对鸢尾花数据集和月亮数据集,分别采用线性LDA、k-means和SVM算法进行二分类可视化分析。解释SVM算法的优点
1.SVM算法的优点
(1)使用核函数可以向高维空间进行映射
(2)使用核函数可以解决非线性的分类
(3)分类思想很简单,即样本与决策面的间隔最大化
(4)分类效果较好
2MNIST数据集的可视化LDA算法分析
2.1线性LDA算法对月亮数据集进行分类
#基于线性LDA算法对月亮数据集进行分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from mpl_toolkits.mplot3d import Axes3D
def LDA(X, y):
X1 = np.array([X[i] for i in range(len(X)) if y[i] == 0])
X2 = np.array([X[i] for i in range(len(X)) if y[i] == 1])
len1 = len(X1)
len2 = len(X2)
mju1 = np.mean(X1, axis=0)#求中心点
mju2 = np.mean(X2, axis=0)
cov1 = np.dot((X1 - mju1).T, (X1 - mju1))
cov2 = np.dot((X2 - mju2).T, (X2 - mju2))
Sw = cov1 + cov2
w = np.dot(np.mat(Sw).I,(mju1 - mju2).reshape((len(mju1),1)))# 计算w
X1_new = func(X1, w)
X2_new = func(X2, w)
y1_new = [1 for i in range(len1)]
y2_new = [2 for i in range(len2)]
return X1_new, X2_new, y1_new, y2_new
def func(x, w):
return np.dot((x), w)
if '__main__' == __name__:
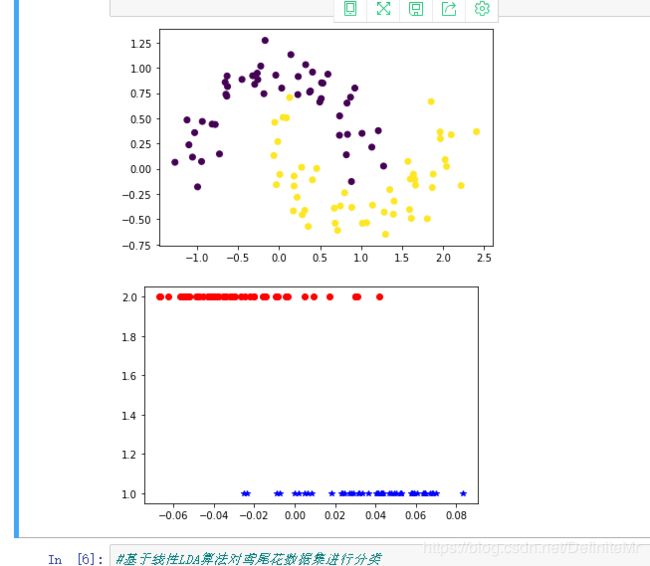
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
X1_new, X2_new, y1_new, y2_new = LDA(X, y)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
plt.plot(X1_new, y1_new, 'b*')
plt.plot(X2_new, y2_new, 'ro')
plt.show()
运行结果:
2.2线性LDA算法LDA辅助Logistic回归用于对鸢尾花数据集进行分类
#基于线性LDA算法对鸢尾花数据集进行分类
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import preprocessing
dataset = pd.read_csv('iris.data')
X = dataset.values[:, :-1]
y = dataset.values[:, -1]
le = preprocessing.LabelEncoder()
le.fit(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
y = le.transform(y)
X = X[:, :2]
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Applying LDA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(n_components = 2)
X_train = lda.fit_transform(X_train, y_train)
X_test = lda.transform(X_test)
# Fitting Logistic Regression to the Training set
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# Visualising the Training set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend()
plt.show()
运行结果:

3.MNIST数据集的可视化SVM算法分析
3.1SVM算法对月亮数据集进行分类
在from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
polynomial_svm_clf = Pipeline([
# 将源数据 映射到 3阶多项式
("poly_features", PolynomialFeatures(degree=3)),
# 标准化
("scaler", StandardScaler()),
# SVC线性分类器
("svm_clf", LinearSVC(C=10, loss="hinge", random_state=42))
])
polynomial_svm_clf.fit(X, y)
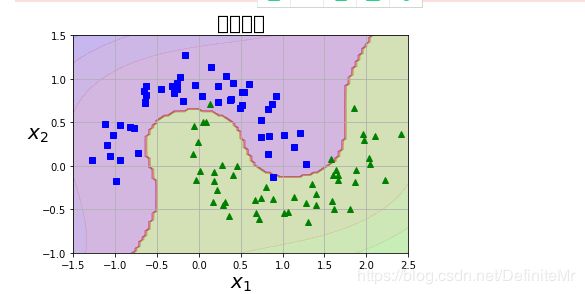
def plot_dataset(X, y, axes):
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "g^")
plt.axis(axes)
plt.grid(True, which='both')
plt.xlabel(r"$x_1$", fontsize=20)
plt.ylabel(r"$x_2$", fontsize=20, rotation=0)
plt.title("月亮数据",fontsize=20)
def plot_predictions(clf, axes):
# 打表
x0s = np.linspace(axes[0], axes[1], 100)
x1s = np.linspace(axes[2], axes[3], 100)
x0, x1 = np.meshgrid(x0s, x1s)
X = np.c_[x0.ravel(), x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
y_decision = clf.decision_function(X).reshape(x0.shape)
# print(y_pred)
# print(y_decision)
plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)
plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1)
plot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
这里插入代码片
运行结果:
3.2SVM算法对鸢尾花数据集进行分类
在这里插入代码片from sklearn.svm import SVC
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
def plot_point2(dataArr, labelArr, Support_vector_index):
for i in range(np.shape(dataArr)[0]):
if labelArr[i] == 0:
plt.scatter(dataArr[i][0], dataArr[i][1], c='b', s=20)
elif labelArr[i] == 1:
plt.scatter(dataArr[i][0], dataArr[i][1], c='y', s=20)
else:
plt.scatter(dataArr[i][0], dataArr[i][1], c='g', s=20)
for j in Support_vector_index:
plt.scatter(dataArr[j][0], dataArr[j][1], s=100, c='', alpha=0.5, linewidth=1.5, edgecolor='red')
plt.show()
if __name__ == "__main__":
iris = load_iris()
x, y = iris.data, iris.target
x = x[:, :2]
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
clf = SVC(C=1, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.1,
kernel='linear', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
# 调参选取最优参数
# clf = GridSearchCV(SVC(), param_grid={"kernel": ['rbf', 'linear', 'poly', 'sigmoid'],
# "C": [0.1, 1, 10], "gamma": [1, 0.1, 0.01]}, cv=3)
clf.fit(X_train, y_train)
# print("The best parameters are %s with a score of %0.2f" % (clf.best_params_, clf.best_score_))
predict_list = clf.predict(X_test)
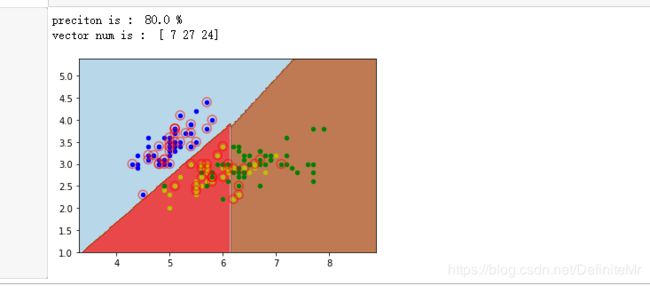
precition = clf.score(X_test, y_test)
print("preciton is : ", precition * 100, "%")
n_Support_vector = clf.n_support_
print("vector num is : ", n_Support_vector)
Support_vector_index = clf.support_
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
h = 0.02
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
plot_point2(x, y, Support_vector_index)
运行结果:
4MNIST数据集的可视化k-means算法分析
4.1k-means算法对月亮数据集进行分类
#基于k-means算法对月亮数据集进行分类
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
import numpy as np
X,y=make_moons(n_samples=100,shuffle=True,noise=0.15,random_state=42)
clf = KMeans()
clf.fit(X,y)
predicted = clf.predict(X)
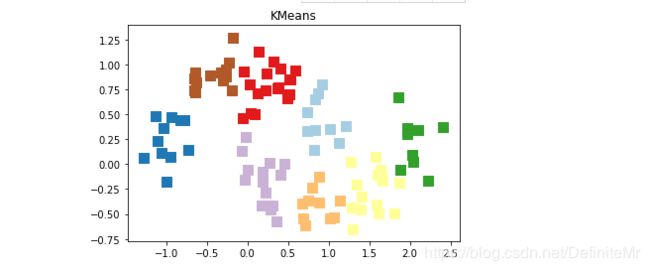
plt.scatter(X[:,0], X[:,1], c=predicted, marker='s',s=100,cmap=plt.cm.Paired)
plt.title("KMeans")
plt.show()
运行结果:
4.2k-means算法对鸢尾花数据集进行分类
#基于k-means算法对鸢尾花数据集进行分类
from sklearn.cluster import KMeans
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #用于画图时显示中文
from sklearn.datasets import load_iris #导入数据集iris
iris = load_iris() #载入数据集
url = "iris.data"
names = ['花萼-length', '花萼-width', '花瓣-length', '花瓣-width', 'class']
dataset = pd.read_csv(url, names=names)
clf = KMeans()
clf.fit(iris.data,iris.target)
predicted = clf.predict(iris.data)
pos = pd.DataFrame(dataset)
L1 = pos['花萼-length'].values
L2 = pos['花萼-width'].values
plt.scatter(L1, L2, c=predicted, marker='s',s=100,cmap=plt.cm.Paired)
plt.title("KMeans聚类分析")
plt.show()
运行结果:
