国能日新光伏功率预测大赛的总结
目录
写在前面的话
关于比赛
数据和特征工程
1. 时间
2.float数据
3.category数据
4.其他特征
关于特征选择
关于模型调参
关于模型融合
反思和总结
写在前面的话
人生第二次打比赛,一开始是单打独斗,完全陌生的业务场景,我根据能搜索到的Tips疯狂尝试,在别人那里好用的Trick,在我这里效果却疯狂下降,期间也通过开源的baseline学到了提取特征的常见套路,对数据的处理有了一点懵懂的感觉,直到比赛加入了靠谱的队友,但是由于时间原因,未能获得理想的成绩。
新手入门,Mark一下。
关于比赛
这题的任务是,根据提供的4个电场的气象数据和辐照数据,预测4个电场未来的发电功率,是一个回归问题。
这里是赛题链接。
评价指标是MAE,每日绝对偏差,对4个电场取平均,只计算预测功率大于装机功率的样本。
启示1:解题先读题,磨刀不误砍柴工,最终分数只算正功率的样本,所以训练模型的时候应该剔除晚上的数据,因为晚上无发电功率,甚至存在没有光照但有发电功率的异常数据,会对模型造成扰动。
数据和特征工程
原始数据如下

原始数据分为3类:时间数据、float气象数据、category数据。
1. 时间
通过画时间-功率图,我们发现发电功率随着时间的推进,呈现明显的波动趋势,所以时间是个强特征,需要好好挖掘一下。
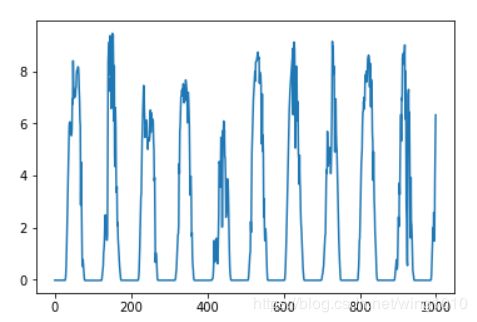 时间-功率图
时间-功率图
首先经过简单的split,提取出样本所在的年、月、日、小时;
一开始我们以为这题是一个时间序列问题,即假设历史是会重复的,根据以往预测未来,后来发现并不是,但是仍然可以借鉴时间序列模型的思想,构造:当前月是距离初始时间的第几个月、第几年,都可以反映出功率曲线的变化趋势;
差分特征:从第二行开始,求所有维度上本行与上一行的差,可以反映样本在各个特征上的变化。
 差分特征(辐照度,温度)
差分特征(辐照度,温度)
很好理解,光伏发电主要依靠太阳能,时间数据肯定是有用的,其次月份信息也能反应出电场的发电计划、工人排班情况等,之后在处理float数据的时候,通过对天和月分组求统计特征,印证了我们的猜想。
构造的特征如下

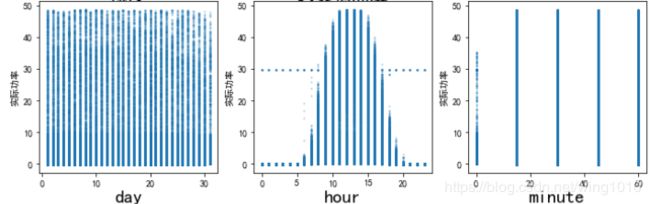
可以看到,hour特征是非常强的。
2.float数据
- 特征交叉
一开始不知道怎么处理float数据,都是气象参数,不知道怎样的气象会真正影响发电功率,先对温度-湿度,温度-湿度-压强做了简单的乘积交叉,有所提升;之所以做乘积不做加减,是因为乘积可以为模型带来非线性变换,使问题更接近线性,提升模型的准确性。
加强版:不同气象参数对发电功率的影响程度肯定是不一样的,我们不知道影响程度是多少,也很难通过查阅资料获得;所以可以根据不同的组合特征对功率训练一个多项式回归模型,让模型去学习各个气象参数的权重,把多项式回归的output作为一个新特征,就能很好的刻画组合特征的影响。
特征组合需要注意的点有两个:
一是找到靠谱的组合。
不能拍脑袋构造组合特征,需要有数据/指标的支持。
我们画了一个功率的等高线图,横纵轴分别是待组合的特征,通过观察等高线图,就可以看出,随着两个特征的增大/减小,功率是否有单调的变化趋势;如果有,这基本就是一个好的组合,当然还需要验证。
【等高线图待补充】
二是新特征的验证。
主要是通过计算原始特征和组合特征对实际功率的相关性,来判断组合是否有效;如果组合后相关性较原始特征上升了,则说明是一个有效的组合,否则就有待商榷。
启示2:在数据分析中,每做一个操作,都需要有依据,操作的好坏都需要有评判的标准,且标准要靠谱,如果不是完全靠谱,也要知道在什么样的情况下,是靠谱的。如果实际与理论分析不符,要排查bug,思考原因。
比如温度和湿度的二阶组合,就是一个较强的特征;由于我们还构造了太阳仰角等特征,维数较多,所以没有在组合之前一一判别,而是先全组合,然后统一根据相关性排序,划定一个阈值,选择特征,即特征降维。
注:pandas的corr计算的是皮尔森系数,即线性相关性,工具包stats也有相关API.
另外test集里没有实发辐照度这个数据,我们尝试用模型预测实发辐照度,但效果不好,主要原因应该是实发辐照度与辐照度相关性过高,而受其他气象参数影响较小,所以放弃了这个方法。但是在有些场景中,通过参数预测参数的方法还是有用的。
- 统计特征
统计特征的意义大家都知道,常见的有均值、方差、标准差、中位数等,在合适的范围内求统计特征,可以有效标识出数据的特点,还有峰度和偏度等,这次没有使用,以后可以尝试。
我们选择的是当月的每一天,辐照度、温度、湿度的标准差;个人认为这个范围还可以划的再小一点,更精细一点;
所有样本中的经验数据:历史每一天的实际功率的各种统计特征;
最终构造的统计特征如图
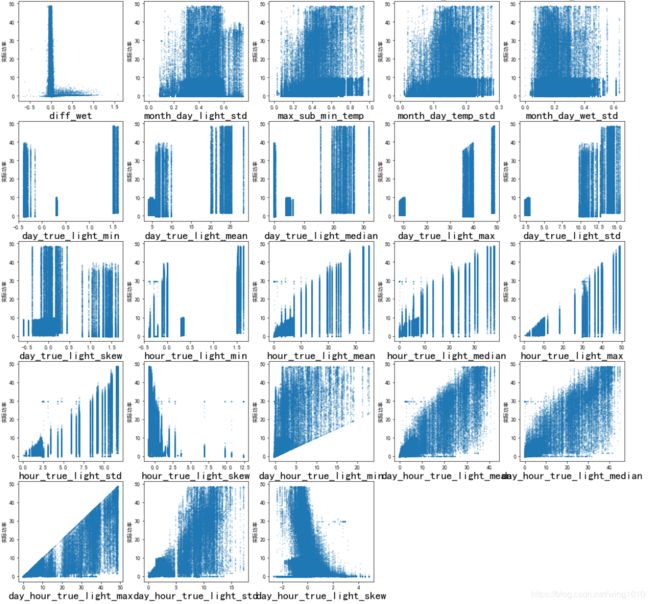
可以看到,这些特征还是很有区分能力的。
3.category数据
原始的离散数据只有风向,特征工程又提取了年月如等类别特征。
- onehot编码
关于类别特征的处理,按理说XGBoost/LightGBM不需要专门做onehot,但还是做onehot树的节点的生长更精细,因为类别中的不同取值的重要性肯定是不同的,应该具有不同的权重。
另外,关于集成树模型的理解,其实树模型是不太适合处理连续问题的,因为在节点分裂的时候,要找一个划分点把连续的特征划分开,这势必导致信息的丢失,为了将信息丢失减少到最小,可以人工做一些靠谱的离散化,使模型更加稳定。
- 聚类离散化
这题给的数据全部是归一化脱敏的,无法手动分桶,可以采用聚类方法,把数据聚成几簇,进行离散化,产生新特征。
聚类的评价指标主要是类内相似度和类间差异度,其实聚类算法思想都一样,很多聚类算法都是通过定义新的相似度度量指标,以适应不同的业务场景;对于这种整型变量,用最简单的K-Means就行,可以根据K-Means的score画出手肘图,来选出合适的K。
聚类由于受到初始点选择的影响、对异常值敏感,所以做出来的特征不一定靠谱,还需要进行进一步的特征选择。
4.其他特征
数据不是分析完了吗,怎么还有其他特征?这就是初级选手和高级选手的区别=。=
在队友的带领下,我们通过调研,找到一个R语音的包,可以根据时间、经纬度计算出当前地区的一系列太阳辐射特征,如太阳辐射与地平面夹角、太阳仰角、距离太阳的视觉距离等,地理好的同学应该都能理解,这些特征是能直接表达太阳辐射强度的。给队友疯狂发送666. 至于经纬度嘛,随便选一个地方就好了,误差应该是常数级的~
【R语言的工具包:oce】
关于特征选择
- 特征选择的必要性
高阶特征组合可能会导致过拟合;特征离散化后维度暴增,且类别特征中每一种类型的重要性肯定是不一样的,不一定要保留类别中的所有取值。
- 常用的特征选择方法
通过相关度选择和通过树模型的feature importance选择。
通过相关度选择前面已经讲过,feature importance是类似的,都是排序后画一个折线图,根据折线拐点划分所选特征的段,然后在线下做交叉验证,选出最优的特征个数。具体来说,就是根据score从高往低,设定一个步长,从最好的特征开始,逐步加入一批特征,训练多个模型,然后画一个特征数关于score的图,从而找出最优特征数。
即特征数也是一个可以调的参数。
当然交叉验证存在一定的不靠谱性,因为随机挑选验证机可能会破坏数据原本的分布,导致交叉验证的判断不准确。我们这个比赛每天可以提交20次,就可以直接在线上测试。
feature importance类似,模型训练出来,先看看importance取值的情况,肯定是要选大于0的特征,如果都大于0,特征又很多,那么阈值就要定的苛刻一点了。需要注意的是,feature importance不是真正的“重要性”,而是这个模型认为的重要性,只有模型比较准,它的判断才是比较可信的。具体来说feature importance是在训练的过程中,使用每个特征进行分裂节点的次数,用某个特征分裂节点的次数越多,importance就越大。
关于模型调参
模型调参还是一门学问,我们写了一个小函数,可以自动调参,其实用的还是网格搜索;但是需要设好待调参的范围,人工指引它往靠谱的方向去调,否则网格就会胡乱搜索。
基本上是先粗调几轮,再细调;但是粗是多粗,细是多细,就需要对模型的原理有一定的了解,还要考虑到样本的规模和数据的取值范围等。我是个新手,举几个在本次比赛中学到的例子:
因为本题的数据大部分是连续值,树模型对于连续值的划分,是需要比离散值更细的,这很好理解,比如年龄,就可能划分出 小于10岁,10岁到18岁,18岁到30岁等等,区间会比较多,所有树会比较复杂,所以连续问题中max depth取值一般是比较大的,这题在40-100之间,可以设为-1然后cv early stop.
本题是整型数据都在-1到1之间,量纲很小,L2正则取值不会太大等等。
这只是一个粗浅的认识,具体还是需要亲自实践。
启示3:只有对算法原理充分熟悉,对数据充分了解,才能调好参。
关于模型融合
这次比赛发现模型融合真是一个牛逼的黑科技。我们队的模型融合主要有两个思路:
一是训练多个模型,挑选品质好的进行线性加权,每次融合2-4个左右。
品质好指的是,单模型预测准,模型间差异大。
然后根据MIC最大信息系数计算出模型间的相关度,画出MIC矩阵热力图,进行模型选择。
【MIC计算工具包待补充】
另外,模型差异性可以通过特征多样性、参数多样性、模型多样性来做到。只有好而不同的模型,融合才是有意义的,因为不同的模型偏好不一样,犯错的样本也不一样,因而可以取长补短,提升效果。
总的来说,做好单模型才是我们的硬实力,融合只是锦上添花。
二是多层融合,挑选融合效果较好的模型,再次融合。
反思和总结
1:理解算法原理
2:了解数据
3:不能停止交流