偏移0行,第0列的值,也就是”the”,这条模板构成的一组特征(函数)含义是:“当前位置的词是“the”且label=xx”是否为真(xx可以是预定义label中的任一个)。每个模板会把所有可能的标记输出都列一遍,然后通过训练确定每种标记的权重,合理的标记在训练样本中出现的次数多,对应的权重就高,不合理的标记在训练样本中出现的少,对应的权重就少,但是在利用模板生成转移特征函数是会把所有可能的特征函数都列出来,由模型通过训练决定每个特征的重要程度。
%x[0,1]”代表获得当前指向偏移0行,第1列的值,也就是”DT”,。这条模板构成的一组特征(函数)含义是:“当前位置的词性是“DT”且label=xx”是否为真(xx可以是L中label中的任一个)。
”%x[-2,1]”则代表获得当前指向向上偏移2行,第1列的值,也就是”PRP”,这条模板构成的一组特征(函数)含义是:“前前位置的词性是“PRP”且label=xx”是否为真(xx可以是L中label中的任一个)。
如此类推。
对于”U01:%x[0,1]”这样一个模版,上面例子的输入数据会产生如下的特征函数: (可以看出,每一行模板生成一组状态特征函数,数量是L*N 个,L是标签数,N是输入序列长度为)

这里有一个问题:”%x[0,0]”和”%x[-1,0]”遇到“the"是否产生了重复的特征?
答案是否定的:
因为”%x[0,0]”遇到“the",产生的特征函数,举一个label=b为例来说就是,产生了f1=“**当前位置的词是“the”**且当前位置label是b"是否为真。
而”%x[-1,0]”遇到“the”,产生的特征函数,举一个label=b为例来说就是,
产生了f2="**前一个位置的词是“the”**且当前位置label是b"是否为真。
显然不一样,f2在每个位置上都会去检查前一个位置是否为“the”。
最后产生的这些大量的特征值,就是我们训练得到的model
整个过程如下:

2.Bigram类型(Bigram模版的B是二元的意思)
与Unigram不同的是,Bigram类型模板生成的函数会多一个参数:上个节点的标签 y i − 1 y_{i-1} yi−1
生成函数类似于:
func1 = if (prev_output = B and output = B and feature=B01:“北”) return 1 else return 0
这样,每行模板则会生成 L* L* N 个特征函数。经过训练后,这些函数的权值反映了上一个节点的标签对当前节点的影响。
绝大多少例子中的Bigram模版就写了一个B,这里的B是一个简要记法。还原的话应该是”B01:%x[0,0]”,
3.应该怎样定义特征模板,才能使效果最好?

普通任务如上图所示的特征模板就可以做的比较好,主要是捕捉到当前字符、前后字符的对应关系,转移特征B主要是上一个输出对当前输出的影响。如要提升效果,根据任务情况再设计特征模板。
关于CRF++工具的使用实例,可以参考我的另一篇文章:一文读懂如何利用CRF模型完成实体识别(实例详解)
六、补充
1.关于判别式模型和生成式模型
机器学习分为有监督的机器学习和无监督的机器学习
有监督的机器学习就是已知训练集数据的类别情况来训练分类器(比如 分类任务),无监督的机器学习就是不知道训练集的类别情况来训练分类器(比如聚类任务);
有监督的机器学习,通过很多有标记的数据,训练出一个模型,然后利用模型对输入的X进行预测输出的Y。而这个模型一般有两种:
- 决策函数:Y=f(X)
- 条件概率分布:P(Y|X)
获取这两种模型的不同方法可以分为判别方法和生成方法:
- 判别方法:由数据直接学习决策函数Y=f(X)或条件概率分布P(Y|X)作为预测模型,即判别模型。A批模型 (神经网络模型、SVM、perceptron、LR、DT、CRF、MEMM……)
- 生成方法:由数据先学习联合概率分布P(X,Y), 然后由P(Y|X)=P(X,Y)/P(X)求出概率分布P(Y|X)作为预测的模型,即生成模型。B批模型 (NB、LDA、HMM……)

优缺点
在监督学习中,两种方法各有优缺点,适合于不同条件的学习问题。
生成方法的特点:上面说到,生成方法学习联合概率密度分布P(X,Y),所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。但它不关心到底划分各类的那个分类边界在哪。生成方法可以还原出联合概率分布P(Y|X),而判别方法不能。生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快的收敛于真实模型,当存在隐变量时,仍可以用生成方法学习。此时判别方法就不能用。
判别方法的特点:判别方法直接学习的是决策函数Y=f(X)或者条件概率分布P(Y|X)。不能反映训练数据本身的特性。但它寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。直接面对预测,往往学习的准确率更高。由于直接学习P(Y|X)或P(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
2.时间有限,格式有点乱,请谅解
该文章参考了以下内容:
概率图模型
概率图模型理解
读懂概率图:你需要从基本概念和参数估计开始
概率图模型——马尔可夫网络
详解概率图模型——概述
马尔可夫网络,(马尔可夫随机场、无向图模型)(Markov Random Field)
概率图模型学习笔记:HMM、MEMM、CRF
一次性弄懂马尔可夫模型、隐马尔可夫模型、马尔可夫网络和条件随机场!
如何轻松愉快地理解条件随机场(CRF)?
CRF模型——打通crf模型的任督二脉(一)
crf++里的特征模板