栈溢出从入门到放弃(下)
转自https://zhuanlan.zhihu.com/p/25892385
0x00 写在前面
首先还是广播一下2017 Pwn2Own 大赛的最终赛果,本次比赛共发现51个漏洞,长亭安全实验室贡献11个,以积26分的总成绩,在11支参赛团队中名列第三!同时,也祝贺国内的安全团队包揽本次大赛的前三名!
0x10 上期回顾
上篇文章介绍了栈溢出的原理和两种执行方法,两种方法都是通过覆盖返回地址来执行输入的指令片段(shellcode)或者动态库中的函数(return2libc)。本篇会继续介绍另外两种实现方法。一种是覆盖返回地址来执行内存内已有的代码片段(ROP),另一种是将某个函数的地址替换成另一个函数的地址(hijack GOT)。
0x20 相关知识
0x21 寄存器
在上篇的背景知识中,我们提到了函数状态相关的三个寄存器--esp,ebp,eip。下面的内容会涉及更多的寄存器,所以我们大致介绍下寄存器在执行程序指令中的不同用途。
32位x86架构下的寄存器可以被简单分为通用寄存器和特殊寄存器两类,通用寄存器在大部分汇编指令下是可以任意使用的(虽然有些指令规定了某些寄存器的特定用途),而特殊寄存器只能被特定的汇编指令使用,不能用来任意存储数据。
32位x86架构下的通用寄存器包括一般寄存器(eax、ebx、ecx、edx),索引寄存器(esi、edi),以及堆栈指针寄存器(esp、ebp)。
一般寄存器用来存储运行时数据,是指令最常用到的寄存器,除了存放一般性的数据,每个一般寄存器都有自己较为固定的独特用途。eax 被称为累加寄存器(Accumulator),用以进行算数运算和返回函数结果等。ebx 被称为基址寄存器(Base),在内存寻址时(比如数组运算)用以存放基地址。ecx 被称为记数寄存器(Counter),用以在循环过程中记数。edx 被称为数据寄存器(Data),常配合 eax 一起存放运算结果等数据。
索引寄存器通常用于字符串操作中,esi 指向要处理的数据地址(Source Index),edi 指向存放处理结果的数据地址(Destination Index)。
堆栈指针寄存器(esp、ebp)用于保存函数在调用栈中的状态,上篇已有详细的介绍。
32位x86架构下的特殊寄存器包括段地址寄存器(ss、cs、ds、es、fs、gs),标志位寄存器(EFLAGS),以及指令指针寄存器(eip)。
现代操作系统内存通常是以分段的形式存放不同类型的信息的。我们在上篇谈及的函数调用栈就是分段的一个部分(Stack Segment)。内存分段还包括堆(Heap Segment)、数据段(Data Segment),BSS段,以及代码段(Code Segment)。代码段存储可执行代码和只读常量(如常量字符串),属性可读可执行,但通常不可写。数据段存储已经初始化且初值不为0的全局变量和静态局部变量,BSS段存储未初始化或初值为0的全局变量和静态局部变量,这两段数据都有可写的属性。堆用于存放程序运行中动态分配的内存,例如C语言中的 malloc() 和 free() 函数就是在堆上分配和释放内存。各段在内存的排列如下图所示。

Fig1. 内存分段的典型布局
段地址寄存器就是用来存储内存分段地址的,其中寄存器 ss 存储函数调用栈(Stack Segment)的地址,寄存器 cs 存储代码段(Code Segment)的地址,寄存器 ds 存储数据段(Data Segment)的地址,es、fs、gs 是附加的存储数据段地址的寄存器。
标志位寄存器(EFLAGS)32位中的大部分被用于标志数据或程序的状态,例如 OF(Overflow Flag)对应数值溢出、IF(Interrupt Flag)对应中断、ZF(Zero Flag)对应运算结果为0、CF(Carry Flag)对应运算产生进位等等。
指令指针寄存器(eip)存储下一条运行指令的地址,上篇已有详细的介绍。
0x22 汇编指令
为了更好地理解后面的内容,一点点汇编语言的知识也是必要的,本节会介绍一些基础指令的含义。32位x86架构下的汇编语言有 Intel 和 AT&T 两种格式,本文所用汇编指令都是 Intel 格式。两者最主要的差别如下。Intel 格式,寄存器名称和数值前无符号:
“指令名称 目标操作数 DST,源操作数 SRC”
AT&T 格式,寄存器名称前加“%”,数值前加“$”:
“指令名称 源操作数 SRC,目标操作数 DST”一些最常用的汇编指令如下:
- MOV:数据传输指令,将 SRC 传至 DST,格式为
MOV DST, SRC; - PUSH:压入堆栈指令,将 SRC 压入栈内,格式为
PUSH SRC; - POP:弹出堆栈指令,将栈顶的数据弹出并存至 DST,格式为
POP DST; - LEA:取地址指令,将 MEM 的地址存至 REG ,格式为
LEA REG, MEM; - ADD/SUB:加/减法指令,将运算结果存至 DST,格式为
ADD/SUB DST, SRC; - AND/OR/XOR:按位与/或/异或,将运算结果存至 DST ,格式为
AND/OR/XOR DST,SRC; - CALL:调用指令,将当前的 eip 压入栈顶,并将 PTR 存入 eip,格式为
CALL PTR; - RET:返回指令,操作为将栈顶数据弹出至 eip,格式为
RET;
介绍完以上背景知识,就可以继续栈溢出技术之路了。
0x30 ROP ( Return Oriented Programming )
--修改返回地址,让其指向内存中已有的一段指令
根据上面副标题的说明,要完成的任务包括:在内存中确定某段指令的地址,并用其覆盖返回地址。可是既然可以覆盖返回地址并定位到内存地址,为什么不直接用上篇提到的 return2libc 呢?因为有时目标函数在内存内无法找到,有时目标操作并没有特定的函数可以完美适配。这时就需要在内存中寻找多个指令片段,拼凑出一系列操作来达成目的。假如要执行某段指令(我们将其称为“gadget”,意为小工具),溢出数据应该以下面的方式构造(padding 长度和内容的确定方式参见上篇):
payload : padding + address of gadget

Fig 2. 包含单个 gadget 的溢出数据
如果想连续执行若干段指令,就需要每个 gadget 执行完毕可以将控制权交给下一个 gadget。所以 gadget 的最后一步应该是 RET 指令,这样程序的控制权(eip)才能得到切换,所以这种技术被称为返回导向编程( Return Oriented Programming )。要执行多个 gadget,溢出数据应该以下面的方式构造:
payload : padding + address of gadget 1 + address of gadget 2 + ......
+ address of gadget n
在这样的构造下,被调用函数返回时会跳转执行 gadget 1,执行完毕时 gadget 1 的 RET 指令会将此时的栈顶数据(也就是 gadget 2 的地址)弹出至 eip,程序继续跳转执行 gadget 2,以此类推。

Fig 3. 包含多个 gadget 的溢出数据
现在任务可以分解为:针对程序栈溢出所要实现的效果,找到若干段以 ret 作为结束的指令片段,按照上述的构造将它们的地址填充到溢出数据中。所以我们要解决以下几个问题。
首先,栈溢出之后要实现什么效果?
ROP 常见的拼凑效果是实现一次系统调用,Linux系统下对应的汇编指令是 int 0x80。执行这条指令时,被调用函数的编号应存入 eax,调用参数应按顺序存入 ebx,ecx,edx,esi,edi 中。例如,编号125对应函数
mprotect (void *addr, size_t len, int prot)
,可用该函数将栈的属性改为可执行,这样就可以使用 shellcode 了。假如我们想利用系统调用执行这个函数,eax、ebx、ecx、edx 应该分别为“125”、内存栈的分段地址(可以通过调试工具确定)、“0x10000”(需要修改的空间长度,也许需要更长)、“7”(RWX 权限)。
其次,如何寻找对应的指令片段?
有若干开源工具可以实现搜索以 ret 结尾的指令片段,著名的包括 ROPgadget、rp++、ropeme 等,甚至也可以用 grep 等文本匹配工具在汇编指令中搜索 ret 再进一步筛选。搜索的详细过程在这里就不再赘述,有兴趣的同学可以参考上述工具的说明文档。
最后,如何传入系统调用的参数?
对于上面提到的 mprotect 函数,我们需要将参数传输至寄存器,所以可以用 pop 指令将栈顶数据弹入寄存器。如果在内存中能找到直接可用的数据,也可以用 mov 指令来进行传输,不过写入数据再 pop 要比先搜索再 mov 来的简单,对吧?如果要用 pop 指令来传输调用参数,就需要在溢出数据内包含这些参数,所以上面的溢出数据格式需要一点修改。对于单个 gadget,pop 所传输的数据应该在 gadget 地址之后,如下图所示。
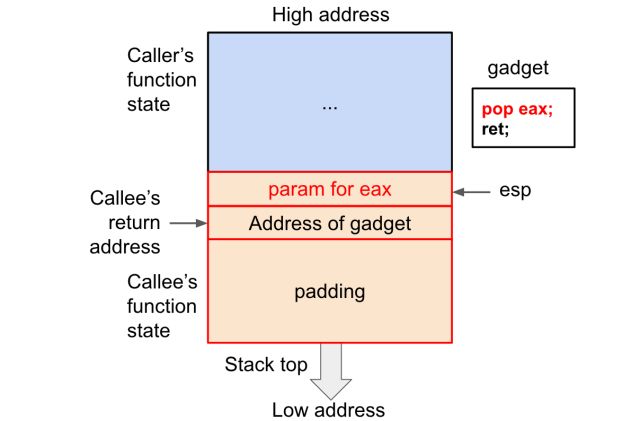
Fig 4. gadget “pop eax; ret;”
在调用 mprotect() 为栈开启可执行权限之后,我们希望执行一段 shellcode,所以要将 shellcode 也加入溢出数据,并将 shellcode 的开始地址加到 int 0x80 的 gadget之后。但确定 shellcode 在内存的确切地址是很困难的事(想起上篇里面艰难试探的过程了吗?),我们可以使用 push esp 这个 gadget(加入可以找到的话)。

Fig 5. gadget “push esp; ret;”
我们假设现在内存中可以找到如下几条指令:
pop eax; ret; # pop stack top into eax
pop ebx; ret; # pop stack top into ebx
pop ecx; ret; # pop stack top into ecx
pop edx; ret; # pop stack top into edx
int 0x80; ret; # system call
push esp; ret; # push address of shellcode
对于所有包含 pop 指令的 gadget,在其地址之后都要添加 pop 的传输数据,同时在所有 gadget 最后包含一段 shellcode,最终溢出数据结构应该变为如下格式。
payload : padding + address of gadget 1 + param for gadget 1 + address of gadget 2 + param for gadget 2 + ...... + address of gadget n + shellcode

Fig 6. 包含多个 gadget 的溢出数据(修改后)
此处为了简单,先假定输入溢出数据不受“\x00"字符的影响,所以 payload 可以直接包含 “\x7d\x00\x00\x00”(传给 eax 的参数125)。如果希望实现更为真实的操作,可以用多个 gadget 通过运算得到上述参数。比如可以通过下面三条 gadget 来给 eax 传递参数。
pop eax; ret; # pop stack top 0x1111118e into eax
pop ebx; ret; # pop stack top 0x11111111 into ebx
sub eax, ebx; ret; # eax -= ebx
解决完上述问题,我们就可以拼接出溢出数据,输入至程序来为程序调用栈开启可执行权限并执行 shellcode。同时,由于 ROP 方法带来的灵活性,现在不再需要痛苦地试探 shellcode 起始地址了。回顾整个输入数据,只有栈的分段地址需要获取确定地址。如果利用 gadget 读取 ebp 的值再加上某个合适的数值,就可以保证溢出数据都具有可执行权限,这样就不再需要获取确切地址,也就具有了绕过内存随机化的可能。
出于演示的目的,我们假设(简直是钦点)了所有需要的 gadget 的存在。在实际搜索及拼接 gadget 时,并不会像上面一样顺利,有两个方面需要注意。
第一,很多时候并不能一次凑齐全部的理想指令片段,这时就要通过数据地址的偏移、寄存器之间的数据传输等方法来“曲线救国”。举个例子,假设找不到下面这条 gadget
pop ebx; ret;
但假如可以找到下面的 gadget
mov ebx, eax; ret;
我们就可以将它和
pop eax; ret;
组合起来实现将数据传输给 ebx 的功能。上面提到的用多个 gadget 避免输入“\x00”也是一个实例应用。
第二,要小心 gadget 是否会破坏前面各个 gadget 已经实现的部分,比如可能修改某个已经写入数值的寄存器。另外,要特别小心 gadget 对 ebp 和 esp 的操作,因为它们的变化会改变返回地址的位置,进而使后续的 gadget 无法执行。
0x40 Hijack GOT
--修改某个被调用函数的地址,让其指向另一个函数
根据上面副标题的说明,要完成的任务包括:在内存中修改某个函数的地址,使其指向另一个函数。为了便于理解,不妨假设修改 printf() 函数的地址使其指向 system(),这样修改之后程序内对 printf() 的调用就执行 system() 函数。要实现这个过程,我们就要弄清楚发生函数调用时程序是如何“找到”被调用函数的。
程序对外部函数的调用需要在生成可执行文件时将外部函数链接到程序中,链接的方式分为静态链接和动态链接。静态链接得到的可执行文件包含外部函数的全部代码,动态链接得到的可执行文件并不包含外部函数的代码,而是在运行时将动态链接库(若干外部函数的集合)加载到内存的某个位置,再在发生调用时去链接库定位所需的函数。
可程序是如何在链接库内定位到所需的函数呢?这个过程用到了两张表--GOT 和 PLT。GOT 全称是全局偏移量表(Global Offset Table),用来存储外部函数在内存的确切地址。GOT 存储在数据段(Data Segment)内,可以在程序运行中被修改。PLT 全称是程序链接表(Procedure Linkage Table),用来存储外部函数的入口点(entry),换言之程序总会到 PLT 这里寻找外部函数的地址。PLT 存储在代码段(Code Segment)内,在运行之前就已经确定并且不会被修改,所以 PLT 并不会知道程序运行时动态链接库被加载的确切位置。那么 PLT 表内存储的入口点是什么呢?就是 GOT 表中对应条目的地址。
Fig 7. PLT 和 GOT 表

等等,我们好像发现了一个不合理的地方,外部函数的内存地址存储在 GOT 而非 PLT 表内,PLT 存储的入口点又指向 GOT 的对应条目,那么程序为什么选择 PLT 而非 GOT 作为调用的入口点呢?在程序启动时确定所有外部函数的内存地址并写入 GOT 表,之后只使用 GOT 表不是更方便吗?这样的设计是为了程序的运行效率。GOT 表的初始值都指向 PLT 表对应条目中的某个片段,这个片段的作用是调用一个函数地址解析函数。当程序需要调用某个外部函数时,首先到 PLT 表内寻找对应的入口点,跳转到 GOT 表中。如果这是第一次调用这个函数,程序会通过 GOT 表再次跳转回 PLT 表,运行地址解析程序来确定函数的确切地址,并用其覆盖掉 GOT 表的初始值,之后再执行函数调用。当再次调用这个函数时,程序仍然首先通过 PLT 表跳转到 GOT 表,此时 GOT 表已经存有获取函数的内存地址,所以会直接跳转到函数所在地址执行函数。整个过程如下面两张图所示。
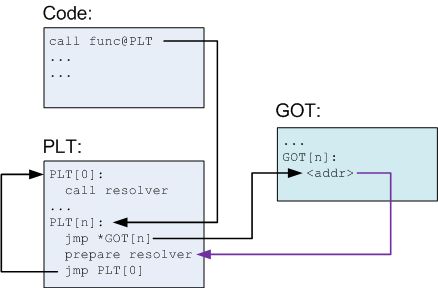
Fig 8. 第一次调用函数时解析函数地址并存入 GOT 表
Fig 9. 再次调用函数时直接读取 GOT 内的地址

上述实现遵循的是一种被称为 LAZY 的设计思想,它将需要完成的操作(解析外部函数的内存地址)留到调用实际发生时才进行,而非在程序一开始运行时就解析出全部函数地址。这个过程也启示了我们如何实现函数的伪装,那就是到 GOT 表中将函数 A 的地址修改为函数 B 的地址。这样在后面所有对函数 A 的调用都会执行函数 B。
那么我们的目标可以分解为如下几部分:确定函数 A 在 GOT 表中的条目位置,确定函数 B 在内存中的地址,将函数 B 的地址写入函数 A 在 GOT 表中的条目。
首先,如何确定函数 A 在 GOT 表中的条目位置?
程序调用函数时是通过 PLT 表跳转到 GOT 表的对应条目,所以可以在函数调用的汇编指令中找到 PLT 表中该函数的入口点位置,从而定位到该函数在 GOT 中的条目。
例如
call 0x08048430
就说明 printf 在 PLT 表中的入口点是在 0x08048430,所以 0x08048430 处存储的就是 GOT 表中 printf 的条目地址。
其次,如何确定函数 B 在内存中的地址?
如果系统开启了内存布局随机化,程序每次运行动态链接库的加载位置都是随机的,就很难通过调试工具直接确定函数的地址。假如函数 B 在栈溢出之前已经被调用过,我们当然可以通过前一个问题的答案来获得地址。但我们心仪的攻击函数往往并不满足被调用过的要求,也就是 GOT 表中并没有其真实的内存地址。幸运的是,函数在动态链接库内的相对位置是固定的,在动态库打包生成时就已经确定。所以假如我们知道了函数 A 的运行时地址(读取 GOT 表内容),也知道函数 A 和函数 B 在动态链接库内的相对位置,就可以推算出函数 B 的运行时地址。
最后,如何实现 GOT 表中数据的修改?
很难找到合适的函数来完成这一任务,不过我们还有强大的 ROP(DIY大法好)。假设我们可以找到以下若干条 gadget(继续钦点),就不难改写 GOT 表中数据,从而实现函数的伪装。ROP 的具体实现请回看上一章,这里就不再赘述了。
pop eax; ret; # printf@plt -> eax
mov ebx [eax]; ret; # printf@got -> ebx
pop ecx; ret; # addr_diff = system - printf -> ecx
add [ebx] ecx; ret; # printf@got += addr_diff
从修改 GOT 表的过程可以看出,这种方法也可以在一定程度上绕过内存随机化。
0x50 防御措施
介绍过几种栈溢出的基础方法,我们再来补充一下操作系统内有哪些常见的措施可以进行防御。首先,通常情况下程序在默认编译设置下都会取消栈上数据的可执行权限,这样简单的 shellcode 溢出攻击就无法实现了。其次,可以在操作系统内开启内存布局随机化(ASLR),这样可以增大确定堆栈内数据和动态库内函数的内存地址的难度。编译程序时还可以设置某些编译选项,使程序在运行时会在函数栈上的 ebp 地址和返回地址之间生成一个特殊的值,这个值被称为“金丝雀”(关于这个典故,请大家自行谷歌)。这样一旦发生了栈溢出并覆盖了返回地址,这个值就会被改写,从而实现函数栈的越界检查。最后值得强调的是,尽可能写出安全可靠的代码,不给栈溢出提供写入越界的可能。
0x60 全篇小结
本文简要介绍了栈溢出这种古老而经典的技术领域,并概括描述了四种入门级的实现方法。至此我们专栏的第一讲就全部结束啦,接下来专栏会陆续放出计算机安全相关的更多文章,内容也会涵盖网络安全、Web渗透、密码学、操作系统,还会有ctf 比赛题解等等......
最后感谢大家的关注,让我们一起学习,共同进步!
References:
-
《Hacking: Art of Exploitation》