如何训练甚深超分辨率(vdsr)神经网络
使用深度学习的单一图像超分辨率
本示例演示如何训练甚深超分辨率(vdsr)神经网络,然后使用vdsr网络从单个低分辨率图像估计高分辨率图像。
该示例演示了如何训练vdsr网络,并提供了预先培训的vdsr网络。如果您选择培训vdsr网络,强烈建议使用具有cvida功能的nvidia™仇均,该网络具有3.0或更高的计算能力。使用gpu需要并行计算工具箱™。
如果您不想下载培训数据集或培训网络,则可以通过键入负载 ("traedvdsr-epoch-100 sc生殖器-scatemtors-23-mat“)来加载预训练的vdsr网络;在命令行。然后,直接转到本例中load('trainedVDSR-Epoch-100-ScaleFactors-234.mat');部分。
介绍
超分辨率是从低分辨率图像创建高分辨率图像的过程。本示例考虑单个图像的超分辨率(sisr),其目标是从一个低分辨率图像中恢复一个高分辨率图像.ssis具具挑战性,因为高频图像内容通常无法从低分辨率图像中恢复。如果没有高频信息,高分辨率图像的质量是有限的。此外,sisr是一个不恰当的问题,因为低分辨率图像可以产生多个可能的高分辨率图像。

提出了几种执行sisr的技术,包括深度学习算法。本示例探讨了一种用于sisr的深度学习算法,称为甚深超分辨率(vdsr)[1]。
vdsr网络
[1] .vdsr网络学习低分辨率和高分辨率图像之间的映射。这种映射是可能的,因为低分辨率和高分辨率图像具有相似的图像内容,并且主要在高频细节上有所不同。
vdsr采用剩余学习策略,这意味着网络学习估计剩余图像。在超分辨率的背景下,残差图像是高分辨率参考图像与使用双次插值进行放大以匹配参考图像大小的低分辨率图像之间的区别。残存图像包含有关图像的高频细节的信息。
vdsr网络从彩色图像的亮度中检测剩余图像。图像的亮度通道y通过红色,Y绿色和蓝色像素值的线性组合表示每个像素的亮度。相反,图像的两个色度通道(cb和cr)是表示颜色差异信息的红色,绿色和蓝色像素值的不同线性组合 .vdsr只使用亮度通道进行训练,因为人类对亮度变化比对颜色变化更敏感。
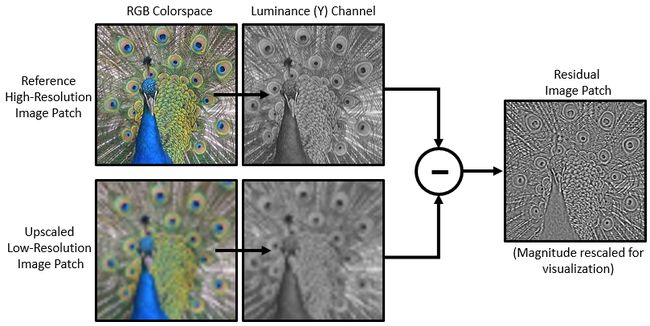
如果是高分辨率图像的亮度和是使用双双值插值进行放大的低分辨率图像的亮度,然后对vdsr网络的输入为而网络学会了预测从培训数据。
vdsr网络学习估计剩余图像后,可以通过将估计的剩余图像添加到上采样的低分辨率图像,然后将图像转换回rgb颜色空间来重建高分辨率图像。
比例因子将参考图像的大小与低分辨率图像的大小联系起来。随着比例因子的增加,由于低分辨率图像丢失了更多有关高频图像内容的信息,sisr变得更加不恰当.vdsr通过使用大的接受场解决了这一问题。本示例使用规模增强对具有多个规模因子的vdsr网络进行培训。由于网络可以利用较小比例因子的图像上下文,因此在较大的比例因子下,比例增强可提高结果。此外,vdsr网络还可以推广接受具有跨尺度因素的图像。
下载培训和测试数据
下载iapr tc-12基准,其中包括20,000静态自然图像[2]。数据集包括人,动物,城市等的照片。您可以使用帮助器功能downloadIAPRTC12Data,下载数据。数据文件的大小为~1 gb。
imagesDir = tempdir; url = 'http://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz' ; downloadIAPRTC12Data(URL,imagesDir);
本示例将使用iacr tc-12基准数据的一般部分来训练网络。加载映像clef训练数据。所有图像都是32位jpeg彩色图像。
trainImagesDir = fullfile(imagesDir,'iaprtc12','images','02');
exts = { '.jpg','。bmp','。png' };
trainImages = imageDatastore(trainImagesDir,'FileExtensions',exts );
列出训练图像的数量。
numel(trainImages.Files)
ans = 616
定义用于训练的随机修补程序提取数据存储
使用随机修补程序提取数据存储将训练数据提供给网络。此数据存储从包含网络输入和所需网络响应的两个映像数据存储中提取随机的相应修补程序。
在本例中,网络输入是使用双次插值进行放大的低分辨率图像。所需的网络响应是剩余图像。使用辅助功能createTrainingSet训练数据,例如将图像转换为ycbcr颜色空间,使用双频插值通过不同比例因子调整亮度(y)通道的大小,以及计算原始图像和调整大小的图像之间的差异。处理后的输入映像作为。mat文件存储在目录upsampledDirName的.matdirname中。计算出的残差图像作为.matmat文件存储在目录residualDirName。
scaleFactors = [2 3 4]; [upsampledDirName,residualDirName] = createTrainingSet(trainImages,scaleFactors);
从输入图像文件的集合中创建一个名为upsampledImagesimages的图像数据存储。从计算的剩余图像文件集合中创建一个称为residualImages的图像数据存储。这两个数据存储都需要一个帮助器matRead函数matread,才能从图像文件中读取图像数据。
upsampledImages = imageDatastore(upsampledDirName,'FileExtensions', '.MAT', 'ReadFcn',@ matRead); residualImages = imageDatastore(residualDirName,'FileExtensions', '.MAT', 'ReadFcn',@ matRead);
创建一个imageDataAugmenter 指定数据扩充的参数。在培训期间使用数据扩充来更改培训数据,从而有效地增加可用培训数据的数量。在这里,加成指定90度的随机旋转和x方向的随机反射。
augmenter = imageDataAugmenter(...
'RandRotation',@()randi([0,1],1)* 90,...
'RandXReflection',true);
从两个图像数据存储中创建randomPatchExtractionDatastore。指定41 x 41像素的修补程序大小(稍后在设置vdsr图层时将解释修补程序大小的选择)。指定'PatchesPerImage',以便在训练期间从每对图像中提取64个随机定位的补丁。指定一个小批处理大小为64。
miniBatchSize = 64;
patchSize = [41 41];
patchds = randomPatchExtractionDatastore(upsampledImages,residualImages,patchSize,... 。
'PatchesPerImage',64,...
'DataAugmentation' ,增强因子);
patchds.MiniBatchSize = miniBatchSize;
randomPatchExtractionDatastore时代的每个迭代中向网络提供少量数据。在数据存储上执行读取操作以浏览数据。
inputBatch = read(patchds); 摘要(inputBatch)
变量:
InputImage:64×1单元格
ResponseImage:64×1细胞
设置vdsr图层
本示例使用深度学习工具箱™中的41个单独图层定义vdsr网络,其中包括:
-
imageInputLayer- 图像输入层 -
convolution2dLayer-2d卷积层,适用于卷积神经网络 -
reluLayer- 校正线性单元(rlu)层 -
regressionLayer- 神经网络的回归输出层
第一层是imageInputLayer对图像补丁进行操作。斑块大小是基于网络接收场的,它是影响网络中最上层的响应的空间图像区域。理想情况下,网络接收字段与图像大小相同,以便可以看到图像中的所有高级功能。在这种情况下,对于深度d网络,接受场是( 2d +1) - (2d + 1)。由于vdsr是一个20层网络,接受场和图像贴片大小为41乘41. 图像输入层接受具有一个通道的图像,因为vdsr仅使用亮度通道进行训练。
networkDepth = 20; firstLayer = imageInputLayer([41 41 1],'Name','InputLayer','Normalization','none');
图像输入图层之后是一个二维卷积层,其中包含64个大小为3乘3的过滤器。将输入零垫到每个卷积层,以便要素映射在每个卷积后保持与输入相同的大小。他的方法[3]初始化随机值的权重,以便神经元学习中存在不对称。每个卷积层后面跟着一个relu层,它引入了网络中的非线性。
convolutionLayer = convolution2dLayer(3,64,'Padding',1,......
'Name','Conv1');
convolutionLayer.Weights = sqrt(2 /(9 * 64))* randn(3,3,1,64);
convolutionLayer.Bias = zeros(1,1,64);
指定一个llu图层。
relLayer = reluLayer('Name','ReLU1');
中间层包含18个交替卷积和整流的线性单元层。每个卷积层包含64个大小为3比3乘64的过滤器,其中一个过滤器在64个通道的3乘3空间区域上运行。他的方法[3]初始化随机值的权重。与以前一样,每个卷积层后面都有一个relu层。
middleLayers = [convolutionLayer relLayer];
for layerNumber = 2:networkDepth-1
conv2dLayer = convolution2dLayer(3,64,...
'Padding',[1 1],...
'Name',[ ' Conv'num2str(layerNumber)]);
%他初始化
conv2dLayer.Weights = sqrt(2 /(9 * 64))* randn(3,3,64,64);
conv2dLayer.Bias = zeros(1,1,64);
relLayer = reluLayer('Name',[ ' ReLU'num2str(layerNumber)]);
middleLayers = [middleLayers conv2dLayer relLayer];
结束
倒数第二层是一个卷积层,具有大小为3x3x64的单个滤波器,用于重建图像。
conv2dLayer = convolution2dLayer(3,1,...
'NumChannels',64,......
'填充',[1 1],...
'名称',[ ' Conv'num2str(networkDepth)]);
conv2dLayer.Weights = sqrt(2 /(9 * 64))* randn(3,3,64,1);
conv2dLayer.Bias = zeros(1,1,1);
最后一层是回归层,而不是rlu图层。回归层计算残差图像与网络预测之间的均方误差。
finalLayers = [conv2dLayer regressionLayer('Name','FinalRegressionLayer')];
连接所有图层以形成vdsr网络。
layers = [firstLayer middleLayers finalLayers];
或者,也可以使用此帮助器函数创建vdsr图层。
layers = vdsrLayers();
指定培训选项
利用随机梯度下降和动量(sgdm)优化训练网络。使用功能指定sdgm的超参数设置。 trainingOptions 学习率最初设置为0.1,然后每20个时代下降10倍。火车100个世纪。
培训深入的网络是很耗时的。通过指定较高的学习率来加快培训。但是,这可能会导致网络的渐变无法控制地爆炸或增长,从而阻止网络成功培训。若要将渐变保持在有意义的范围内,请通过将'GradientThreshold'设置为0.01启用渐变剪辑,并指定'GradientThresholdMethod'以使用渐变的l2范数。
maxEpochs = 100;
epochIntervals = 1;
initLearningRate = 0.1;
learningRateFactor = 0.1;
l2reg = 0.0001;
options = trainingOptions('sgdm',...
'Momentum',0.9,...
'InitialLearnRate',initLearningRate,...
'LearnRateSchedule','piecewise',...
'LearnRateDropPeriod',10,......
' LearnRateDropFactor',learningRateFactor,......
'L2Regularization',l2reg,......
'MaxEpochs',maxEpochs,......
'MiniBatchSize',miniBatchSize,......
'GradientThresholdMethod','l2norm',......
'情节' ,'训练进步',...
'GradientThreshold',0.01);
培训网络
在配置了训练选项和随机补丁提取数据存储后,使用trainNetwork网络功能对vdsr网络进行培训。若要训练网络,请将下面代码中的doTraining参数设置为true。高度推荐具有cvida™以上计算能力的nvidia™依照gpu进行培训。
如果将下面代码中的doTraining参数保留为false,则该示例返回一个预先训练的vdsr网络,该网络已经过训练,可以针对比例因子2,3和4进行超级解析。
Note: Training takes about 6 hours on an NVIDIA™ Titan X and can take even longer depending on your GPU hardware.
doTraining = false;
如果做训练
modelDateTime = datestr(现在,'dd-mmm-yyyy-HH-MM-SS');
net = trainNetwork(patchds,layers,options);
save([ 'trainedVDSR- 'modelDateTime' -Epoch- 'num2str(maxEpochs * epochIntervals)'ScaleFactors- 'num2str(234)' 。 mat ' ],'net','options');
else
load('trainedVDSR-Epoch-100-ScaleFactors-234.mat');
结束
使用vdsr网络执行单个图像超分辨率
要使用vdsr网络执行单个图像超分辨率(sisr),请按照本示例的其余步骤操作。该示例的其余部分演示如何:
-
从高分辨率参考图像创建低分辨率图像示例。
-
使用双双插值在低分辨率图像上执行sisr,这是一种传统的图像处理解决方案,不依赖深度学习。
-
使用vdsr神经网络在低分辨率图像上执行sisr。
-
利用双插值和vdsr对重建的高分辨率图像进行目视比较。
-
通过量化图像与高分辨率参考图像的相似性来评价超分辨图像的质量。
创建低分辨率图像示例
创建一个低分辨率的图像,将用于比较超分辨率的结果使用深度学习与结果的结果使用传统的图像处理技术,如双双插值。测试数据集testimages testImages包含图像处理工具箱™中附带的21个未变形的图像。将图像加载到imageDatastore中。
exts = { '.jpg','。png' };
fileNames = { 'sherlock.jpg','car2.jpg','fabric.png','greens.jpg','hands1.jpg','kobi.png',...
'lighthouse.png','micromarket .jpg','office_4.jpg','onion.png','pears.png','yellowlily.jpg',...
'indiancorn.jpg','flamingos.jpg','sevilla.jpg',' llama.jpg','parkavenue.jpg',...
'peacock.jpg','car1.jpg','strawberries.jpg','wagon.jpg' };
filePath = [fullfile(matlabroot,'toolbox','images','imdata')filesep];
filePathNames = strcat(filePath,fileNames);
testImages = imageDatastore(filePathNames,'FileExtensions',exts);
将测试图像显示为蒙太奇。
蒙太奇(testImages)

选择要用作超分辨率参考图像的图像之一。您可以选择使用自己的高分辨率图像作为参考图像。
indx = 1; %要从测试图像数据存储区读取的图像索引 Ireference = readimage(testImages,indx); Ireference = im2double(Ireference); imshow(Ireference) 标题('高分辨率参考图像')

使用缩放系数为0.25的大小调整来创建高分辨率参考图像的低分辨率版本。 imresize 在缩小缩放过程中,图像的高频分量将丢失。
scaleFactor = 0.25; Ilowres = imresize(Ireference,scaleFactor,'bicubic'); imshow(Ilowres) 标题('低分辨率图像')

使用双参联提高图像分辨率
在没有深度学习的情况下提高图像分辨率的标准方法是使用双插值。使用双双插值对低分辨率图像进行升级,使生成的高分辨率图像的大小与参考图像的大小相同。
[nrows,ncols,np] = size(Ireference); Ibicubic = imresize(Ilowres,[nrows ncols],'bicubic'); imshow(Ibicubic) 标题('使用双立方插值获得的高分辨率图像')

使用预先培训的vdsr网络提高图像分辨率
回想一下,vdsr只使用图像的亮度通道进行训练,因为人类感知对亮度变化比对颜色变化更敏感。
使用函数将低分辨率图像从rgb颜色空间转换为亮度()和色度(和)通道。 rgb2ycbcr IyIcbIcr
Iycbcr = rgb2ycbcr(Ilowres); Iy = Iycbcr(:,:,1); Icb = Iycbcr(:,:,2); Icr = Iycbcr(:,:,3);
使用双双插值放大亮度和两个色度通道。上采样的色度通道icb _ Icb_bicubic和Icr_bicubic不需要进一步处理。
Iy_bicubic = imresize(Iy,[nrows ncols],'bicubic'); Icb_bicubic = imresize(Icb,[nrows ncols],'bicubic'); Icr_bicubic = imresize(Icr,[nrows ncols],'bicubic');
通过训练有素的vdsr网络,通过放大的亮度组件,Iy_bicubic亮度组件。观察从最后一层(回归层)激活 activations 网络的输出是所需的剩余图像。
Iresidual =激活(net,Iy_bicubic,41); Iresidual = double(Iresidual); imshow(Iresidual,[]) 标题(来自VDSR的残留图像)

将剩余图像添加到向上的亮度组件,以获得高分辨率的vdsr亮度组件。
Isr = Iy_bicubic + Iresidual;
将高分辨率vdsr亮度组件与向上扩展的颜色组件连接在一起。使用函数将图像转换为rgb颜色空间。 ycbcr2rgb 其结果是使用vdsr的最终高分辨率彩色图像。
Ivdsr = ycbcr2rgb(cat(3,Isr,Icb_bicubic,Icr_bicubic)); imshow(Ivdsr) 标题('使用VDSR获得的高分辨率图像')

视觉和定量比较
要更好地直观地了解高分辨率图像,请检查每个图像内的一个小区域。使用[ x y宽高度]格式的矢量指定感兴趣的区域(roi)。 roi 这些元素定义左上角的x和y坐标,以及roi的宽度和高度。
roi = [320 30 480 400];
将高分辨率图像裁剪到此roi,并以以太太奇的身份显示结果。
蒙太奇({imcrop(Ibicubic,ROI),imcrop(Ivdsr,ROI)})
标题('使用双立方插值的高分辨率结果(左)与VDSR(右)');

vdsr图像具有更清晰的细节和更清晰的边缘。
使用图像质量指标,使用对vdsr图像的双双插值对高分辨率图像进行定量比较。参考图像是原始的高分辨率图像Ireference,,在准备样品低分辨率图像之前。
针对参考图像测量每个图像的峰值信噪比(psnr)。较大的pnsr值通常表示图像质量更好。有关此指标的详细信息,请参阅。 psnr
bicubicPSNR = psnr(Ibicubic,Ireference)
bicubicPSNR = 38.4747
vdsrPSNR = psnr(Ivdsr,Ireference)
vdsrPSNR = 39.2491
测量每个图像的结构相似性指数(ssim).ssim评估图像的三个特征(亮度,对比度和结构)对参考图像的视觉影响.ssim值越接近1,测试图像与参考图像的一致就越好。有关此指标的详细信息,请参阅。 ssim
bicubicSSIM = ssim(Ibicubic,Ireference)
bicubicSSIM = 0.9861
vdsrSSIM = ssim(Ivdsr,Ireference)
vdsrSSIM = 0.9875
利用自然性图像质量评估器(niqe)测量感知图像质量。较小的niqe分数表明有更好的感知质量。有关此指标的详细信息,请参阅。 niqe
bicubicNIQE = niqe(Ibicubic)
bicubicNIQE = 5.1719
vdsrNIQE = niqe(Ivdsr)
vdsrNIQE = 4.7015
计算比例因子2,3和4的整个测试图像集的平均psnr和ssim。这些是用于定义随机修补Datastore相同比例因子。为简单起见,您可以使用帮助器函数超级superResolutionMetrics计算平均指标。
superResolutionMetrics(净,testImages,比例因子);
比例因子2的结果 Bicubic的平均PSNR = 31.809683 VDSR的平均PSNR = 31.926088 Bicubic的平均SSIM = 0.938194 VDSR的平均SSIM = 0.949278 比例因子3的结果 Bicubic的平均PSNR = 28.170441 VDSR的平均PSNR = 28.515179 Bicubic的平均SSIM = 0.884381 VDSR的平均SSIM = 0.895356 比例因子4的结果 Bicubic的平均PSNR = 27.010839 VDSR的平均PSNR = 27.849618 Bicubic的平均SSIM = 0.861604 VDSR的平均SSIM = 0.877360
对于每个比例因子,与双次插值相比,vdsr具有更好的度量分数。
总结
本示例演示如何针对多个比例因子创建和训练vdsr网络,然后使用该网络通过超分辨率提高图像分辨率。以下是培训网络的步骤:
-
下载培训数据。
-
将定义训练数据提供给网络的
RandomPatchExtractionDatastore数据存储。 -
定义vdsr网络的层。
-
指定培训选项。
-
使用
trainNetwork功能培训网络。
在培训vdsr网络或加载预训练的vdsr网络后,该示例对低分辨率映像执行超分辨率。该实例将vdsr结果与超分辨率进行了比较,使用双双插值,不使用深度学习.vdsr在感知图像质量和定量质量测量方面优于双双值插值。
引用
[1] “使用非常深的卷积网络的精确图像超分辨率.ieee 学报计算机视觉和模式识别会议。2016年,1646-1654页。 ®
[2] “iepr tc-12基准:视觉信息系统的新评估资源。基于内容的图像检索的2006年语言资源论文集。意大利热那亚第5卷,2006年5月,第10页。
[3]“深入到整流器:在imagenet分类上超越人的水平表现.ieee 计算机视觉国际会议论文集,2015年,1026-1034页。