深度学习之笑脸及口罩数据集的分类预测实验实验(仿猫狗数据集训练方法)
参考Python深度学习第5章第2节中的代码示例
目录
- 一、理解人脸图像特征提取的各种方法(至少包括HoG、Dlib和卷积神经网络特征)
- 二、掌握笑脸数据集(genki4k)正负样本的划分、模型训练和测试的过程(至少包括SVM、CNN),输出模型训练精度和测试精度(F1-score和ROC)
- 1、在小数据集上训练ConvNet
- 2、 深度学习与小数据问题的相关性
- 3、 数据集下载
- 4、 代码实现上述操作
- 5、 建立我们的关系网
- 6、 数据预处理
- 7、 使用数据增强
- 三、完成一个摄像头采集自己人脸、并对表情(笑脸和非笑脸)的实时分类判读(输出分类文字)的程序。
- 1、首先实现照片的判别
- 2、 摄像头采集人脸识别
- 四、 将笑脸数据集换成口罩数据集,完成对口罩佩戴与否的模型训练,采取合适的特征提取方法,重新做上述2-3步。
- 1、下载数据集
- 2、训练数据集
- 3、预测
一、理解人脸图像特征提取的各种方法(至少包括HoG、Dlib和卷积神经网络特征)
这个网上很多资料,可以自己去找来看。
二、掌握笑脸数据集(genki4k)正负样本的划分、模型训练和测试的过程(至少包括SVM、CNN),输出模型训练精度和测试精度(F1-score和ROC)
1、在小数据集上训练ConvNet
我们从零开始在小数据集上训练Convnet。
仅使用很少的数据来训练图像分类模型是一种常见的情况,如果你曾经在专业环境中做过计算机视觉,你可能会在实践中遇到这种情况。
拥有“少量”样本可能意味着从数百到数万张图像。作为一个实际的例子,我们将在包含4000张笑和没笑的图片(2000张笑的,2000没笑的)的数据集中把图像分类为“smile”或“unsmile”。我们将使用2000张图片进行培训,1000张用于验证,最后1000张用于测试。
在这个程序中,我们将回顾解决这个问题的一个基本策略:在我们仅有的少量数据的基础上从头开始训练一个新模型。我们将从天真地在我们的2000个训练样本上训练一个小convnet开始,没有任何规则化,为可以达到的目标设定一个基线。这将使我们的分类准确率达到71%。到那时,我们的主要问题将是过度拟合。然后我们将介绍数据增强技术,这是一种减轻计算机视觉中过度拟合的强大技术。通过利用数据扩充,我们将改进我们的网络,使准确率达到82%。
2、 深度学习与小数据问题的相关性
你有时会听说深度学习只有在有大量数据的时候才有效。这在一定程度上是有道理的:深度学习的一个基本特征是,它能够自己在训练数据中发现有趣的特征,而不需要任何手动特征工程,并且这只能在有大量训练实例可用时才能实现。对于输入样本非常高维的问题尤其如此,比如图像。
然而,构成“大量”样本的是相对的——首先,相对于你试图训练的网络的规模和深度。仅仅用几十个样本来训练一个convnet来解决一个复杂的问题是不可能的,但是如果这个模型很小并且规则性很好,并且任务很简单,那么几百个样本就足够了。因为convnets学习局部的、平移不变的特征,所以它们在感知问题上非常有效。在非常小的图像数据集上从头开始训练convnet仍然会产生合理的结果,尽管相对缺乏数据,不需要任何定制的特征工程。您将在本节中看到这一点。
但更重要的是,深度学习模型本质上是高度可重用的:你可以采取,比如说,在大规模数据集上训练的图像分类或语音到文本的模型,然后在一个明显不同的问题上重用它,只需要很小的改变。具体来说,在计算机视觉的情况下,许多预先训练的模型(通常在ImageNet数据集上训练)现在可以公开下载,并且可以用于从非常少的数据中引导强大的视觉模型。这就是我们下一节要做的。
现在,让我们从掌握数据开始。
3、 数据集下载
数据集就是网上通用的笑脸数据集。
找不到的也可以找我要数据集。
展示几张图片




不出所料,2013年猫狗Kaggle比赛的获胜者是使用convnets的参赛者。最佳输入可以达到95%的准确率。在我们自己的例子中,我们将相当接近这一精度(在下一节),尽管我们将在竞争对手可用数据的不到10%的情况下训练我们的模型。
4、 代码实现上述操作
首先需要下载tensorflow,然后再下载keras,然后就可以执行代码了。

运行tensorflow环境,可以看到我下载的是2.3.1版本的。
然后导包
![]()
读取训练集的图片,将训练数据和测试数据放入自己创建的文件夹

# The path to the directory where the original
# dataset was uncompressed
riginal_dataset_dir = 'C:\Users\Administrator\Desktop\genki4k'
# The directory where we will
# store our smaller dataset
base_dir = 'genki4k'
os.mkdir(base_dir)
# Directories for our training,
# validation and test splits
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# Directory with our training smile pictures
train_smile_dir = os.path.join(train_dir, 'smile')
os.mkdir(train_smile_dir)
# Directory with our training unsmile pictures
train_unsmile_dir = os.path.join(train_dir, 'unsmile')
#s.mkdir(train_dogs_dir)
# Directory with our validation smile pictures
validation_smile_dir = os.path.join(validation_dir, 'smile')
os.mkdir(validation_smile_dir)
# Directory with our validation unsmile pictures
validation_unsmile_dir = os.path.join(validation_dir, 'unsmile')
os.mkdir(validation_unsmile_dir)
# Directory with our validation smile pictures
test_smile_dir = os.path.join(test_dir, 'smile')
os.mkdir(test_smile_dir)
# Directory with our validation unsmile pictures
test_unsmile_dir = os.path.join(test_dir, 'unsmile')
os.mkdir(test_unsmile_dir)
运行完这个程序会生成一个文件夹,如果再次运行这个程序就会报错,因为已经有这个文件存在。然后我是自己把这些照片放进对应的文件里的,效果是一样的,也可以通过代码进行。
# Copy smile images to train_smile_dir
#fnames = ['smile.{}.jpg'.format(i) for i in range(1000)]
#for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(train_smile_dir, fname)
# shutil.copyfile(src, dst)
# Copy next 500 smile images to validation_smile_dir
#fnames = ['smile.{}.jpg'.format(i) for i in range(1000, 1500)]
#for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(validation_smile_dir, fname)
# shutil.copyfile(src, dst)
# Copy next 500 smile images to test_smile_dir
#fnames = ['smile.{}.jpg'.format(i) for i in range(1500, 2000)]
#for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(test_smile_dir, fname)
# shutil.copyfile(src, dst)
# Copy first 1000 unsmile images to train_unsmile_dir
#fnames = ['unsmile.{}.jpg'.format(i) for i in range(1000)]
#for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(train_unsmile_dir, fname)
# shutil.copyfile(src, dst)
# # Copy next 500 unsmile images to validation_unsmile_dir
# fnames = ['unsmile.{}.jpg'.format(i) for i in range(1000, 1500)]
# for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(validation_unsmile_dir, fname)
# shutil.copyfile(src, dst)
# # Copy next 500 unsmile images to test_dogs_dir
# fnames = ['unsmile.{}.jpg'.format(i) for i in range(1500, 2000)]
# for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(test_unsmile_dir, fname)
# shutil.copyfile(src, dst)
作为一个健全的检查,让我们数一数我们在每一次培训中有多少张图片(训练/验证/测试)

好像自己添加照片还是有点问题,不过无关大雅,所以我们有1800张训练图像,然后是900张验证图像和900张测试图像。在每个分类中,每个类别的样本数是相同的:这是一个平衡的二进制分类问题,这意味着分类的准确性将是衡量成功的适当尺度。
5、 建立我们的关系网
我们的ConvNet将是由交替的Conv2D(与relu激活)和MaxPooling2D层组成的堆栈。
然而,由于我们处理的是更大的图像和一个更复杂的问题,我们将相应地使我们的网络更大:它将有另外一个Conv2D+MaxPooling2D阶段。这既可以增强网络的容量,又可以进一步缩小功能地图的大小,这样当我们到达平坦层时,它们就不会太大。在这里,由于我们从150 x150大小的输入开始(这是一个任意的选择),我们最终得到大小为7x7的特征映射,就在扁平层之前。
请注意,功能映射的深度在网络中逐渐增加(从32增加到128),而功能映射的大小正在减少(从148 x148减少到7x7)。这是一个模式,你会看到几乎所有的凸网。
由于我们正在着力解决一个二进制分类问题,所以我们用一个单元(大小为1的稠密层)和乙状结肠激活来结束网络。这个单元将编码网络正在查看一个类或另一个类的概率。
建立模型:
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
让我们看一看功能映射的维度如何随每个连续层的变化而变化。
model.summary()

在编译步骤中,我们将一如既往地使用RMS螺旋桨优化器。由于我们用单个Sigmoid单元结束了我们的网络,所以我们将使用二进制交叉熵作为我们的损失。
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
6、 数据预处理
您现在已经知道,在输入到我们的网络之前,应该将数据格式化为适当的预处理浮点张量。目前,我们的数据以JPEG文件的形式存储在驱动器上,因此,将其输入网络的步骤大致如下:
- 读图片文件。
- 将JPEG内容解码为像素的RBG网格。
- 将它们转换为浮点张量。
- 将像素值(介于0到255之间)重新分配到[0,1]区间(如您所知,神经网络更喜欢处理小的输入值)。
这似乎有点令人望而生畏,但谢天谢地,Keras有实用程序可以自动处理这些步骤。Keras有一个带有图像处理辅助工具的模块,位于keras.预处理。特别是,它包含了ImageDataGenerator类,它允许快速设置Python生成器,这些生成器可以自动将磁盘上的图像文件转换为批量预处理的张量。这就是我们在这里要用的。
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')

让我们看看其中一个生成器的输出:它生成150×150 RGB图像的批次(Shape(20,150,150,3))和二进制标签(Shape(20,))。20是每批样品的数量(批次大小)。注意,生成器无限期地生成这些批:它只是无休止地循环目标文件夹中的图像。因此,我们需要在某个点中断迭代循环。
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break

让我们将模型与使用生成器的数据相匹配。我们使用了FIT_ENGINEER方法,这相当于对像我们这样的数据生成器的FIT。它期望第一个参数是Python生成器,它将无限期地产生批量输入和目标,就像我们的一样。由于数据是无休止地生成的,因此生成器需要知道要从生成器中抽取多少个示例,然后才能声明一个时代。这是STEP_PER_EIRCH参数的作用:在从生成器中提取步骤_PER_EURCH批之后,即在运行了步骤_PER_EURCH梯度下降步骤之后,拟合过程将进入下一个阶段。在我们的例子中,批次是20个样本,所以它将需要100批,直到我们看到我们的目标2000样本。
当使用FIT_generator时,可以通过验证_数据参数,这与FIT方法非常相似。重要的是,允许这个参数本身成为一个数据生成器,但它也可能是Numpy数组的一个元组。如果将生成器传递为Validation_Data,则预期此生成器将无休止地生成批验证数据,因此还应该指定ValidationSteps参数,该参数告诉验证生成器要从验证生成器中提取多少批进行评估。
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
这里要运行很久,可以去喝杯咖啡了。哈哈!!
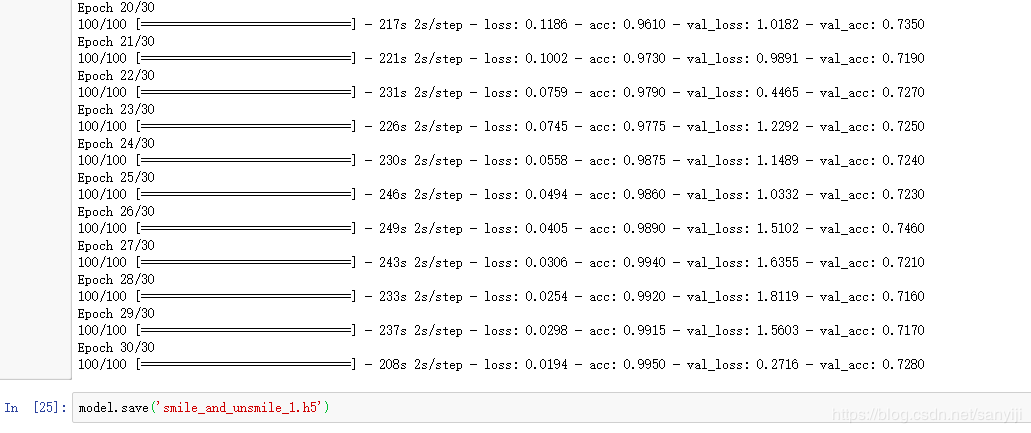
可以看到30个样本,因为我的电脑不行,一个样本大概就要用掉2-3分钟,咖啡都喝了十几杯了,终于跑完了。
好的做法是在训练后总是保存你的模型:
model.save('smile_and_unsmile_1.h5')
让我们在培训和验证数据上绘制模型的丢失和准确性:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
得到的结果:

这些地块具有过分拟合的特点。随着时间的推移,我们的训练精度呈线性增长,直到达到近100%,而我们的验证精度却停留在70-72%。我们的验证损失在仅仅5个时期之后就达到了最小值,而训练损失则一直线性地减少到接近0。
由于我们只有相对较少的培训样本(3000),过度适应将是我们的首要关注。您已经知道了一些可以帮助减轻过度适应的技术,如辍学和体重衰减(L2正则化)。我们现在将引入一种新的,专门用于计算机视觉,并几乎普遍使用时,处理图像的深度学习模型:数据增强。
7、 使用数据增强
过度拟合是由于样本太少而无法学习,使我们无法训练一个能够推广到新数据的模型。给定无限的数据,我们的模型将暴露于手头数据分布的每一个可能的方面:我们永远不会过火。数据增强的方法是从现有的训练样本中生成更多的训练数据,通过一些随机变换来“增强”样本,从而产生可信的图像。目标是在训练的时候,我们的模型永远不会看到完全相同的图片两次。这有助于模型了解数据的更多方面,并更好地概括。
在Keras中,可以通过配置要对ImageDataGenerator实例读取的图像执行的随机转换来实现这一点。让我们从一个例子开始:
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
这些只是可用的几个选项(有关更多信息,请参见Keras文档)。让我们快速回顾一下我们刚才写的内容:
- 旋转范围是一个以度(0-180)为单位的值,这是一个随机旋转图片的范围。
- 宽度偏移和高度偏移是随机地垂直或水平翻译图片的范围(作为总宽度或高度的一小部分)。
- 剪切范围是随机应用剪切变换。
- 缩放范围用于随机缩放图片。
- 水平翻转是用来随机翻转一半图像的水平相关的,当没有假设水平不对称(例如真实世界的图片)。
- 填充模式是用来填充新创建的像素的策略,这些像素可以在旋转或宽度/高度移动后出现。
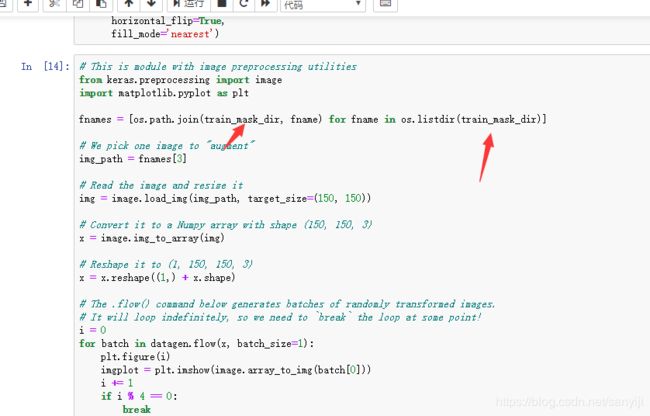
让我们来看看我们的增强的图像:
代码如下:
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)]
# We pick one image to "augment"
img_path = fnames[3]
# Read the image and resize it
img = image.load_img(img_path, target_size=(150, 150))
# Convert it to a Numpy array with shape (150, 150, 3)
x = image.img_to_array(img)
# Reshape it to (1, 150, 150, 3)
x = x.reshape((1,) + x.shape)
# The .flow() command below generates batches of randomly transformed images.
# It will loop indefinitely, so we need to `break` the loop at some point!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
得到四个图像如下:



如果我们使用这种数据增强配置来训练一个新的网络,我们的网络将永远不会看到两倍于相同的输入。然而,它所看到的输入仍然是紧密相关的,因为它们来自少量原始图像–我们不能产生新的信息,我们只能混合现有的信息。因此,这可能不足以完全摆脱过度适应。为了进一步对抗过度拟合,我们还将在我们的模型中添加一个Dropout层,就在紧密连接的分类器之前:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
让我们使用数据增强和删除来训练我们的网络:
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
因为我的电脑跑的太慢了,所以我这里就没有训练模型,直接用的别人训练好的模型进行预测了。
让我们再次看一下结果


由于数据的增加和丢失,我们不再过度拟合:训练曲线非常接近验证曲线。我们现在能够达到82%的精度,相对于非正则模型的15%的相对改进。
通过进一步利用正则化技术,通过调整网络的参数(如每个卷积层的滤波器数或网络中的层数),我们可以获得更好的精度,可能高达86-87%。然而,仅仅通过从零开始培训我们自己的ConvNet就很难达到更高的水平,因为我们只有那么少的数据可供使用。
三、完成一个摄像头采集自己人脸、并对表情(笑脸和非笑脸)的实时分类判读(输出分类文字)的程序。
1、首先实现照片的判别
# 单张图片进行判断 是笑脸还是非笑脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
model = load_model('smile_and_unsmile_2.h5')
img_path='genki4k/test/smile/file0901.jpg'
img = image.load_img(img_path, target_size=(150, 150))
#img1 = cv2.imread(img_path,cv2.IMREAD_GRAYSCALE)
#cv2.imshow('wname',img1)
#cv2.waitKey(0)
#print(img.size)
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]<0.5:
result='smile'
else:
result='unsmile'
print(result)
就是下面的这张图片进行检测

结果还是正确的,我试验了几张都是正确的。

2、 摄像头采集人脸识别
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('smile_and_unsmile_2.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='unsmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()
结果展示

四、 将笑脸数据集换成口罩数据集,完成对口罩佩戴与否的模型训练,采取合适的特征提取方法,重新做上述2-3步。
1、下载数据集
在网上找了很多数据集,但是很多都不符合要求,最终还是选择了知乎上的AIZOO人工智能乐园开源的数据集,然后进行整理形成自己可以用的数据集。
https://zhuanlan.zhihu.com/p/107719641

2、训练数据集
这里重复上面笑脸数据集的步骤就可以了,直接进行数据增强后的模型训练。
数据增强的代码和笑脸的类似,修改一下就可以了。
然后进行训练

训练完成

因为数据集有很多不是符合大头照的要求,所以精度比较低。

小于0.5的是戴口罩
保存模型后进行预测
代码和笑脸数据集的一样,只需要改模型名字即可。

还要注意预测值得判别条件

3、预测
预测结果如下
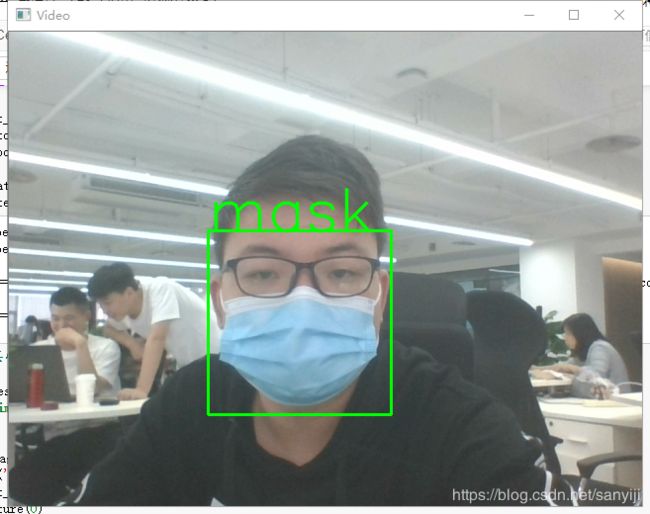

在测试的过程中发现如果人的脸离摄像头远一点的话,即使没戴口罩也会判别为戴了口罩,但是离得远大概率是识别不到人脸的,所以这种情况不用担心。
然后我还尝试用手挡住脸,判定我没戴口罩,比较理想

可以看到分类的效果还是不错的,后面可以尝试把不合格的数据剔除出去,再进行训练,相信精度会更高。