汇编语言学习---寻址方式在结构化数据访问中的应用
一、实验目的
(1)了解汇编语言的程序结构,编写一个较简单的完整汇编程序;
(2)理解寻址方式的意义。
二、实验内容
Power idea公司从1975年成立到1995年的基本情况如下:
年份 收入(千美元) 雇员(人) 人均收入(千美元)
1975 16 4 ?
1976 22 7 ?
1977 382 10 ?
1978 1356 13 ?
1979 2390 28 ?
1980 8000 38 ?
……
1995 5937000 17800 ?
下面的代码中,已经定义好了这些数据:
assume cs:codesg
data segment
db '1975','1976','1977','1978','1979',1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21个字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140317,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上表示21年公司总收入的21个dword型数据
dw 4,7,10,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年公司雇员人数的21个word型数据
data ends
table segment
db 21 dup ('year summ ne ??')
table ends
编程,将data段中的数据按如下格式写入到table段中,并计算21年中的人均收入(取整),结果也按照下面的格式保存在table段中。
|
|
年份(4字节) |
空格 |
收入(4字节) |
空格 |
雇员数 (2字节) |
空格 |
人均收入(2字节) |
空格 |
||||||||
| 行内 地址 1年 占1行, 每行的起始地址 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
| table:0 |
‘1975’ |
|
16 |
|
3 |
|
? |
|
||||||||
| table:10H |
‘1976’ |
|
22 |
|
7 |
|
? |
|
||||||||
| table:20H |
‘1977’ |
|
382 |
|
10 |
|
? |
|
||||||||
| table:30H |
‘1978’ |
|
1356 |
|
13 |
|
? |
|
||||||||
| table:40H |
‘1979’ |
|
2390 |
|
28 |
|
? |
|
||||||||
| table:50H |
‘1980’ |
|
8000 |
|
38 |
|
? |
|
||||||||
|
|
||||||||||||||||
| table:140H |
‘1995’ |
|
5937000 |
|
17800 |
|
? |
|
||||||||
注1:实验中需要进行21次类似操作,故需要使用Loop指令来实现循环结构,循环次数默认存放在cx寄存器中。例如,要计算2的20次方,其具体格式如下:
mov ax, 2
mov cx, 19
s: add ax,ax
loop s
注2:计算人均收入需要使用div指令。Div指令格式如下:
Div 寄存器/内存单元(除数的存放地址)
被除数默认存放在AX(或DX和AX)中。如果除数为16位,被除数为32位,则被除数存放在DX和AX中,其中DX存放高16位,AX存放低16位。同时AX存放除法操作的商,DX存放除法操作的余数。例如:
div word ptr ES:[0]
需要注意的是,在对内存单元的访问中,使用word ptr(属性修改运算符PTR)来指明访问的内存单元是字单元。若使用 byte ptr,则说明访问的是字节单元。
三、实验要求
1、使用emu8086中的exe模板编写程序,要求编码规范,注释清晰。在程序中选择合适的寻址方式来访问data段和table段的数据;
2、在emu8086中调试运行程序,并使用【single step】功能单步执行该程序,观察每执行一条命令后寄存器内容的变化情况,体会各个寄存器的作用。程序运行完毕后,选择菜单【view】【memory】,在“Random Access Memory”界面中查看相应内存区域的值,检查程序的运算结果正确与否。并将table段所在内存的值截图。
实验完成情况:
assume cs:code,es:data,ds:table
data segment
year db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21个字符串
income dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140317,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上表示21年公司总收入的21个dword型数据
empl dw 4,7,10,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年公司雇员人数的21个word型数据
ends
table segment
db 21 dup ('year summ ne ?? ') ;最后这里像实验要求的内容一样,需要留出一个空格
table ends
code segment
start:
mov ax,table
mov ds,ax
mov ax,data
mov es,ax
mov cx,21 ;设置循环次数
mov si,0 ;table
mov di,0 ;year,income
mov bx,0 ;empl,average
;mov bp,0 ;empl
;将年份移入table中
s:mov ax,es:year[di]
mov ds:[si],ax
mov ax,es:year[di+2]
mov ds:[si+2],ax
;将收入移入table中
mov ax,es:income[di]
mov ds:[si+5],ax
mov ax,es:income[di+2]
mov ds:[si+7],ax
;将雇员数移到table中
mov ax,es:empl[bx]
mov ds:[si+10],ax
;计算人均收入,存入table中
mov dx,es:income[di+2] ; 被除数为32位 dx存放高16位
mov ax,es:income[di] ; ax存放低16位
div word ptr es:income[di]
mov ds:[si+13],ax
add si,10H
add di,4
add bx,2
loop s
mov ax, 4c00h ; exit to operating system.
int 21h
ends
end start ; set entry point and stop the assembler.
1.在开头有assume语句声明段在那个段寄存器里面
2.由于ax仅仅能存放16位2个字接所以需要分两次将年份的高两位和低两位分别传进table表中
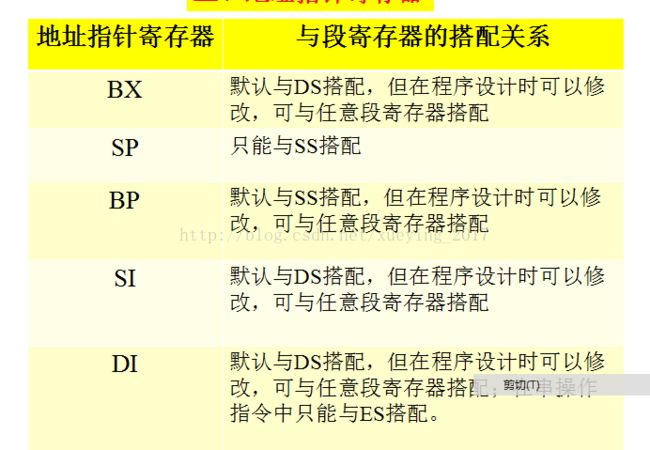
3.di默认与ds搭配,所以需要以 es:income[di]来访问data中的income
4.在使用除法的时候,若被除数是32位的话,需要将高16位存放在dx,低16位存放在ax中。在内存中,想像一个图,从上到下地址逐渐升高,由低地址向高地址存数,当一个数占32位的时候,高位存放在高地址。