联通大数据5000台规模集群故障自愈实践
本文转载自dbaplus社群
作者介绍
余澈,中国联通大数据技术部平台组核心技术负责人,项目管理高级工程师,具有多年大数据平台运维管理及开发优化经验。管理过多个上千节点集群,擅长对外多租户平台的维护开发。信科院大数据性能测试、功能测试主力,大厂PK获得双项第一。
背景
作为运维人员,做得最多的工作就是日常巡检、故障恢复。公司集群规模越庞大,故障发生率和故障实例数也在成倍增加。每天来到公司,第一件事儿就是要看看有哪些机器坏了?坏哪儿了?集群存储还够吗?底层数据存储是否均衡?然后针对每个故障逐一解决。笔者亲身经历就是过年连懒觉都睡不成,集群故障了,一个电话过来立马清醒,然后默默地恢复故障。这样的经历我觉得每个运维人都含着泪经历过。
改变
通过采集分析Prometheus里的告警数据,利用fabric或ansible等多线程安全并发远程连接工具,执行相关角色实例的恢复工作。

fabric建立连接执行恢复命令。

目前集群规模将近5000台,其中两个大规模的集群节点数均为一千多台。
目前自动化恢复涉及的集群日常运维操作有:
计算节点检测出使用swap交换分区,将会自动清理swap分区并关闭swap分区;
计算节点检测出时钟偏差,将会自动纠偏时钟偏差;
Cloudera Manager 代理挂掉,将会自动重启;
主机检测出有坏盘,坏盘更换完成后,自动恢复;
角色实例检测出异常掉线,自动恢复上线(如NameNode、DataNode、ResourceManager、NodeManager等);
集群存在多个节点多块磁盘存储剩余空间不足,自动进行磁盘级别的数据Balancer;
集群存储达到阈值,自动进行节点级别的数据Balancer。
自动化恢复的适用场景很多,但一定要做到严谨地对症下药,并且要考虑清楚问题的严重性和普遍性。
以上7点自动恢复是集群常见故障,该类故障频发且影响范围较小,并不会影响集群的可用性,因此可以实施自动化恢复。
对于平台罕见故障,且该故障有一定概率会对平台造成部分功能性能影响的,最好的办法是做好告警和应急处理。
下面分享几个自动化恢复实践:
1)计算节点检测出使用swap交换分区,将会自动清理swap分区并关闭swap分区。
根据监控数据,获取swap开启的计算机点,远程连接进行swap分区关闭。
def recover_HOST_MEMORY_SWAPPING(self,list):
com=("swapoff -a")
for i in range(len(list)):
con = Connection(list[i]['ipAddress'], port=22, user=user, connect_timeout=360, forward_agent=True,
connect_kwargs={'password': self.password})
con.sudo(command=com,password=self.password,shell=False,hide='stderr',encoding='utf-8',pty=True)
con.close()
2)Cloudera Manager 代理挂掉,将会自动重启。
根据监控数据,获取agent异常下线的计算节点,远程连接进行agent上线操作。
def recover_HOST_SCM_HEALTH(self,list):
com=("/opt/cm-5.13.1/etc/init.d/cloudera-scm-agent restart")
for i in range(len(list)):
con = Connection(list[i]['ipAddress'], port=22, user=user, connect_timeout=360, forward_agent=True,
connect_kwargs={'password': self.password})
con.sudo(command=com,password=self.password,shell=False,hide='stderr',encoding='utf-8',pty=True)
con.close()
3)计算节点检测出时钟偏差,将会自动纠偏时钟偏差。
由于集群资源每天有将近16小时处于打满状态,容易造成集群部分计算节点负载过高,导致节点上的DN、NM掉线。这时候需要重启计算节点,但重启节点会造成机器时钟偏差,通过监控告警我们检测到了时钟偏差,接下来通过读取Prometheus中的时钟偏差节点信息,来进行时钟源同步操作。

具体时钟偏差恢复的代码实例如下:
from fabric import Connection
def recover_HOST_CLOCK_OFFSET(self,list):
com=["systemctl stop ntpd","ntpdate ntp_src","sleep 1","ntpdate ntp_src","sleep 1","ntpdate ntp_src","sleep 1","systemctl start ntpd","/opt/cm-5.13.1/etc/init.d/cloudera-scm-agent restart"]
for i in range(len(list)):
con = Connection(list[i]['ipAddress'], port=22, user=user, connect_timeout=360, forward_agent=True,
connect_kwargs={'password': self.password})
for j in range(len(com)):
con.sudo(command=com[j], password=self.password, shell=False, hide='stderr', encoding='utf-8', pty=True)
con.close()
4)集群角色异常退出。
如下图:监控告警发现NodeManager实例发生故障实践在2019-08-12 04:28:02,一般这个时间段,运维人员都在深度睡眠。这时自愈程序将根据告警自动恢复角色实例,恢复实践周期在5分钟之内,于2019-08-12 04:32:02 DN实例和NM实例恢复上线。


当前集群使用的CDH5.13.1版本,可以直接通过CM_API实现角色实例自愈,如果是手工搭建版本,可以使用fabric或者Paramiko连接到节点启动相应角色实例。
「CM_API使用说明」参考链接:https://cloudera.github.io/cm_api/docs/python-client-swagger/
具体DN角色自愈代码如下:
import cm_client
api_url = api_host + ':' + port + '/api/' + api_version
api_client = cm_client.ApiClient(api_url)
cluster_api_instance = cm_client.ClustersResourceApi(api_client)
# Lists all known clusters.
api_response = cluster_api_instance.read_clusters(view='SUMMARY')
for cluster in api_response.items:
print (cluster.name, "-", cluster.full_version)
if cluster.full_version.startswith("5."):
services_api_instance = cm_client.ServicesResourceApi(api_client)
services = services_api_instance.read_services(cluster.name, view='FULL')
for service in services.items:
#print (service.name)
if service.type == 'HDFS':
hdfs = service
if cluster.full_version.startswith("5."):
roles_api_instance = cm_client.RolesResourceApi(api_client)
//根据集群名称,服务实例名称获取相对应的角色实例列表
role_response = roles_api_instance.read_roles(cluster.name, hdfs.name, view='FULL')
//获取状态为bad的dn角色实例(手工搭建集群可以通过读取prometheus的告警数据进行掉线角色实例的恢复。)
bad_dn_roles = [role.name for role in role_response.items if (role.type == 'DATANODE' and role.health_summary == 'BAD')]
roles_cmd_api_instance = cm_client.RoleCommandsResourceApi(api_client)
role_names = cm_client.ApiRoleNameList(bad_dn_roles)
//重启角色实例
cmd_list = roles_cmd_api_instance.restart_command(cluster.name, hdfs.name, body=role_names)
for cmd in cmd_list.items:
print (cmd.name, "(", cmd.id, cmd.active, cmd.success, ")")
执行完成后,返回执行结果:

5)集群个别节点上的磁盘存储超过90%的阈值。
背景:集群节点数过多后,默认的数据落盘策略为轮训,由于部分节点存储异构,会导致有部分节点存储打满,这时我们可以修改数据落盘策略为剩余空间策略,即根据节点剩余存储空间的多少来决定数据优先落盘的顺序。
但是,即使这样解决了节点存储的均衡,也不能解决个别磁盘的存储打满,在Apache社区的Hadoop3版本中dfs.disk.balancer才可以使用。在CDH5.13.1的Hadoop2.6.0版本,已经可以使用该功能。但是磁盘何时快打满无法预测,并且在大规模集群中,往往多了一个账期的数据,就会有大量的磁盘达到存储告警阈值。当HDFS集群单节点内部多块数据硬盘数据倾斜时,会造成热点硬盘使用量激增,甚至打满,此时集群balance是无用的,就需要用DiskBalancer,这时我们就可以根据告警信息来自动化的进行磁盘数据均衡。
开启方法:
修改hdfs-site.xml文件。

true表示开启DiskBalancer。
命令:
hdfs diskbalancer -[command] [options]
command:
1.plan(制定平衡计划)
可执行参数:
--bandwidth
--out
--v:输出计划
2.execute(执行计划)
3.query(查询进度)
4.cancel(取消计划)
实例:
DN节点lf-319-sq210发生数据倾斜。
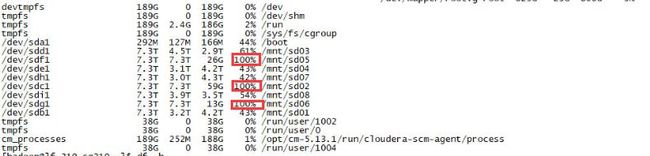
登陆到lf-319-sq210主机,切换至HDFS用户。
制定平衡计划:
hdfs diskbalancer -plan lf-319-sq210.plan.json --out ~/2019-Jul-20-15-25-29 --thresholdPercentage 10

执行平衡计划:
hdfs diskbalancer -execute /var/lib/hadoop-hdfs/2019-Jul-20-15-25-29/lf-319-sq210.plan.json
![]()
查询计划:
hdfs diskbalancer -query lf-319-sq210

圈中部分为正在进行,PLAN_DONE为完成。
过一段时间观察lf-319-sq210磁盘情况:

可以清晰的看出,磁盘已经开始平衡了。
以上是磁盘级别的数据平衡操作步骤,以下是通过fabric进行远程命令的执行,以实现自动化恢复。
def recover_DATA_NODE_FREE_SPACE_REMAINING(self,list):
com=("su hdfs -c 'whoami;export JAVA_HOME=/opt/jdk;export CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH;export PATH=$JAVA_HOME/bin:$PATH;hdfs diskbalancer -plan $HOSTNAME.plan.json --out ~/`date \'+diskbalancer_%Y_%m_%d\'` --thresholdPercentage 10;sleep 5;hdfs diskbalancer -execute /var/lib/hadoop-hdfs/`date \'+diskbalancer_%Y_%m_%d\'`/$HOSTNAME.plan.json'")
for i in range(len(list)):
con = Connection(list[i]['ipAddress'], port=22, user=user, connect_timeout=360, forward_agent=True,
connect_kwargs={'password': self.password})
con.sudo(command=com,password=self.password,shell=False,hide='stderr',encoding='utf-8',pty=True)
con.close()
集群自愈也是大规模集群治理工作的一项重要环节,遵循降本增效、安全至上的原则,能减少运维人员的大量常规工作量,也能及时有效地恢复故障,减少小故障引发集群大事故的可能性。
![]()
从过去40年至今,数据库的形态基本经历了传统商业数据库、开源数据库到云原生数据库的演进过程。云时代下数据库将如何革新与创变?金融行业核心数据库迁移与建设如何安全平稳展开?来Gdevops全球敏捷运维峰会北京站寻找答案:
《All in Cloud 时代,下一代云原生数据库技术与趋势》阿里巴巴集团副总裁/达摩院首席数据库科学家 李飞飞(飞刀)
《AI和云原生时代的数据库进化之路》腾讯数据库产品中心总经理 林晓斌(丁奇)
《ICBC的MySQL探索之路》工商银行软件开发中心 魏亚东
《金融行业MySQL高可用实践》爱可生技术总监 明溪源
《民生银行在SQL审核方面的探索和实践》民生银行 资深数据库专家 李宁宁
《OceanBase分布式数据库在西安银行的落地和实践》蚂蚁金服P9资深专家/OceanBase核心负责人 蒋志勇
让我们9月11日在北京共同眺望数据库发展变革更长远的未来!
