街景字符编码识别项目学习笔记(六)模型集成
内容简介
由之前相关的博客介绍的内容,我们已经可以通过pytorch构建一个初步的字符识别模型,并实现了端到端的识别验证预测的相关工作。本节,我们聚焦模型集成有关内容,仍然是在保持模型本体不变的基础上,尽可能增加模型准确率的一些方法。
集成学习方法
在机器学习中的集成学习可以在一定程度上提高预测精度,常见的集成学习方法有Stacking、Bagging和Boosting,同时这些集成学习方法与具体验证集划分联系紧密。
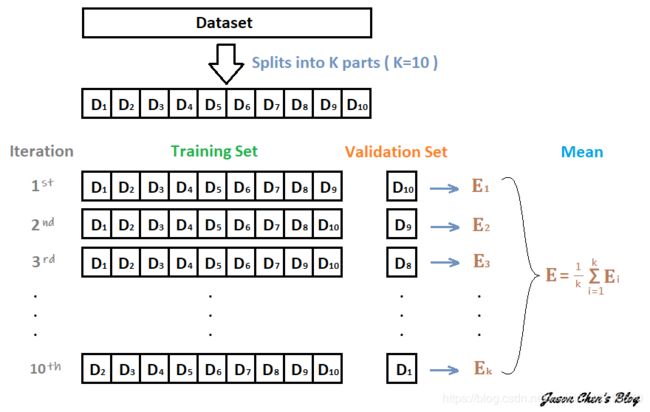
由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许建议选取留出法,如果需要追求精度可以使用交叉验证的方法。
如:下面假设构建了10折交叉验证,训练得到10个CNN模型。
Dropout方法
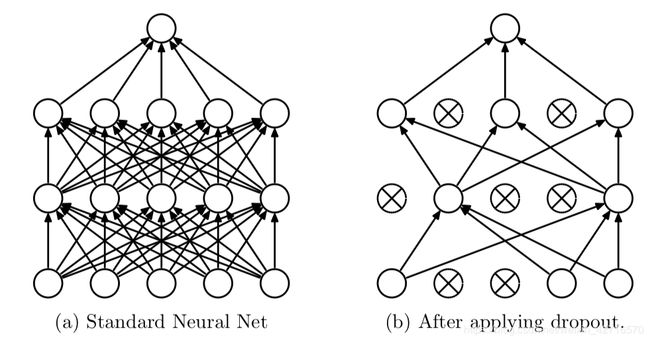
Dropout可以作为训练深度神经网络的一种技巧。在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点都其作用。如下图所示:
在pytorch当中对应的代码实现为:
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.Dropout(0.25),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.Dropout(0.25),
nn.MaxPool2d(2),
)
#
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
这之中 nn.Dropout 即为dropout层, 括号内的参数为每一个神经元对应去除连接的概率,这样的技巧能够大大增加模型的泛化能力。
测试集数据扩增(Test Time Augmentation)
测试集数据扩增(Test Time Augmentation,简称TTA)也是常用的集成学习技巧,数据扩增不仅可以在训练时候用,而且可以同样在预测时候进行数据扩增,对同一个样本预测三次,然后对三次结果进行平均。 如下图所示:

对应python代码实现如下:
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
c0, c1, c2, c3, c4, c5 = model(data[0])
output = np.concatenate([c0.data.numpy(), c1.data.numpy(),
c2.data.numpy(), c3.data.numpy(),
c4.data.numpy(), c5.data.numpy()], axis=1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
Snapshot
本章的开头已经提到,假设我们训练了10个CNN则可以将多个模型的预测结果进行平均。但是加入只训练了一个CNN模型,如何做模型集成呢?
在论文Snapshot Ensembles中,作者提出使用cyclical learning rate进行训练模型,并保存精度比较好的一些checkopint,最后将多个checkpoint进行模型集成。如下图所示:
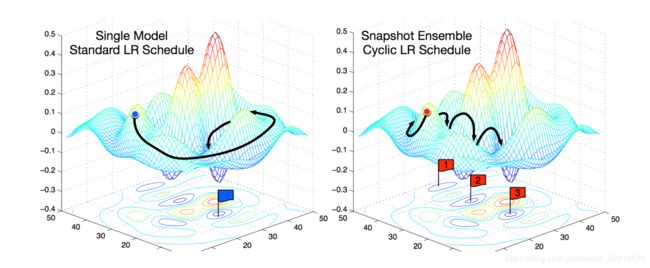
于在cyclical learning rate中学习率的变化有周期性变大和减少的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用表明,此种方法可以在一定程度上提高模型精度,但需要更长的训练时间。

总结
当我们构建完一个模型之后,可以通过上述的这些方法来增加模型的鲁棒性和泛化能力。
不过这一切的基础都是建立在模型自身对问题有足够准确的表示能力,既不能欠拟合,同时又不能过早的过拟合,否则进行后续的改正并不能显著(比如10个百分点左右的程度)提高模型的准确率。实际上经过诸多实验,笔者认为模型继续训练的价值在于模型接近表示能力上限附近之后对模型进行的微调,而模型集成有关的方法能够对上限有稍许的提升,这点根据上述的相关实验测试结果可以较为显然得看出来