Pandas组间组内分类排序抽样/rank/groupby/apply/sample/sort_values多种组合随机抽数据
举栗子
test=pd.DataFrame({'a':[1,2,3,4,5,11,22],'b':[6,7,8,9,10,12,33],'c':['x','z','y','z','x','y','z']})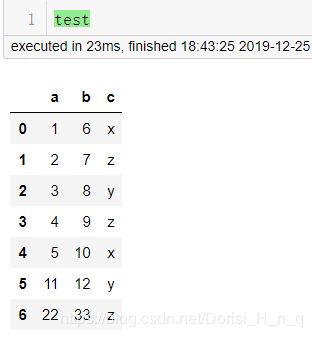
1 组间排序
组间排序输出显示的是“c”列中各个类别为一个数值的形式。
test['c'].rank(ascending=0,method='dense')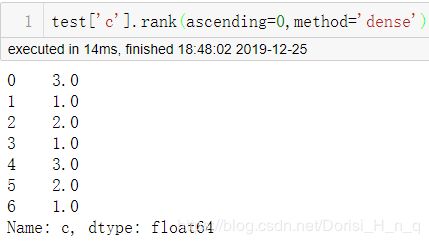
2 类别排序
根据某一列的类别进行按照类别归类排列。
test.sort_values(by="c",inplace=True)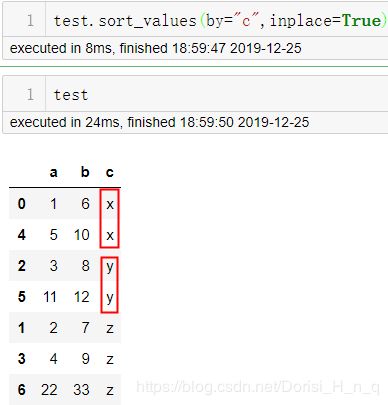
3 组内排序
组内排序rank与分组groupby组合使用,输出类别分组后,在各类别中进行排序
test['sort']=test['a'].groupby(test['c']).rank(method='dense',ascending=1)
4 抽取各个类别的前2行数据
test[test['sort'].apply(lambda x:x<3)]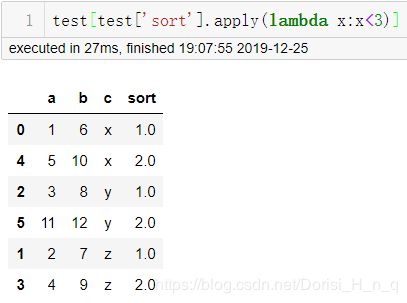
5 随机抽样各个类别的百分比数据
test.groupby(test['c']).apply(lambda x:x.sample(frac=0.5))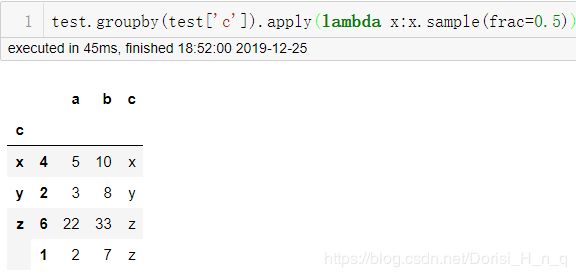
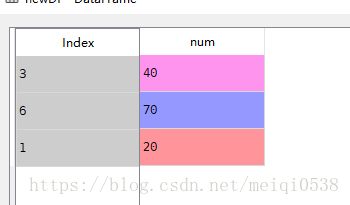
6 使用随机数抽取数据
#导包
import pandas
import numpy as np
from pandas import read_csv
df=read_csv(r"C:\Users\JackPi\Desktop\pandas\data\data5.csv")
#获取随机值
r=np.random.randint(0,10,3)
#对行进行切片
newDf=df.loc[r,:]
原文链接:https://blog.csdn.net/meiqi0538/article/details/82557894