charCNN、textCNN、BI-lstm、textRNN
一、charCNN
1. 要解决什么问题
2.模型结构与设计思想(为什么这样设计)

二、textCNN
1. 要解决什么问题
输入一个[sequence, embedding_size]句子,对其进行分类;
2.模型结构与设计思想(为什么这样设计)

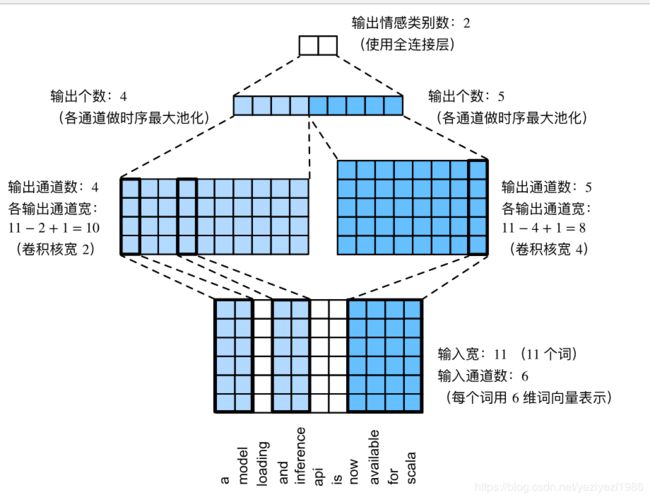
textCNN模型主要使用了一维卷积层和时序最大池化层。假设输入的文本序列由n个词组成,每个词用d维的词向量表示。那么输入样本的宽度为n,高为1,输入通道数为d。textCNN的计算主要分为以下几步:
1) 一维卷积:
操作:定义多个一维卷积核,并使用这些卷积核对输入分别做卷积计算。
意义:每一次卷积操作相当于一次特征向量的提取,通过定义不同的窗口,就可以提取出不同的特征向量,构成卷积层的输出。
2)时序最大池化:
操作:对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连结为向量。
意义:达到的效果都是将不同长度的句子通过池化得到一个定长的向量表示。
3)通过全连接层将连结后的向量变换为有关各类别的输出。这一步可以使用丢弃层对应过拟合。
3. TextCNN的超参数调参
首先,我们默认的TextCNN模型超参数一般都是这种配置,如下表:
| Description | Values |
| 输入词向量:词向量表征的选取(如选word2vec还是Glove) | Word2vec |
| filter大小:一个合理的取值范围在1-10。若语料中的句子较长,可以考虑使用更大的卷积核。另外,可以在寻找到了最佳filter大小后,尝试在该filter的尺寸值附近寻找其他合适值来进行组合。实践证明这样的组合效果往往更出色 | (3,4,5) |
| 每个size下的filter个数: | 100 |
| 激活函数 | ReLU |
| 池化策略 | 1-max pooling |
| dropout rate | 0.5 |
| L2正则化 | 3 |
4. 输入输出tensor是怎样的shape,最终输出是什么
三、BI-LSTM
2.模型结构与设计思想(为什么这样设计)
1. 要解决什么问题
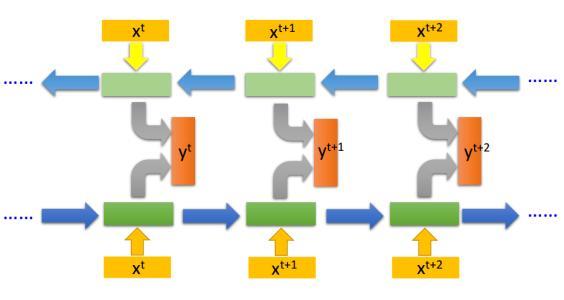
3. 参考资料
https://zhuanlan.zhihu.com/p/47802053
四、textRNN
1. 什么是textRNN
指的是利用RNN神经网络解决文本分类问题,文本分类是NLP的一个基本任务,试图推断出给定文本的标签或集合。
文本分类的应用非常广泛,如:
1)垃圾邮件分类:2分类问题,判断邮件是否为垃圾邮件;
2)情感分析:2分类问题,判断文本情感是积极还是消极;多分类问题:判断文本情感属于{非常消极、消极、中立、积极、非常积极}中的哪一类。
3)新闻主题分类:判断一段新闻属于哪个类别,如财经、体育、娱乐等。
4)社区问答系统中的问题分类:多标签多分类(对一段文本进行多分类,该文本可能有多个标签)
5)让AI做法官:基于按键事实描述文本的罚金等级分类(多分类)和发条分类(多标签多分类)
6)判断新闻是否为机器人所写:2分类
2. textRNN的原理
1)首先我们需要对文本进行分词,然后指定一个序列长度n(大于n的截断,小于n的填充),并使用词嵌入得到每个词固定维度的向量表示;
2)对每个输入序列,我们可以在RNN的每一个时间步长上输入文本中一个单词的向量表示,计算当前时间步长上的隐藏状态,然后用于当前时间步骤的输出,以及传递给下一个时间步长,并和下一个单词的词向量一起作为RNN单元输入,然后再计算下一个时间步长上RNN的隐藏状态,以此重复...直到处理完输入文本中的每一个单词,由于输入文本的长度n,所有要经历n个时间步长。
基于RNN的文本分类模型非常灵活,有多种多样的结构。主要介绍两种典型的结构。
3. textRNN模型结构
3.1 structure 1
流程:embedding --> BiLSTM --> concat final output/average all output --> softmax layer
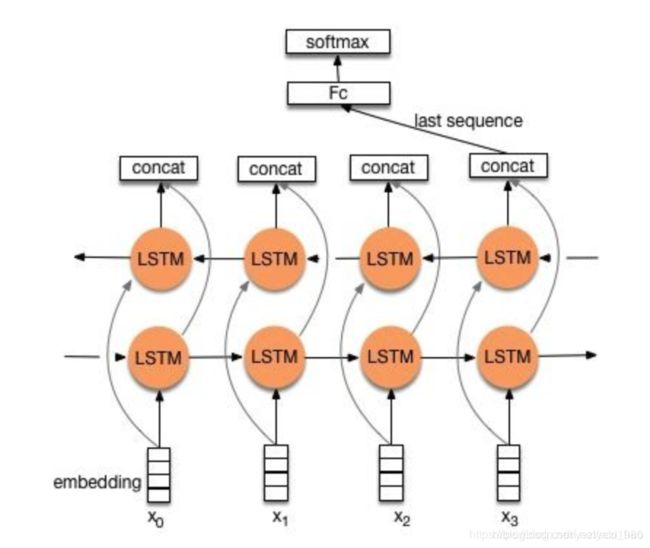
一般取前向/反向LSTM在最后一个时间步长上的隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行一个多分类;或者取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层。
上述结构也可以添加dropout/L2正则化或BatchNormalization来防止过拟合以及加速模型训练
3.2 structrue 2
流程:embedding --> BiLSTM --> (dropout) --> concat output --> UniLSTM --> (dropout) --> softmax layer
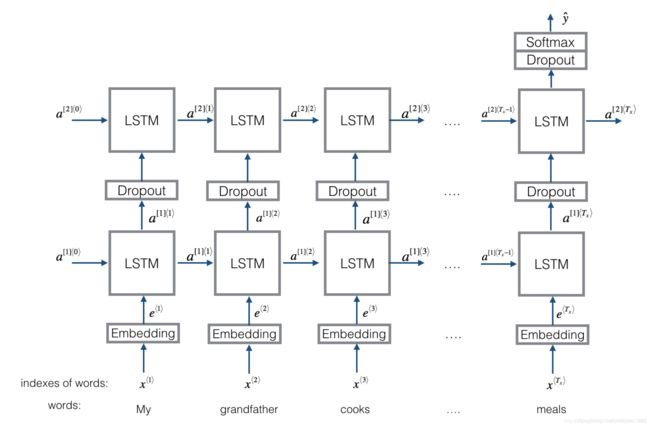
与之前结构不同的是,在双向LSTM(上图不太准确,底层应该是一个双向LSTM)的基础上又堆叠了一个单向的LSTM。把双向LSTM在每一个时间步长上的两个隐藏状态进行拼接,作为上层单向LSTM每个时间步长上的一个输入,最后取上层单向LSTM最后一个时间步长上的隐藏状态,再结果一个softmax层(2分类则使用sigmoid)进行多分类。
TextRNN的结构非常灵活,可以任意改变。比如把LSTM单元替换为GRU,把双向改为单向,添加dropout或BN以及再多堆叠一层等等。但RNN的训练速度相对偏慢,一般2层就已经足够多了。
对于TextRNN的结构,也有如下两种说法:
1)模型流程
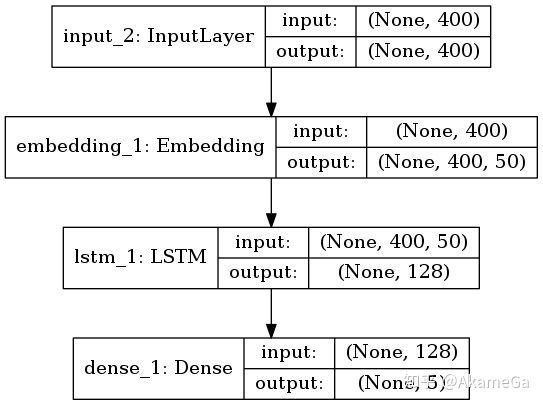
输入层:将每个词从onehot类型embedding成稠密的词向量,句子的词语个数设为400,每个词语50维的embedding维度。对于不同长度的文本,pad和截断成一样长度的。太短的就补空格,太长的就截断。
LSTM:设定输出的维度为128维向量,LSTM其实对每个词语都会有一个隐向量,这里是用最后一个词语ht作为最终使用的隐向量,可以看做是包含了前面所有词语的信息,因此该层输出是128维向量。
2)Bi-LSTM
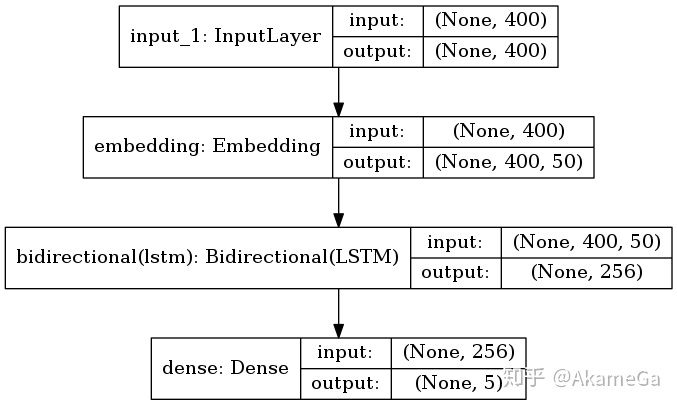
BI-LSTM是LSTM的改进版本,将单向RNN结构改成了双向RNN,希望不仅能考虑正向编码信息,也能考虑反向编码信息。
与LSTM不同的是,在rnn部分使用了Bi-LSTM进行信息提取,Bi-LSTM层中,内部有两个LSTM,分别是Forward层和Backard层,表示前向和后向,每个LSTM设定输出的维度为128维向量,在Forward层从1时刻到t时刻正向计算一遍,得到并保存每个时刻向前隐含层的输出。最后在每个时刻结合Forward层和Backward层的相应时刻输出的结果进行拼接得到最终的输出。因此输出的维度为256维。