菜菜的机器学习sklearn实战-----从随机森林来看看机器学习调参
菜菜的机器学习sklearn实战-----从随机森林来看看机器学习调参
- 菜菜的机器学习sklearn实战-----从随机森林来看看机器学习调参
- 机器学习中调参的基本思想
- 正确的调参思路
- 泛化误差
- 参数对泛化误差的影响
- 实例:随机森林在乳腺癌数据上的调参
- 随机森林调参第一步:无论如何先来调n_estimators
- 学习曲线
- 调max_depth
- 调max_feature
- 调min_samples_leaf
- 调min_samples_split
- 调criterion
- 调整完毕,总结出模型的最佳参数
菜菜的机器学习sklearn实战-----从随机森林来看看机器学习调参
机器学习中调参的基本思想
高手的调参依赖于经验,这些经验来源于:
1)非常正确的调参思路和方法
2)对模型评估指标有深入理解
3)对数据的感觉和经验
4)洪荒之力
正确的调参思路
第一步是找目标:我们到底要优化什么
泛化误差
当模型在未知数据上表现糟糕时,我们说模型的泛化程度不够,泛化误差大。
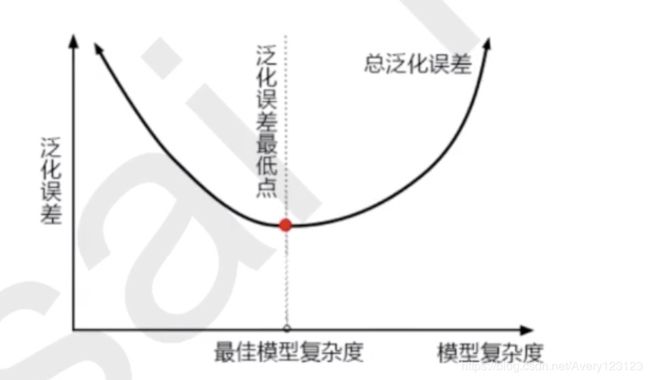
通过上图我们发现模型的复杂度会影响泛化误差:
模型太简单和太复杂都会使得泛化误差变大分别是欠拟合和过拟合
树模型是天生的的复杂模型,对于树模型来说非常容易过拟合
同样的,对于以树模型作为基础的随机森林来讲,我们的调参目标就是减少模型的复杂度来降低泛化误差。
注意:
模型太复杂或者太简单,都会让泛化误差高,我们追求的是位于中间的平衡点
模型太复杂就会过拟合,模型太简单就会欠拟合
对树模型和树的集成模型来说,树的深度越深,枝叶越多,模型越复杂
树模型和树的集成模型的 目标,都是减少模型复杂度,把模型往图像的左边移动
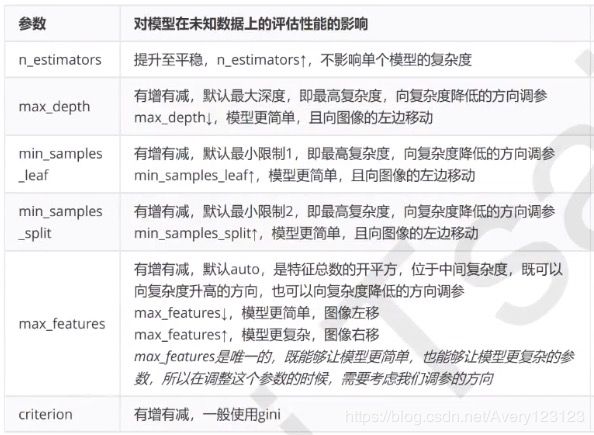
参数对泛化误差的影响
影响力从高到低:
实例:随机森林在乳腺癌数据上的调参
随机森林调参第一步:无论如何先来调n_estimators
学习曲线
"""
这里我们选择学习曲线,当然可以用网格搜索,但是只有学习曲线才能看清趋势
找到n_estimators取什么值得时候开始变得稳定
每间隔10个数运行一次,帮助我们划定范围
"""
score_list = []
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1
,n_jobs=-1
,random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score_list.append(score)
#print(max(score_list),(score_list.index(max(score))*10)+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),score_list)
plt.show()
print(max(score_list),(score_list.index(max(score_list))*10)+1)
"""
已经初步确定最高得分处在41左右
"""
score_list2 = []
for i in range(35,45):
rfc = RandomForestClassifier(n_estimators=i
,n_jobs=-1
,random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score_list2.append(score)
plt.figure(figsize=[20,5])
plt.plot(range(35,45),score_list2)
plt.show()
print(max(score_list2),score_list2.index(max(score_list2))+35)
0.9719568317345088 39
最后得到n_estimatos=39时候得到最大值
调max_depth
可以先用学习曲线划定范围,再进行网格搜索
这里直接进行网格搜索
param_grid = {'max_depth':np.arange(1,20,1)}
print(param_grid)
#一般根据数据的大小进行一个试探,乳腺癌数据很小,所以可以采用1到10,或者1到20这样试探
#但是对于像difit recognition这样的大型数据来说,我们应当尝试30到50层的深度(或许还不够)
#更应该画出学习曲线,来观察深度对模型的影响
rfc = RandomForestClassifier(n_estimators=39
,random_state=90)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
#返回调整好的最佳参数对应的准确率
GS.best_score_``
#显示调整出来的最佳参数
GS.best_params_
得到最佳的max_depth
{‘max_depth’: 11}
调max_feature
可以先用学习曲线划定范围,再进行网格搜索
这里直接进行网格搜索
param_grid = {'max_feature':np.arange(5,30,1)}
"""
max_features是唯一一个既能将模型往左(低方差高偏差)推又能将模型往右(高方差低偏差)推的参数。
我们需要根据调参之前,模型所在的位置(泛化误差最低点左还是右)来决定我们要将max_feature推向哪里
这时位于图像左侧,我们需要更高的模型复杂度,需要把max_features调大
由于max_features的默认最小值是sqrt(n_features),因此我们是用这个值作为最小值
"""
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_params_
GS.best_score_
调min_samples_leaf
param_grid = {'min_samples_leaf':np.arange(1,11,1)}
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_
GS.best_params_
调min_samples_split
param_grid = {'min_samples_split':np.arange(2,22,1)}
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_
GS.best_params_
调criterion
param_grid = {'criterion':['gini','entropy']}
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
GS.best_score_
GS.best_params_
调整完毕,总结出模型的最佳参数
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
#提升了多少
score-score_pre