街景字符编码识别项目学习笔记(四)CNN介绍及字符识别模型的pytorch实现
内容简介
本文主要介绍在项目应用中使用的卷积神经网络,及其在pytorch中的如何实现。
CNN介绍及其发展历程
CNN介绍
卷积神经网络(Convolutional Neural Network)是一类特殊的神经网络。同全连接神经网络等不同的是,卷积神经网络直接对二维数据乃至三维等高维数据进行处理,并且具有更高的计算精度和速度。尤其是在计算机视觉领域,CNN的应用非常广泛,使其成为了解决图像分类、图像检索、目标检测、语义分割的主流模型。
CNN当中应用的卷积操作和传统的图像处理及信号处理当中使用的卷积操作一致。卷积操作如下图(图片源于互联网)所示:
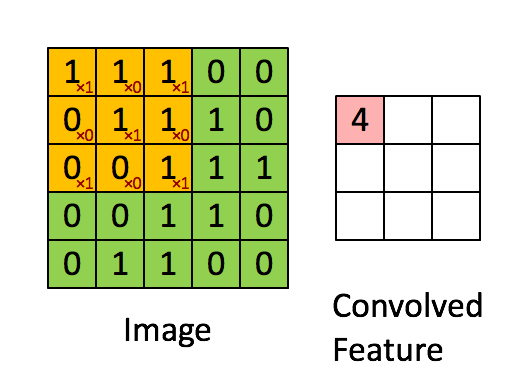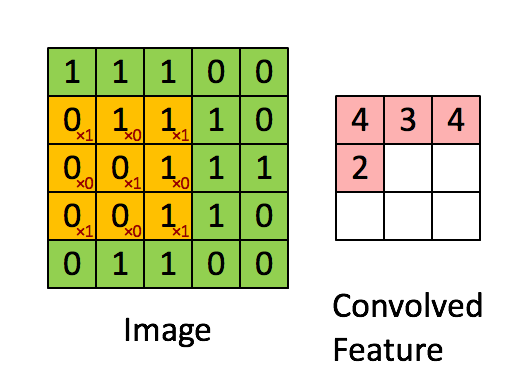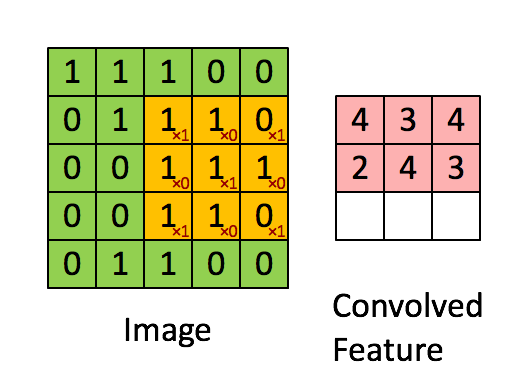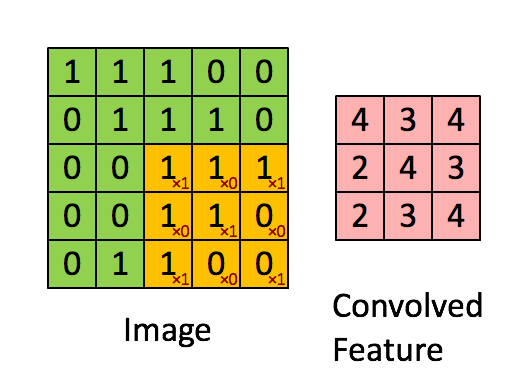
CNN是一种层次模型。模型的输入是图像数据。通常的CNN模型都会包括卷积(convolution)层、池化层(pooling)、非线性激活函数(non-linear activation function)和全连接层。
卷积层:传统的图像当中,我们可以通过设置不同的卷积核来提取图像当中不同的特征信息,如Sobel算子提取图像当中的边缘,garbor滤波中提取不同的纹理信息。在卷积层中,我们通过设置卷积核的数目,大小和步长等信息,对原始图像进行同样的特征提取操作。只不过在传统图像处理当中,这样的卷积核是加入人先验知识之后获取的,而CNN当中,这些卷积核能够提取的图像特征是经过数据输入学习而来的,经过卷积处理之后得到的数据也称之为feature map。当对CNN每一层的卷积核进行可视化之后,我们可以发现,最开始的卷积层能够学得的特征和传统人为设计的特征较为一致,随着卷积层数的增加,网络能够学到的特征变得越来越复杂。因此,提高卷积层的层数能够增大模型的表示能力,也即容量。
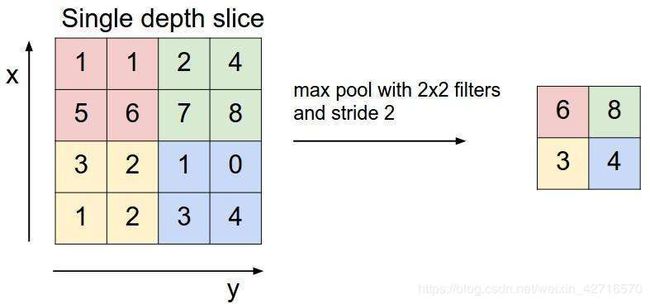
池化层:思考人对图像当中存在的物体进行的过程,我们通常没有审视整个图像,而是依据一些局部的特征就足以进行准确的判断。根据这样的指导思想,池化层孕育而生。通过提取一定区域(如22、33像素方格之中)内的关键信息,CNN通常能够更加准确快速的获取目标信息,同时又能够减少模型的参数量,大大提高了运行效率。基于以上的思想,我们可以得到平均池化操作(即对区域内的像素值取平均操作当做一个像素传递到下一层),最大池化(取区域内的最大值)等池化操作。具体操作如下图所示:
非线性激活函数:同一般的神经网络相同,采用非线性激活函数能够使网络全过程训练摆脱单一的线性关系,让feature map获得的特征更加符合现实。在大部分CNN网络架构当中,采用ReLU函数作为激活函数,ReLU函数表示如下:
R e L U = { x , if x > 0 0 , if x ≤ 0 ReLU= \begin{cases} x, & \text {if $x$ $>$ 0} \\ 0, & \text{if $x$ $\leq$ 0} \end{cases} ReLU={x,0,if x > 0if x ≤ 0
- ReLU以0为阈值,能够使feature map当中更多的数值为0,使其变得稀疏,能够一定程度上防止过拟合,有利于特征提取。
- ReLU函数同sigmoid、tanh函数相比求导更加简单。由函数图形看,可能在0点的时候函数是不可导的,在实际应用当中,对零点导数的取值同左侧一致,即为0。这样的梯度取值同样能够避免梯度消失和梯度爆炸问题的出现。
- 可能有些读者会认为,ReLU在大于0的部分和小于0的部分不是线性的嘛,为什么说ReLU函数是非线性激活函数呢?考虑一层feature map 当中3*3九个元素a1~a9,每一个ai有:
a i = w T x i + b a_i = w^Tx_i+b ai=wTxi+b
w为卷积核的参数,b为偏置,xi为上一层的输入参数(9个)。对于每一组(w,b),他们都确定了一个超平面,且a1~a9这九个点均在这一个超平面上(因为卷积核参数不变)。那么当经过ReLU激活函数之后,结果如下:
R e L U ( a i ) = { w T x i + b if w T x i + b > 0 0 , if w T x i + b ≤ 0 ReLU(a_i)= \begin{cases} w^Tx_i+b & \text {if $w^Tx_i+b$ $>$ 0} \\ 0, & \text{if $w^Tx_i+b$ $\leq$ 0} \end{cases} ReLU(ai)={wTxi+b0,if wTxi+b > 0if wTxi+b ≤ 0
从上式我们可以很清晰得看到,经过ReLU之后,这个超平面被分成了两部分,其中一部分是原来平面的折叠。三维空间当中,这样折叠效果如下图所示(原图片源自互联网):
可以想象得到,当经过若干层卷积操作和ReLU激活之后,高维空间会被超平面一步一步得划分下去(每一个卷积核都可以代表不同的超平面),从而能够拟合出任意函数在高维空间中划分出来的空间。因此,ReLU函数实际上是一个非线性激活函数,当然这种非线性程度和卷积层、ReLU的层数密不可分。
全连接层:全连接层的引入能够方便网络将提取到的特征值直接转化为我们想要的目标。比如实现手写数字识别的项目中,最后可以加入输出为10个神经元的输出层。每一个神经元代表的都是0-9数字当中的一个,输出的值可以看做是图片对应数字出现的概率。选取最大的即可获得输入图片对应的期望数字。在街景字符识别项目当中,我们首先实现基于定长字符识别的思路进行实现。在resnet18网络架构之后加入5个相互独立的512个神经元到11个元的输出层,每一个输出层负责识别一位数字,最终将数字组合到一起,即可以得到总体的预测结果。为什么这里是11个神经元呢,数字不是0-9一共只有10个嘛?因为定长识别当中需要额外添加一个空位,这在识别当中同样被算作一个字符,所以输出为11个神经元。
CNN发展历程
随着更多的trick被人们提出,以及计算机算力的发展。CNN在逐渐变得越来越复杂,越来越多样化,从上个世纪的LeNet-5(1998),在ImageNet上面大放异彩的AlexNet(2012),以及之后进行改善的VGG-16(2014),Inception-v1(2014)和ResNet-50(2015),繁多的CNN架构无疑证明了基于卷积神经网络的网络模型架构在计算机视觉领域是非常有效实用的模型。近几十年的CNN发展一览如下图所示(Khan 2020):
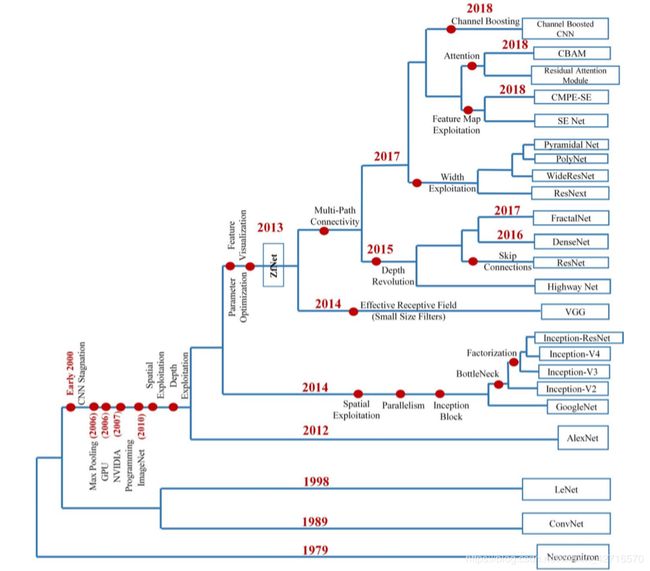
A survey of the recent architectures of deep convolutional neural networks (Khan 2020)是来自Artificial Intelligence Review的一篇有关于深度卷积神经网络的综述文章。该文章针对深度卷积神经网络在近年来发展中采用的模型架构以及其中应用的各种技巧做了非常详尽的描述,在此不再赘述。有兴趣的读者欢迎根据以上链接进行阅读。
CNN by pytorch
笔者在学习笔记(二)当中已经介绍了pytorch中有关tensor的基本操作,以及pytorch当中实现神经网络全过程的基本模式。本节将重点关注用pytorch实现卷积神经网络。介绍的主要内容同样总结于datacamp上的课程 Introduction to deep learning by pytorch。
引入需要的库
import torch
import torch.nn
构建2D的卷积层
conv = torch.nn.Conv2d(in_channels=3,out_channels=1,kernel_size =5,stride=1,padding=0)
in_channels代表图片的输入通道,RGB图片即为三通道,Gray即为单通道图片。out_channels即为输出通道,这里数目的多少也就代表了卷积核数目的多少。kernel_size定义了卷积核的大小,stride代表了卷积运算的步长,padding代表了是否要对图像进行元素扩充。处理实例如下所示:
imgs = torch.rand(16,3,32,32) #这里随机生成了16个32*32的三通道图片
out_imgs = conv(imgs) #进行卷及操作
print(out_imgs.shape) #torch.Size([16,1,28,28]) 可以看到这里为处理过后的16张图片
构建池化层
max_pooling = torch.nn.MaxPool2d(2)
avg_pooling = torch.nn.AvgPool2d(2)
定义池化层中括号内的参数代表的是池化的size大小,2即为2*2。应用实例如下所示
im = torch.Tensor([[[[3,1,3,5],[6,8,7,9],[3,2,1,4],[0,2,4,3]]]]) # 1*1*4*4的图片
out = max_pooling(im)
print(out) #tensor([[[[6.,9.],[3.,4.]]]])
实现AlexNet
AlexNet的成功无疑为卷积神经网络的应用开启了一个新的纪元。此处用pytorch实现AlexNet的基本架构。AlexNet的结构示意图如下所示(Alex Krizhevsky 2012):
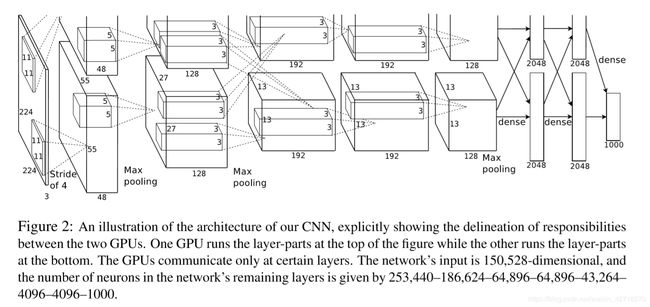
之所以分上下两路的原因在于2012的时候GPU的运算性能并没有那么强大,所以整个网络是在两个GPU上面进行计算的。AlexNet by pytorch:
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet,self).__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size = 11,stride=4,padding=2)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2)
self.conv2 = nn.Conv2d(64,192,kernel_size=5,padding=2)
self.conv3 = nn.Conv2d(192,384,kernel_size=3,padding=1)
self.conv4 = nn.Conv2d(384,256,kernel_size=3,padding=1)
self.conv5 = nn.Conv2d(256,256,kernel_size = 3,padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((6,6))
self.fc1 = nn.Linear(256*6*6,4096)
self.fc2 = nn.Linear(4096,4096)
self.fc3 = nn.Linear(4096,1000)
def forward(self,x): #数据流
x = self.relu(self.conv1(x))
x = self.maxpool(x)
x = self.relu(self.conv2(x))
x = self.maxpool(x)
x = self.relu(self.conv3(x))
x = self.relu(self.conv4(x))
x = self.relu(self.conv5(x))
x = self.maxpool(x)
x = self.avgpool(x)
x = x.view(x.size(0),256*6*6) #把x拉成一维的数据
x = self.relu(self.fc1(x))
x = self.relu(seld.fc2(x))
return self.fc3(x)
pytorch同样提供了nn.Sequential()方法来对上述的网络进行集成,以便于构建层数非常多的网络结构。用nn.Sequential()整理AlexNet可得:
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet,self).__init__()
self.features = nn.Sequential(nn.Conv2d(3,64,kernel_size = 11,stride=4,padding=2),nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2), nn.Conv2d(64,192,kernel_size=5,padding=2)
nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(192,384,kernel_size=3,padding=1),nn.ReLU(inplace=True),
nn.Conv2d(384,256,kernel_size=3,padding=1),nn.ReLU(inplace=True),
nn.Conv2d(256,256,kernel_size = 3,padding=1),nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),)
self.avgpool = nn.AdaptiveAvgPool2d((6,6))
self.classifier = nn.Sequential(
nn.Dropout(),nn.Linear(256*6*6,4096),nn.ReLU(inplace=True),
nn.Dropout(),nn.Linear(4096,4096),nn.ReLU(inplace=True), nn.Linear(4096,1000),)
def forward(self,x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0),256*6*6)
x = self.classifier(x)
return x
其中,nn.Dropout()为在全连接层当中应用dropout技巧,这么做能够大大提高神经网络的鲁棒性。这样的技巧适合应用再全连接层当中,不适合应用在卷积层当中。
batch normalization技巧
在pytorch中实现BN技巧的方式如下所示:
self.bn = nn.BatchNorm2d(num_features=64,eps=1e-05,momentum=0.9)
运用迁移学习
torchvision当中已经存储了许多已经训练好的网络,便于我们直接读取来进行迁移学习,具体的引用方法以及在原模型上加额外层数的方式如下图所示(示例为加载已经训练好的resnet18网络):
import torchvision
model = torchvision.models.resnet18(pretrained=True)
model.fc = nn.Linear(512,1000)
因为resnet18最后为512个元素输出,所以添加的全连接层为512个神经元输入,后一个参数可以修改至自己想要的分类数目。
以下利用迁移学习的例子,来对本次街景字符当中应用的较为简单的模型进行说明。
街景字符识别模型 by pytorch
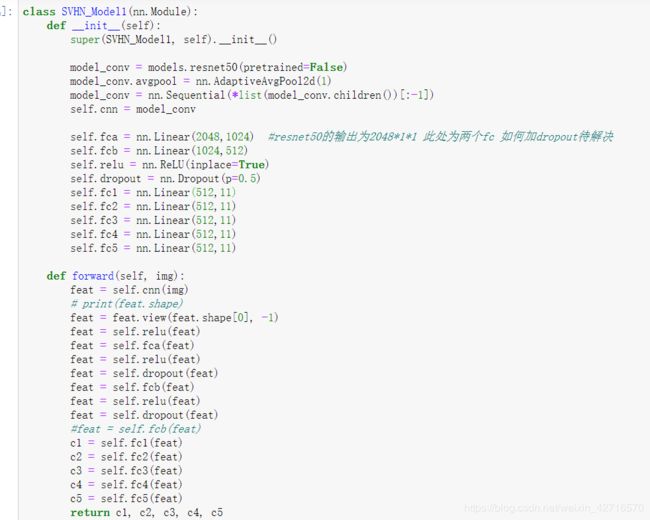
目前baseline所给出的CNN模型如下所示:
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
model_conv = models.resnet18(pretrained=True)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
self.cnn = model_conv
self.bn = nn.BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)#一维的bn
self.dropout = nn.Dropout(p=0.5)
self.fc1 = nn.Linear(512,11)
self.fc2 = nn.Linear(512,11)
self.fc3 = nn.Linear(512,11)
self.fc4 = nn.Linear(512,11)
self.fc5 = nn.Linear(512,11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
feat = self.bn(feat)
feat = self.dropout(feat)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
return c1, c2, c3, c4 , c5
采用预训练的resnet18模型,然后加上五个相互独立的FC层分别识别五个数字。
目前实验结果的一些分析
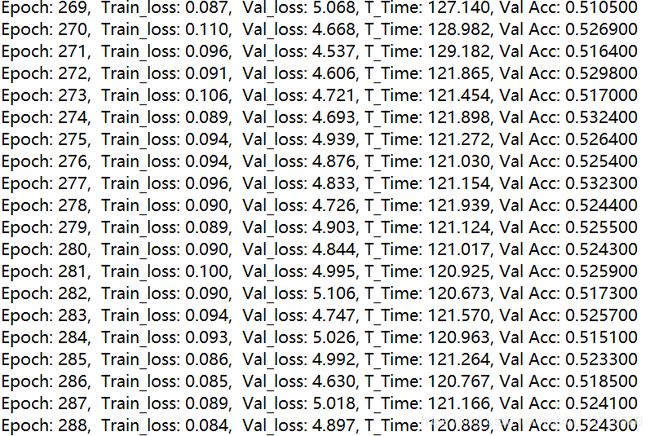
- 笔者同样采用了resnet34、resnet50模型(resnet101因为显存不够因此没做实验,效果如何还需另作判断)对该问题进行相同思路的建模(其中resnet50的输出为2048,因此需要对全连接层进行修改,将512替换为2048),均存在着过拟合的问题,其中resnet50的过拟合问题最为严重。笔者曾运行了280多个epoch,训练误差可以降低到0.1以下,但是测试集的误差仍然在4.5-5.0左右难以降低。模型结构和实验结果如下两图所示:
因此,基于这样的定长字符识别的思路,resnet18仍然是最好的预训练模型。 - 笔者对resnet18进行了一些参数方面的调整,增大了权重2范数正则化项的系数,在200epoch上保持稳定训练时,大概结果如下图所示:

笔者目前得到的最好正确率是60.36%,泛化误差最好为2.515。不过在和别人交流的过程中,测试误差可以在20个epoch左右就能够降低到2.1多,同样也是resnet18模型。(说明调参能力还需要加强,hh) - 其实,基于定长字符识别思路进行下去的话,感觉模型正确率的提升还是有一定限度的,能够融合目标检测在里面的话,应该能够获得更高的准确率的。定长字符识别可能出现的错误较多,这是由评分标准决定的,一个字符串只要有一个字符出现问题,则整个字符串就判错。
参考文献
1:Khan, A., Sohail, A., Zahoora, U. et al. A survey of the recent architectures of deep convolutional neural networks. Artif Intell Rev (2020). https://doi.org/10.1007/s10462-020-09825-6
2:Krizhevsky, Alex , I. Sutskever , and G. Hinton . “ImageNet Classification with Deep Convolutional Neural Networks.” Advances in neural information processing systems 25.2(2012).