CUDA peer to peer多GPU间内存copy技术
CUDA不仅仅支持单GPU之间的运算,还支持多GPU之间数据传递,多GPU主要解决以下几个问题:
1:现有计算的数据集过大,不能在单个GPU之间进行运算。
2:通常单个GPU适合单任务处理,如果要增加吞吐量和效率,可以使用多GPU并发处理来。
GPU P2P
在同一个PCIe节点内两个GPU0和GPU1,如果GPU0的计算结果或者数据想传从到GPU1中,两个GPU之间的通信完全是依赖CPU,即CPU0首先将数据传送到CPU, CPU再把数据传送到GPU0中。此时可以看到数据传输带宽受限于CPU带宽,且由于copy两次,数据延迟也交大。
为了解决以上问题,英伟达提出了GPU peer to peer(P2P)技术,即两个GPU之间能够直接传送数据:
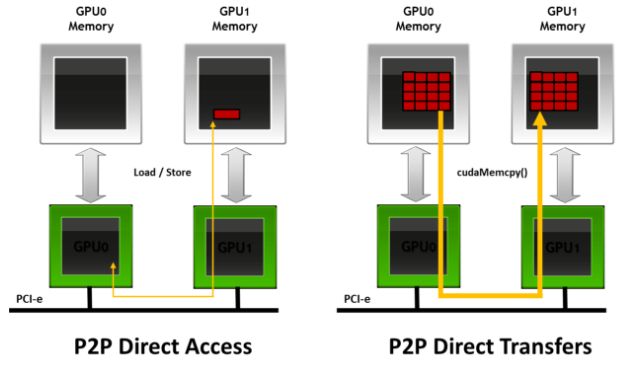
该技术可以直接提高GPU的利用带宽以及降低GPU之间数据传输延迟。
CUDA P2P相关API
为了使用P2P技术,CUDA提供了一系列API支持,在确定使用GPU P2P之前首先要查看当前设备中有多少个硬件GPU设备:
__host__ __device__ cudaError_t cudaGetDeviceCount ( int* count )
用于获取当前设置中能够使用的GPU设备数量。
在使用多GPU之前,必须指定后面的操作在哪个GPU设备上进行操作:
__host__ cudaError_t cudaSetDevice ( int device )
cudaSetDevice()为异步函数,执行速度非常快,不会导致堵塞。如果不指定设备,默认指定为0,指定的设备id 应为0~count之间,一旦选定了当前设备,所有的CUDA运算将被应用到该设备中:
- 任何从主线程中分配来的设备内存将完全常驻于该设备上。
- 任何由CUDA运行时函数分配的主机内存都会有与该设备相关的生存时间。
- 任何由主机线程创建的流或事件都会与该设备相关。
- 任何由主机线程启动的内核都会在该设备上执行。
可以通过上述API执行后面指令运行的函数。
使用范例:
int npus;
cudaGetDeviceCount(&npus);
for(int i = 0;i >>(...);
//asynchronously transfer data between the host and current devices
cudaMemcpyAsync(...);
} 上述例子中因为内核和copy都是使用的异步,所以每次调用都会很快返回,即使内核或者当前线程发出的传输仍然在硬件上执行,也会通过cudaSetDevice转换后面的执行函数,并不会相互影响。
在时间GPU之间允许点对点访问的GPU都是链接在同一个PCIe根节点上,使其可以之间引用存储在其他GPU设置内存上的数据。对于透明的内核,引用的数据将通过PCIe总线传输到请求的线程上。但是在实际硬件中,并不是所有GPU都支持点对点访问,所以需要使用相关API进行检查,是否支持P2P:
__host__ cudaError_t cudaDeviceCanAccessPeer ( int* canAccessPeer, int device, int peerDevice )
如果设备device能够直接访问对等设备peerDevice的全局内存,那么函数变量canAccessPeer返回为1.
如果两个GPU之间支持P2P访问,则需要使用以下API进行显示开启点对点内存访问:
__host__ cudaError_t cudaDeviceEnablePeerAccess ( int peerDevice, unsigned int flags )
该API允许从当前设备到peerDevice进行点对点访问。flag参数被保留以备将来使用,目前必须将其设置为0。一旦成功,该对等设备的内存将立即由当前设备进行访问。
该函数授权的访问是单向的,即这个函数允许从当前设备到peerDevice的访问,但不允许从peerDevice到当前设备的访问。如果希望对等设备能直接访问当前设备的内存,则需要另外一个单独的匹配调用。
关闭P2P功能,API:
__host__ cudaError_t cudaDeviceDisablePeerAccess ( int peerDevice )
P2P功能开启后可以使用一下函数进行异步复制:
__host__ cudaError_t cudaMemcpyPeerAsync ( void* dst, int dstDevice, const void* src, int srcDevice, size_t count, cudaStream_t stream = 0 )
同步复制API :
__host__ cudaError_t cudaMemcpyPeer ( void* dst, int dstDevice, const void* src, int srcDevice, size_t count )
也可以使用cudaMemcoy
__host__ cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
kind可以使用cudaMemcpyDeviceToDevic 或者cudaMemcpyDefault