改进版基于Spark2.2使用Spark SQL和mysql数据库进行诗歌查询及自动集句
上一篇博客中,使用的Spark版本是1.6,有点过时了,所以就采用最新的Spark2.2版本,并使用MySql数据库,
对诗歌查询和自动集句的功能进行了改进。
在Spark2.2中,最显著的变化是同样基于SparkConf构建的SparkSession取代了原来的SparkContext:
//初始化spark
def initSpark(appName:String){
val conf = new SparkConf().setMaster("local").setAppName(appName)
ss = SparkSession.builder().appName("Spark大数据集句").config(conf).getOrCreate()
}
然后就可以直接使用jdbc的load方法把数据库的数据加载到DataFrame:
@transient
var df = ss.read.format("jdbc")
.option("url", com.magicstudio.db.Constants.DB_URL)
.option("dbtable", "poem_list") //必须写表名
.load()
var df = ss.read.format("jdbc")
.option("url", com.magicstudio.db.Constants.DB_URL)
.option("dbtable", "poem_list") //必须写表名
.load()
而不像在1.6版中,要先创建一个根据数据库ResultSet创建JdbcRDD row的函数,然后把数据加载到JdbcRDD中,
然后根据数据库栏位先定义出StructType(),再利用这个StructType把JdbcRDD转换为DataFrame。
相比之下,Spark2.2的做法简洁多了。
但是要注意的是有两点:
第一,此时获取id之类的数据整型的方法,由getString变成了row.getInt(0).toString();
第二,DataFrame join时,被join的参数由DataFrame变成了DataSet:
dfPoem.join(dfContent.asInstanceOf[Dataset[_]], dfPoem("id") === dfContent("poem_id"))
另外,Spark1.6时,可以使用Scala10.6编译,Scala 语言library自动引入scala-libray.jar,scala-reflect.jar和scala-swing.jar,
并且提供了SparkSql在内的统一的spark-assembly-1.6.0-hadoop2.6.0.jar,所以只需再引入sqlite数据库的驱动sqlite-jdbc-3.7.2.jar
就可以了:
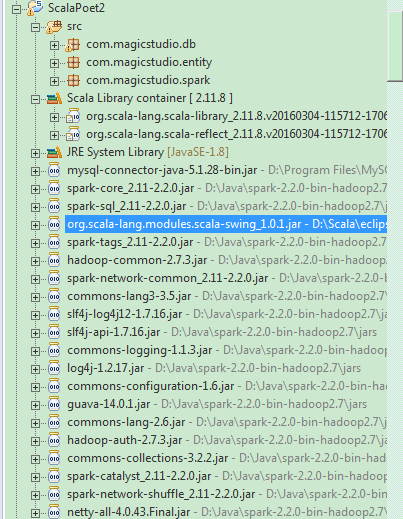
但是使用Spark2.2,就没那么幸运了。首先要使用Scala2.11.8,语言自带的library只有library和reflect两个,swing需要
自己手工浏览添加;然后就是没有了统一的spark-assembly的jar档,需要把spark-2.2.0-bin-hadoop2.7解压目录中jars里面的
jar档全部 加入,才不会出现jar档的依赖引用缺失。当然要使用mysql数据库,mysql的驱动jar必不可少:
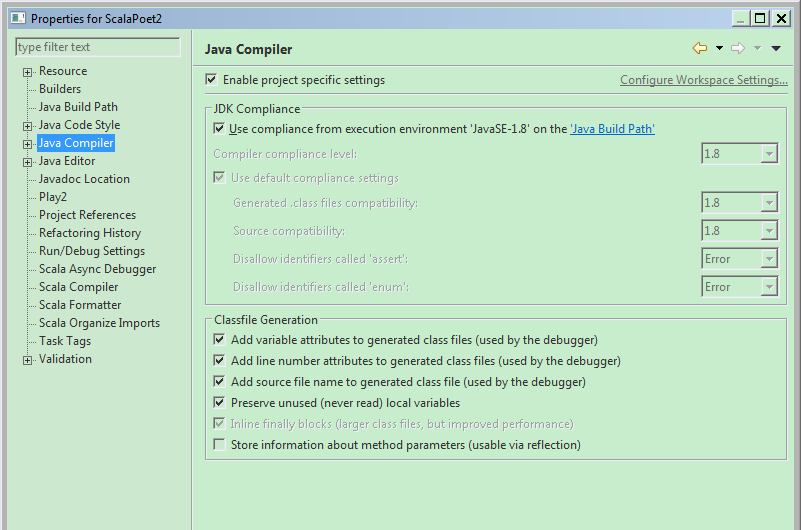
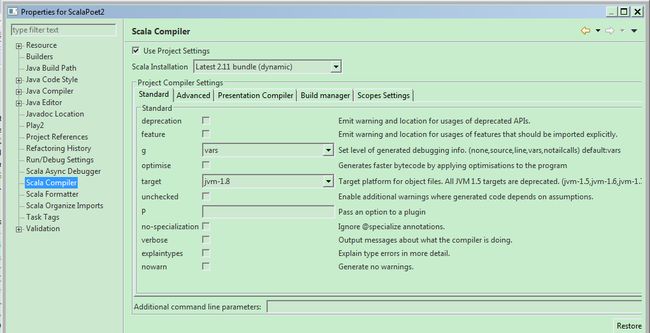
另外,还要注意的是,spark2.2应该是在jdk1.8的版本下编译的,所以,需要安装jdk1.8,并设定Java Compiler和
Scala Compiler都使用1.8的版本:
否则,会出现
java.lang.UnsupportedClassVersionE
rror: PR/Sort : Unsupported major.minor version 52.0这个错误。
另外的改进,是在导入数据到mysql中时,提前获取诗句的叶韵和句式,这样在集句时效率会好一些,因而
实际的集句功能的代码也有相应修改。但是由于导入了全唐诗和全宋诗,数据量比较大,所以其实改进的效果
并不明显。而且在查询或集句时,如果结果数据量过多,会出现不能连接到数据库的错误:
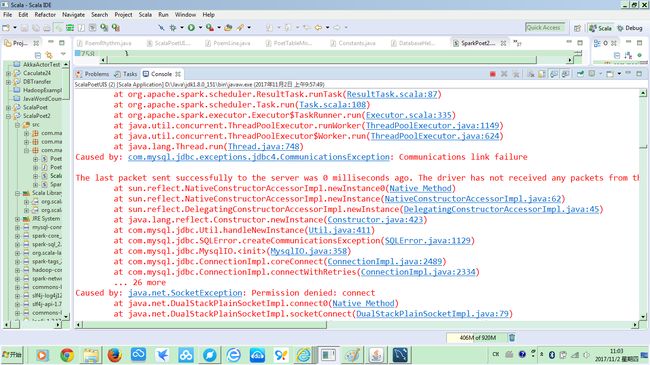
根据错误提示的信息:
Driver stacktrace:
at java.security.AccessController.doPrivileged(Native Method)
at java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:80)
at java.awt.EventQueue.dispatchEvent(EventQueue.java:728)
at java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:201)
at java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:116)
at java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:105)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:93)
at java.awt.EventDispatchThread.run(EventDispatchThread.java:82)
Caused by: java.security.PrivilegedActionException: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 8717.0 failed 1 times, most recent failure: Lost task 0.0 in stage 8717.0 (TID 9312, localhost, executor driver): com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.Util.getInstance(Util.java:386)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1015)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:989)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:975)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:920)
at com.mysql.jdbc.ConnectionImpl.connectWithRetries(ConnectionImpl.java:2395)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2316)
at com.mysql.jdbc.ConnectionImpl.(ConnectionImpl.java:834)
at com.mysql.jdbc.JDBC4Connection.(JDBC4Connection.java:47)
at sun.reflect.GeneratedConstructorAccessor36.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:416)
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:347)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:61)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:52)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute(JDBCRDD.scala:286)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
at java.security.AccessController.doPrivileged(Native Method)
at java.security.ProtectionDomain$JavaSecurityAccessImpl.doIntersectionPrivilege(ProtectionDomain.java:80)
at java.awt.EventQueue.dispatchEvent(EventQueue.java:728)
at java.awt.EventDispatchThread.pumpOneEventForFilters(EventDispatchThread.java:201)
at java.awt.EventDispatchThread.pumpEventsForFilter(EventDispatchThread.java:116)
at java.awt.EventDispatchThread.pumpEventsForHierarchy(EventDispatchThread.java:105)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:101)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:93)
at java.awt.EventDispatchThread.run(EventDispatchThread.java:82)
Caused by: java.security.PrivilegedActionException: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 8717.0 failed 1 times, most recent failure: Lost task 0.0 in stage 8717.0 (TID 9312, localhost, executor driver): com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.Util.getInstance(Util.java:386)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1015)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:989)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:975)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:920)
at com.mysql.jdbc.ConnectionImpl.connectWithRetries(ConnectionImpl.java:2395)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2316)
at com.mysql.jdbc.ConnectionImpl.
at com.mysql.jdbc.JDBC4Connection.
at sun.reflect.GeneratedConstructorAccessor36.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:416)
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:347)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:61)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:52)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute(JDBCRDD.scala:286)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1129)
at com.mysql.jdbc.MysqlIO.(MysqlIO.java:358)
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2489)
at com.mysql.jdbc.ConnectionImpl.connectWithRetries(ConnectionImpl.java:2334)
... 26 more
Caused by: java.net.SocketException: Permission denied: connect
at java.net.DualStackPlainSocketImpl.connect0(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:79)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at java.net.Socket.connect(Socket.java:538)
at java.net.Socket.(Socket.java:434)
at java.net.Socket.(Socket.java:244)
at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:256)
at com.mysql.jdbc.MysqlIO.(MysqlIO.java:308)
... 28 more
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:1129)
at com.mysql.jdbc.MysqlIO.
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2489)
at com.mysql.jdbc.ConnectionImpl.connectWithRetries(ConnectionImpl.java:2334)
... 26 more
Caused by: java.net.SocketException: Permission denied: connect
at java.net.DualStackPlainSocketImpl.connect0(Native Method)
at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:79)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at java.net.Socket.connect(Socket.java:538)
at java.net.Socket.
at java.net.Socket.
at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:256)
at com.mysql.jdbc.MysqlIO.
... 28 more
修改mysql连接的等待时间,或者调大max connections的数量设置,都无法解决这个问题。为了避免出现这个问题,
后来只导入了唐诗三百,全唐诗和宋诗三百,并且加上了集句数量的限制:
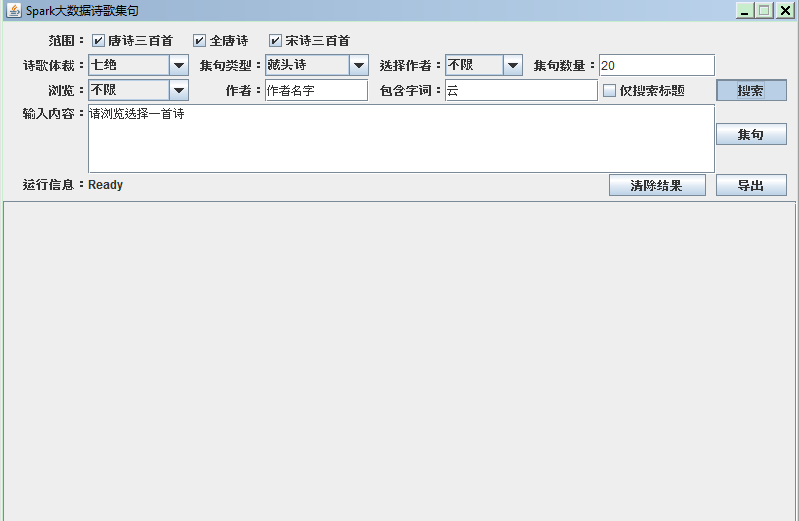
数据过少,会导致集句不完整;数据太多又会导致性能无法忍受,而且可能报错。这个mysql connection的问题还希望精通SparkSQL的同好能给以指导解决。
当然,要使用mysql数据库,首先本地要安装mysql数据库,我选择的是mysql-5.6.16-winx64.msi,创建的数据库是spark_poet:
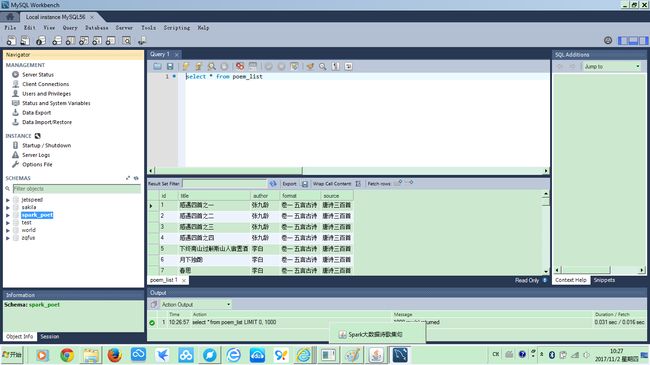
可以使用导出的文件直接导入数据,也可以使用DataManager中的方法,从文本文件生成数据库。
工程代码已经上传到CSDN: 下载源码
欢迎各位Spark高手不吝赐教。