在ubuntu上搭建hadoop服务 (集群模式)
环境:ubuntu 16.04
hadoop-3.0.3
参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
1.参考上一篇“在Ubuntu上搭建Hadoop服务(单机模式)”
1.1.安装JDK,配置Java环境;
1.2.创建hadoop组、hadoop用户;
1.3.配置SSH无密码登陆;
1.4.克隆虚拟机
在虚拟机关闭状态,选择克隆;
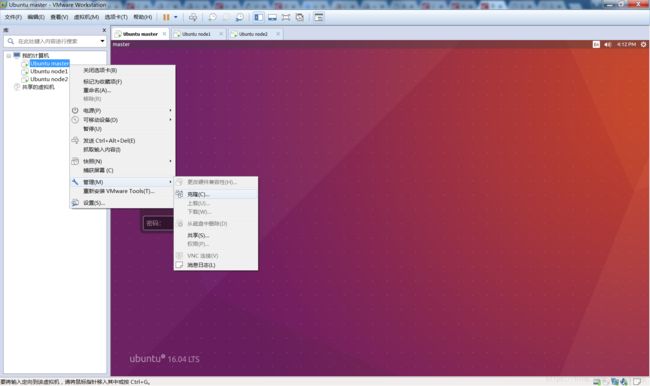
配置:
都使用桥接模式;
宿主机:
192.168.1.102
虚拟机:
192.168.1.106 master
192.168.1.104 node1
192.168.1.105 node2
2.修改各个虚拟机的hostname,hosts
sudo vi /etc/hostname
依次修改为master,node1,node2



sudo vi /etc/hosts
把以下内容添加到3台机子的hosts文件中
192.168.1.106 master
192.168.1.104 node1
192.168.1.105 node2
3.配置SSH远程无密码登录
把master上的公钥文件,拷贝到node1,node2上;
scp ~/.ssh/authorized_keys hadoop@node1:~/.ssh/
scp ~/.ssh/authorized_keys hadoop@node2:~/.ssh/
【TODO 或者,使用ssh-copy-id命令,比较便捷】
在node1,node2上修改文件权限;
chmod 600 ~/.ssh/authorized_keys
然后,在master上,可以免密SSH登录node1,node2
ssh node1
ssh node2
(因为另外两台机子是克隆的,所以已经配置了本地SSH无密码登录)
(并且,三台机子的公钥、私钥也是一样的,所以,实际上是不需要拷贝的)
4.配置Hadoop
在master机子上;
创建目录
mkdir /usr/local/hadoop/dfs
mkdir /usr/local/hadoop/dfs/name
mkdir /usr/local/hadoop/dfs/data
mkdir /usr/local/hadoop/tmp
进入hadoop目录
cd /usr/local/hadoop
修改./etc/hadoop中的配置文件
sudo vi ./etc/hadoop/ hadoop-env.sh添加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
sudo vi ./etc/hadoop/ core-site.xml
添加如下内容:
sudo vi ./etc/hadoop/ hdfs-site.xml
添加如下内容:
dfs.replication:副本个数,默认是3
dfs.namenode.secondary.http-address:为了保证整个集群的可靠性secondarnamenode配置在其他机器比较好
dfs.http.address:进入hadoop web UI的端口
sudo vi ./etc/hadoop/ mapred-site.xml
添加如下内容:
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
sudo vi ./etc/hadoop/ yarn-site.xml
添加如下内容:
sudo vi ./etc/hadoop/ workers
清空文件,添加如下内容:
node1
node2
把上面在master上配置好的hadoop环境,整体复制到node1,node2上;
scp -r /usr/local/hadoop hadoop@node1:/usr/local/hadoop
scp -r /usr/local/hadoop hadoop@node2:/usr/local/hadoop
或者,只复制6个配置文件;
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml hadoop@node1:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/mapred-site.xml hadoop@node1:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml hadoop@node1:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@node1:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/hadoop-env.sh hadoop@node1:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/workers hadoop@node1:/usr/local/hadoop/etc/hadoop
5.在master上启动hadoop
cd /usr/local/hadoop
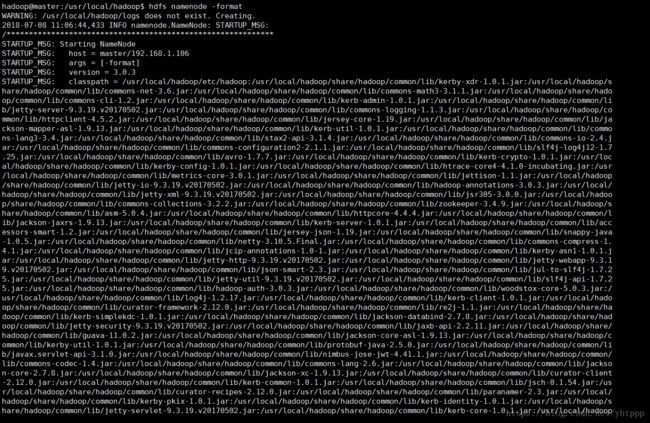
./bin/hdfs namenode -format
./sbin/start-all.sh 【这种启动方式好像不推荐使用,参照官方文档换一下】

启动HDFS:start-dfs.sh
![]()
启动Yarn:start-yarn.sh
(注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn)

使用jps查看master,node上的进程



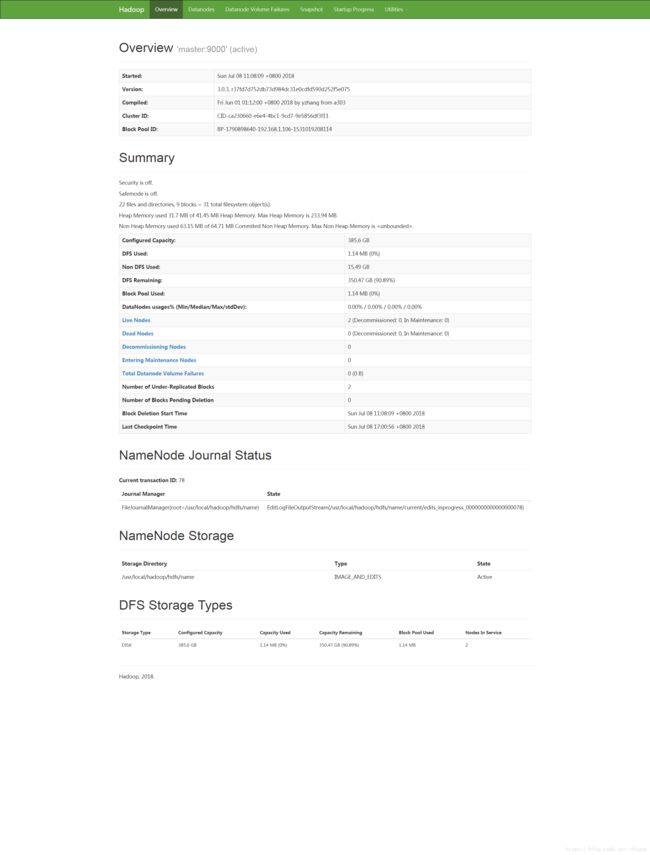
查看web 界面
http://192.168.1.106:50070
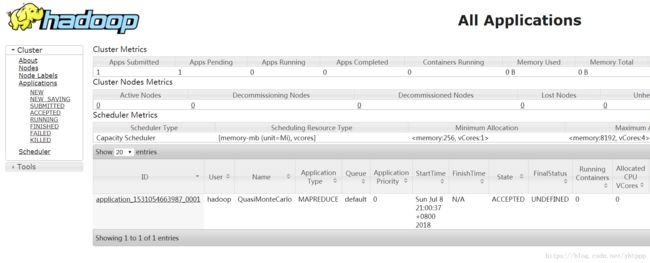
http://192.168.1.106:8099/cluster
停止hadoop;
./sbin/stop-all.sh

6.测试
使用自带的example测试
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar pi 1 1
参考:
https://www.cnblogs.com/frankdeng/p/9047698.html
https://blog.csdn.net/xiaoxiangzi222/article/details/52757168/
https://blog.csdn.net/qq_32808045/article/details/76229157