redis的持久化配置与主从复制
文章目录
- redis简述
- redis的优缺点
- 上面有提到持久化,何为持久化?
- 实现持久化的方式
- redis 的数据结构
- 实现redis的持久化
- 部署redis
- 持久化之RDB配置
- 持久化之AOF配置
- 重启redis使其生效,验证持久化
- redis主从复制
- 另起一台服务器,安装redis
- 主服务器上新建键值,测试从服务器自动同步
redis简述
redis是一款由c语言编写的,开源的高可用的非关系型数据库(NoSQL,不仅仅是数据库)型的键值对(key-value)数据库。
与传统的数据库不同的是redis的数据是存在内存的,所以读写性能不是一般的高,可达到每秒10万次操作,因此被广泛的应用到缓存方向,例如:在网站架构里面和tomcat做session共享,做数据库缓存等。
redis的优缺点
优点
- 读写速度快,读能达到110000次/s,写能达到81000次/s,c语言写的,代码优雅,而且还是单线程架构 ,所以执行效率高,速度快
- 支持多种数据结构
字符串(string,也是最常用的),哈希(hash),列表(list),集合(SET),有序集合(ZSET) - 丰富的功能,例如:天然计数器, 键过期功能,消息队列等
- 支持的客户端语言多,支持 php,java,python
- 支持数据持久化
- 自带多种高可用架构,比如:主从复制,哨兵,高可用集群
缺点
-
正是因为数据都存在内存里,所以对服务器性能要求严格,根据业务量自己选择内存选购多大
-
很难实现在线扩容,所以第一次选购需谨慎
上面有提到持久化,何为持久化?
持久化就是支持把内存中的数据写到磁盘里面,防止服务器宕机了内存里面数据全部丢失。
实现持久化的方式
支持2种格式持久化数据AOF, RDB,还有就是这两种混合使用 AOF&RDB
注意:当这种都开启时,redis数据恢复优先使用AOF,但是RDB是默认的持久化方式。
AOF持久化:就是把redis每一次执行的命令都记录到单独指定的日志文件里面,当重启或者要恢复数据时就会恢复日志文件中的数据
RDB:就像是拍快照一样,按照配置文件定义的save参数来定义快照的周期,然后保存到硬盘里面,会产生dump.rdb文件
AOF和RDB的对比:
- AOF文件比rdb更新频率高,优先使用aof还原
- aof比rdb更安全
- rdb性能比aof要好,数据量很大时,日志恢复速度比rdb慢
- 在持续读写时,如果rdb拍摄快照,会有数据延迟,恢复的数据会不完整
redis 的数据结构
| 数据类型 | 存储值 | 常用的操作命令 | 应用的场景 |
|---|---|---|---|
| string | 字符串 | SET(创建),GET(查看),DEL(删除),MSET(批量创建),MGET(批量查看 | 做缓存,键值对的过期时间, 把session会话存在redis,过期删除, 缓存用户信息,缓存Mysql部分数据,商城优惠卷过期时间等 |
| list | 列表 | RPUSH(创建,若存在则向右边添加),LPUSH(左添加,LRABGE+范围(查看范围值),RPOP(删除右边最后一个),LPOP(删除左边最后一个) | 一般与zset结合用,主要应用于排行榜,热度/点击数排行榜,直播间榜一大哥排行等 |
| hash | 哈希 | HMSET+对象(创建对象的键值,针对的是一个对象),HGET+对象(查看对象的某个参数) | 一般key是ID或唯一标识,value是对应的详细信息,如:商品信息,个人信息,新闻等 |
| SET | 无序集合 | SADD(创建集合),SMEMBERS(查看集合),SREM(删除集合的值),SDIFF集合1 集合2(求差集),SINTER 集合1 集合2 (求合集),SUNION集合1 集合2(求并集) | 求交集,并集,合集,应用于社交网络,如:共同爱好,共同好友等 |
| ZSET | 有序集合 | 同SET | 可以和list结合完成排行榜 |
实现redis的持久化
部署redis
1.创建数据目录
mkdir -p /redis/soft
mkdir -p /opt/redis_cluster/redis_6379/{conf,logs,pid}
解释下为什么自己创建conf,logs,pid目录,而不是让它初始化自动生成
我们是为了再一台主机上开启多个redis进程来实现后期的redis集群(至少6台)(Author电脑配置不允许我任性操作)
2.下载redis安装包
cd /redis/soft
wget http://download.redis.io/releases/redis-5.0.6.tar.gz
3.解压redis到/opt/redis_cluster/
tar zxf redis-5.0.6.tar.gz -C /opt/redis_cluster/
ln -s /opt/redis_cluster/redis-5.0.6 /opt/redis_cluster/redis #做好软连接,方便自己管理
4.切换目录安装redis
cd /opt/redis_cluster/redis
make && make install
5.自己编写配置文件/opt/redis_cluster/redis_6379/conf/6379.conf
添加一些重要的内容
添加:
bind 127.0.0.1 192.168.10.1
port 6379
daemonize yes #开启daemon进程
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
databases 16
dbfilename redis.rdb #RDB持久化文件
dir /opt/redis_cluster/redis_6379 #RDB存放的位置
6.启动当前redis服务
redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
[root@redis-master ~]# netstat -anpt |grep 6379
tcp 0 0 192.168.10.1:6379 0.0.0.0:* LISTEN 49206/redis-server
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 49206/redis-server
tcp 0 0 127.0.0.1:41400 127.0.0.1:6379 TIME_WAIT -
tcp 0 0 192.168.10.1:6379 192.168.10.8:46220 ESTABLISHED 49206/redis-server
[root@redis-master ~]#
持久化之RDB配置
修改配置文件,添加save项
vim /opt/redis_cluster/redis_6379/conf/6379.conf
添加:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 500 #在60秒(1分钟)之后,如果至少有500个key发生变化,则dump内存快照
持久化之AOF配置
同为修改配置文件
添加appendonly,启用持久化
vim /opt/redis_cluster/redis_6379/conf/6379.conf
添加:
appendonly yes #启用AOF持久化
appendfilename "redis.aof" #指定AOF文件名
appendfsync everysec #每秒同步一次
重启redis使其生效,验证持久化
redis-cli shutdown
redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
在redis数据库里面添加键值对
#!/bin/bash
for i in {1..500}
do
redis-cli set k_$i v_$i
done

这时候关闭数据库,内存里的东西正常肯定会丢失,但是,现在肯定不会丢失的,而且还会有持久化的文件
[root@redis-master ~]# redis-cli shutdown
[root@redis-master ~]# redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
[root@redis-master ~]#
[root@redis-master ~]# redis-cli
127.0.0.1:6379> keys k_500
1) "v_500"
127.0.0.1:6379>
redis主从复制
为什么要做redis主从复制?
为解决单点故障把数据复制到一个或多个副本副本服务器(从服务器),实现冗余,达到故障恢复和负载均衡的目的
另起一台服务器,安装redis
1.为了简单,我们直接复制前边master
[root@redis-master ~]# scp -rp /opt/redis_cluster/ [email protected]:/opt
2.直接make install安装redis,无须再编译,在master已经做过
修改配置文件
cd /opt/redis_cluster/redis
vim /opt/redis_cluster/redis_6379/conf/6379.conf
修改:
bind 127.0.0.1 192.168.10.8
slaveof 192.168.10.1 6379 #添加master的ip port
保存退出
3.启动服务
redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
主服务器上新建键值,测试从服务器自动同步
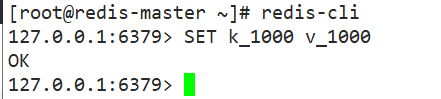
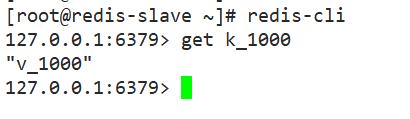
注:
从服务器在同步过程中,只能复制主数据库的数据,不能手动添加修改数据;
如果从服务器非要修改数据,需要断开同步:
[root@redis-slave ~]# redis-cli slaveof no one
提示OK即可
如果master宕机的话,从服务器可以先手动断开同步,这时候,他就是一个独立的个体,其他的从服务器再指向自己,即可完成切换