STL中的Sort
下面是对于STL中的sort进行一个小结,包含
insert_sort
bubble_sort
quick_sort
heap_sort
merge_sort
几种
1.stl_sort
这个是STL算法里面的标准sort,因为关联容器如果用红黑树实现本身已经排好序,如果用哈希表实现排序会破坏其结构。
在stl_sort实现中需要随机访问迭代器,所以不能用于list。
而stack又只能从头部访问。
所以对于常用的标准库容器,stl_sort就只适用于vector、deque。
stl_sort的具体实现涉及一下细节:
(1)quick_sort
①Medium_of_Three
这是stl_sort算法首选的运行模式。但是为了避免元素输入不够随机造成的尴尬,采取的优化是medium_of_three(三点中值)
取整个序列的头、尾、中央三个位置的元素,然后取中值元素作为pivot元素。
②核心思想--Partition
令头端迭代器first向尾部移动,尾端迭代器last向头部移动。
当*first大于或等于pivot元素时就停下来,当*last小于或等于pivot元素就停下来。
然后检验两迭代器是否交错。
如果不交错,就将两者元素互换,然后各自调整一个位置,继续相同的行为。
如果叫错了,表示整个序列已经调整完毕,first迭代器就指向pivot元素。
(2)heap_sort
当stl_sort使用quick_sort的迭代次数达到一个上限(上限的值和排序元素个数有关),就改为heap_sort。
这里所说的heap都是max_heap即堆顶元素时最大的元素,这样排序下来,刚好是一个升序排序。
①heap构造
A。元素个数不确定,构造堆
每个元素都是先push_back到最后,然后swim上来。
这样需要对每一个元素都进行swim操作。
B。元素个数确定,构造堆
这个时候可以对堆中所有的非叶子节点,从下层到上层依次进行sink操作。
这样可以减少O(N)的操作次数。
②heap排序
在构造好堆以后,堆顶元素就是最大的元素,
将堆顶元素与最末尾的叶子节点对调,然后将heap的节点个数减少1,
然后在对当前的堆顶元素做一次sink操作。
然后重复该操作。
最终就会得到一个升序排序的数组。
注意:一旦对一个堆进行排序,其堆的结构就被破坏了。
(3)insert_sort
当快速排序或者堆排序所要排序的元素个数小于16个的时候,就切换到插入排序。
原因是快速排序、堆排序需要的额外操作蛮多的,对于小数组性能不佳。
而插入排序,针对小数组速度不错,并且对于大部分元素已经排好序的序列效果极好。
①基本原理
对于未排序的序列,从头开始检查,每次检查一个元素。
并且第N次检查的时候,维护一个长度为N的子序列。当N=元素个数的时候,整个序列就排好序了。
②与a[0]比较优化
每次在检查一个元素的时候,不是与已排序的字序列的最后一个元素比较。
而是与已排序的最开始一个元素a[0]比较。
如果value<=a[0],那么使用copy_backward把已排序数组,整体后移一格,然后令a[0]=value
如果value>a[0],再按照正常途径来。
好处:
A。如果新加入元素就是比a[0]小,会省下很多步骤。
B。如果新加入元素比a[0]大,那么后面循环也不用做下标跑到0前面之前的判断。
③固定保存新插入元素优化
将新加入元素保存在value之中,每一次比较并不是交换两个元素,而是把需要移位的元素后移一格,这样少掉很多步骤。
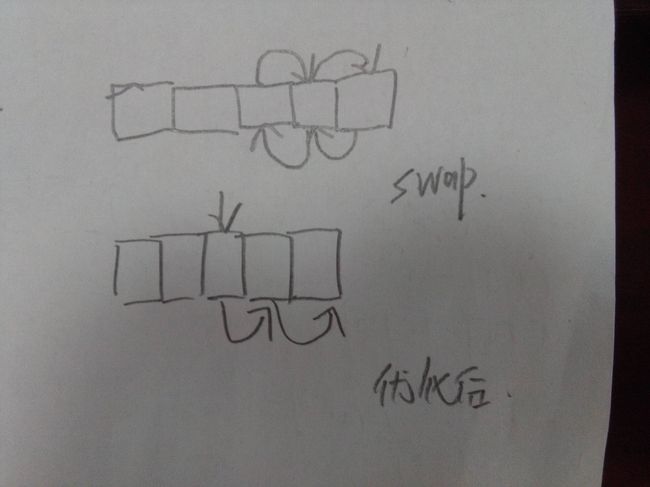
每一次swap是3次赋值+1次中间变量的构建与销毁,优化后每次需要一个赋值即可。
2.list::sort
list里面的sort是单独实现的。
在stl源码剖析里面,侯捷先生并没有把这个排序作为一个重点,所以注释很少。
我去看的时候非常烧脑,我就只有跟着代码,一步一步把图画下来看是怎么变化的。
最后看出来了,它其实采用的是一种变异版的merge_sort
在了解具体的实现之前,弄清楚为什么要实现成这样是非常重要的。
(1)为什么不用快排?
①迭代器比较操作
快排需要用到迭代器的比较操作(<,>,>=,<=),来移动迭代器的位置,来判断迭代器是否错位。
而list的迭代器不支持这些操作。
②中值选择
由于采用中间、头、尾元素比较得出中值元素,需要随机访问到中间元素,而list的迭代器,显然不支持随机访问。
(2)为什么不用堆排?
与不能使用快排的原因差不多,list根本无法随机访问,所以无法构建成堆那样来访问父节点与子节点。
(3)为什么不用归并排不用正常的方式?
这里所说的正常的方式是《算法 4th》里面介绍的,两种方式:
自顶向下:通过不断递归划分为子序列,当划分为1个元素大小的子序列时就相当于排好序了,然后进行回归。
自底向上:直接操控下标,将相邻2个元素归并,然后调整步长,归并4个元素的序列,这样logN次,就能归并最终的序列。
①不采用自底向上
这个很简单,因为自底向上需要迭代器随机访问,list迭代器并不能随机访问。
②不采用自顶向下
这个是因为在进行递归的时候,仍然需要计算mid的元素从而进行随机访问,list迭代器是不能随机访问的。
(4)实现细节
①carry元素
每次从需要排序的list中取出一个元素,然后作为中间过程的临时变量。
每一次完成的迭代,最后都会把已经排好序的子序列存放在counter[x]里面,所以每次迭代结束都会把carry交换为空list
②counter数组
这个数组作用是存放中间产生的已排序list子序列。
开始我还觉得这个数组只有64个元素,够用吗?
原来人家是存储的个数按指数增长,最后一个可以存储2^63个元素,就问你怕不怕!
③过程
每次从总list里面,取得一个元素放入carry。
中间有两个标志,来标示现在用到了哪个counter[],并且,这一次需要用到哪个。
然后如果下面的counter放满了,就开始merge,merge过后存放到下一个counter之中。
counter[0]要么null,要么放1个
counter[1]要么null,要么放2个
counter[2]要么null,要么放4个
counter[3]要么null,要么放8个
以此类推,反正就是每次就想上merge成更大的序列,然后放入下一个counter
同时这样放也能表示出任意的个数的list
最后list去玩了,将所有用到了的counter[]进行最后一次merge得到的list就是排好序的list。
3.bubble_sort
这个是参考了简书上面的一篇文章。
笔试时,冒泡排序也要写得优雅出众
普通冒泡排序,进行N次遍历,每次遍历N,N-1,N-2,...,1个元素。
主要就是提出了2点改进
(1)设置已经排好序标志
有一个排好序标志,以其作为循环条件。
初始状态为true。
每次进入循环后,将其设置为false。
如果有交换发生,就将其设置为true。
这样当某次循环中,没有交换发生,表明已经排好序。
那么标志就会提前结束循环。
(2)设置已经排好序位置
因为每次都会冒泡一个元素,所以每次可以确定一个元素的位置。
下一次循环时就可以少遍历一个顺序。
这种做法,每次交换时就记录交换的是哪个位置。
这样最后一次交换记录的就是最后一个失序的位置,之后的位置都已经是有序的了。
那么下次村换就能直接将检索范围,缩小自仍然失序的位置,这样可以节省一些步骤。