论文详解——GeoNet:Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose
前言:
商汤科技在CVPR2018的一篇《GeoNet:Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose》,提出了一种可以联合学习深度、光流和相机姿态的无监督学习框架GeoNet,取得了超越了之前的无监督学习方法并且可与最佳监督学习方法的效果。
相关工作:
理解视频中的3D场景几何是视觉感知领域内的一项基本任务,其中包括很多经典的计算机视觉任务,例如深度恢复、流估计、视觉里程计(visual odometry)。这些技术都有广泛的工业应用,包括自动驾驶平台、交互式协作机器人以及定位与导航等。
传统的根据运动恢复结构(SfM:Structure from Motion)方法是以一种集成式的方式来解决这些任务,其目标是同时重建场景结构和相机运动。但是,这种方法本质上是依赖于高质量的低层次特征对应,所以容易受到异常值和无纹理区域的影响。
为了突破这个局限性,将深度学习模型应用到了每个低层面的子问题上,并且取得了一定的效果。其主要优势来源于大数据,有助于为低层面的线索学习获取高层面的语义对应(即能学习到更高层面的语义线索)。相比于传统方法,即使在ill-posed区域,也能有比较好的表现。但是通常需要大量的groundtruth进行有监督的学习,需要昂贵的激光雷达和查分GPS设备,数据获取和标注成本很高。此外,之前的深度学习模型大都是为解决单个特定任务而设计的,比如深度、光流、相机姿态等,而没有去讨论这些任务之间的几何约束和关联性。
关键点:
在这篇文章中提出的无监督学习框架GeoNet能够从视频中联合学习单目深度、光流和相机运动。这种方法的理论基础在于3D场景几何的本质特性。直观的解释就是——3D场景都是由静态背景和动态目标构成的。大多数的自然场景都是由刚性静态表面组成,如道路、房屋、树木等,它们在视频帧之间的2D投影图像完全由深度结构和相机运动决定。同时,在这些场景中也包含运动的对象,例如行人、车辆等,他们的运动由相机运动和自身的运动共同决定,可以用光流模拟相机运动。
主要贡献有两点:
1.采用了一种“分而治之”的策略,分别学习刚性流和物体运动。在每个阶段用视图合成(view synthesis)与原图的相似度误差来引导与监督学习。
2.引入了自适应几何一致性损失,通过前向-反向一致性检查,自动过滤遮挡和可能的异常值。
网络结构:
GeoNet的网络结构包含两个部分:刚性结构重构器和非刚性结构定位器,分别来学习刚性流和物体运动,在整个无监督学习的过程中,采用图像外观相似度来引导。
具体的网络结构,详见另一篇博客点击打开链接。

Stage 1 —— Rigid Structure Reconstructor
在第一部分Rigid Structure Reconstructor,包括两个子网络DepthNet和PoseNet,分别回归出深度图和相机姿态,并融合产生刚性流。
DepthNet采用了编码器encodr+解码器decoder的结构,编码器部分以ResNet50作为基本结构,解码器部分由反卷积层构成,并且在encoder和decoder之间的不同分辨率上采用了skip connections,进行了多尺度下的预测。这样能够同时保留全局高层次特征和局部细节信息。训练数据是一组时间上连续的视频帧(已知相机内参),其中I(t)是目标帧,作为参考帧,其他帧都是源帧I(s)。DepthNet回归得到不同分辨率下的深度图(原图大小,1/2,1/4,1/8)—— D(t)。
PoseNet包含8个卷积层,在输出最终预测结果之前有一个全局平均池化层。在除了输出层之外的卷积层之间都采用了Batch Normalization和ReLUs激活函数。同样也是预测出四个不同分辨率下的相机6DoF(xyz坐标和欧拉角),记为T(t-s)。注意,预测结果是6DoF,是一个长度为6的一维向量,但是在公式中T(t-s)代表的是从目标帧到源帧的变换矩阵(4*4),变换矩阵可由6DoF通过变换得到!!!
有了深度和相机姿态,则可以计算出刚性流:

由从目标帧到源帧的刚性流,结合源帧,则可以warp得到合成的目标帧~I(rig;s),即视图合成view synthesis。(具体解析详见《Unsupervised Learning of Depth and Ego-Motion from Video》,下图出自该论文。)
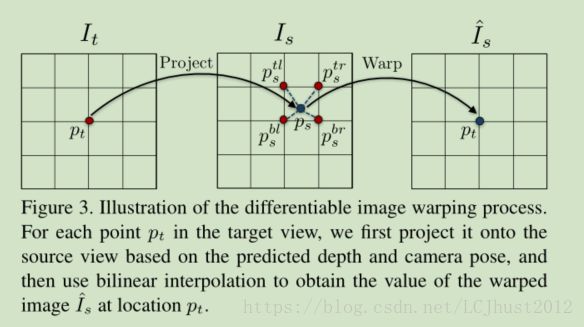
在刚性部分的warping loss由图像外观相似度来表征,即目标帧的原图I(t)和通过刚性流与源帧warp得到的合成视图~I(rig;s)之间的相似度误差。
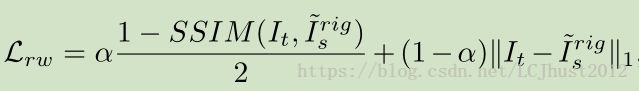
除此之外,还引入了Disparity Smoothness Loss,
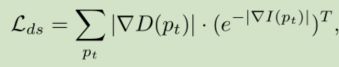
具体计算方法为,参考论文《Unsupervised Monocular Depth Estimation with Left-Right Consistency》公式(3)。
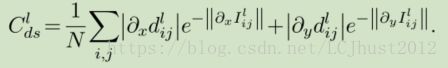
Stage 2 —— Non-rigid Motion Localizer
第二部分Non-rigid Motion Localizer,通过ResFlowNet实现,用于定位动态目标。一般光流可以直接模拟无约束的运动,这是在现有的深度学习模型中经常采用的办法。用ResFlowNet学习剩余的非刚性流,其位移仅仅由物体与世界平面的相对运动引起。ResFlowNet学习得到的非刚性流再与刚性流结合,就推导出最终的预测流。ResFlowNet与DepthNet的网络结构相似,以级联的方式连接在第一阶段之后。对于给定的图像帧对,ResFlowNet利用刚性结构重构器的输出,预测对应的剩余流(res)f(t-s),最终整个预测流为(full)f(t-s)=(rig)f(t-s)+(res)f(t-s)。
通过略微的修改将第一阶段的监督扩展到目前阶段。具体的,在整个预测流(full)f(t-s)之后,对任意一对目标帧和源帧之间再进行image warping,用(full)I~代替(rig)I~,从而获得full flow的warping loss。同样的,将平滑损失扩展到2D光流场中。
GeoMetric Consistency Enforcement
GeoNet的每个阶段都以合成视图与原图的差异程度作为监督,这其中隐含了光度一致性(photometric consistency)的假设,但实际上遮挡区域和non-Lambertian表面不满足这样的假设条件。为了处理这个负面影响,在不改变网络结构的前提下应用了前向-后向一致性检验。但是这种约束和warping loss,不应该加在遮挡区域。
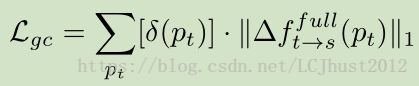
其中,(delta)f是目标帧I(t)在像素p(t)处前后一致性检验计算得到的full flow的微分。[ ]是Iverson bracket,[P]等于1(如果条件P为真,否则等于0)。 delta(pt)表示条件:
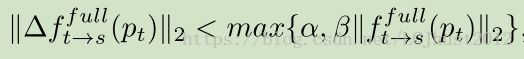
前向、后向流动不一致像素点被认为是可能的离群点。由于这些区域违反了photo consistency和geometric consistency假设,只能用平滑损失来处理。因此full flow的warping loss和geometric consistency都是按像素加权来计算的。
最终,整个网络的损失函数为:
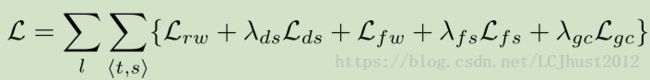
训练与测试细节:
github地址:点击打开链接
- Data Preparation
对于depth和flow任务,训练用到的数据集为KITTI raw dataset,pose任务,训练用到的数据集为KITTI odometry。
准备好数据集后,需要对数据集进行预处理,划分好训练过程中的训练集和验证集。
## Depth Task
## dataset:KITTI raw
python data/prepare_train_data.py --dataset_dir=../KITTI/kitti_raw/ --dataset_name=kitti_raw_eigen --dump_root=data_preprocessing/dump_data_depth/ --seq_length=3 --img_height=128 --img_width=416 --num_threads=16 --remove_static## Pose Task
## dataset:KITTI odometry
python data/prepare_train_data.py --dataset_dir=../KITTI/kitti_odometry/dataset/ --dataset_name=kitti_odom --dump_root=data_preprocessing//dump_data_pose/ --seq_length=5 --img_height=128 --img_width=416 --num_threads=16## Flow Task
## dataset:KITTI raw
python data/prepare_train_data.py --dataset_dir=../KITTI/kitti_raw/ --dataset_name=kitti_raw_stereo --dump_root=data_preprocessing/dump_data_flow/ --seq_length=3 --img_height=128 --img_width=416 --num_threads=16dump_data_depth文件夹中的文件结构如下图:

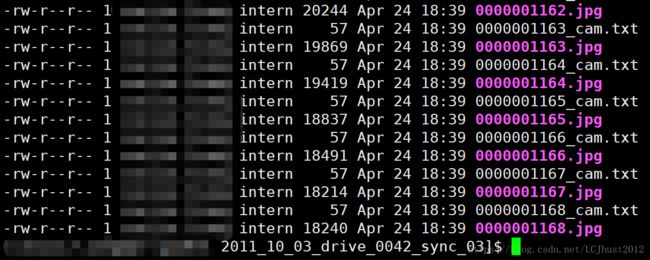

其中train.txt和val.txt分别记录了训练集和验证集的图片的路径及文件名。其中每一个文件夹的内容如右图所示,*_cam.txt中记录了一个长度为9的一维向量,即相机内参。而每张图片是在原始数据集上,将连续三帧拼接在一起,输入进网络。
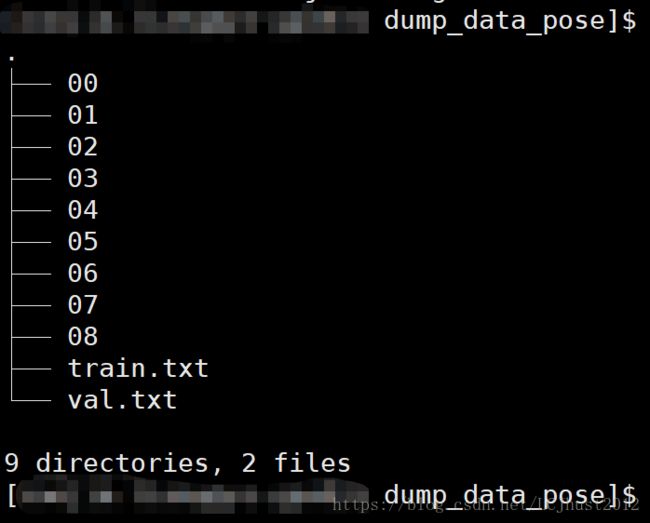
dump_data_pose的文件结构如下图所示:

![]()
其中train.txt和val.txt分别记录了训练集和验证集的图片的序列号(00-08)及文件名。同样的,在00-08的每一个文件夹中*_cam.txt中记录了一个长度为9的一维向量,即相机内参。而每张图片是在原始数据集上,将连续5帧拼接在一起,输入进网络。以00序列为例,原始数据集中00一共有0000-4540帧,将连续的5帧拼接在一起,则处理后的图片一共有(4540-5+1)= 4536张。(但是实际上处理后的图片是0000-4538,可能是在原点处使用了双目图片?不清楚,看代码)
dump_data_flow的文件结构如下图所示:
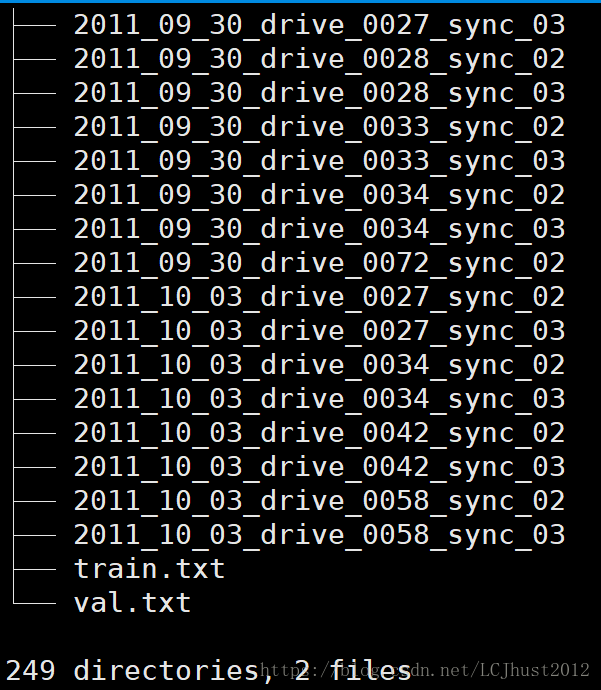
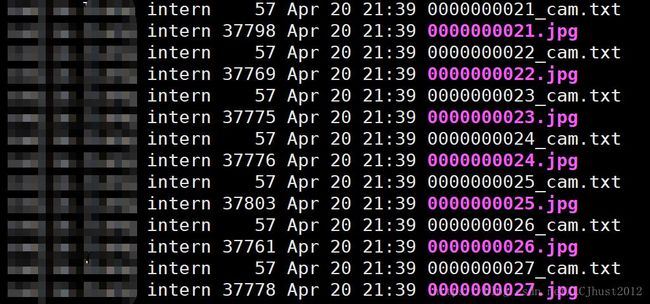

其中train.txt和val.txt分别记录了训练集和验证集的图片的路径及文件名。其中每一个文件夹的内容如右图所示,*_cam.txt中记录了一个长度为9的一维向量,即相机内参。而每张图片是在原始数据集上,将连续三帧拼接在一起,输入进网络。depth和flow任务的训练集都是KITTI raw,但depth使用的是eigen数据集,flow使用的是stereo数据集。
- Training
## Train DepthNet
python geonet_main.py --mode=train_rigid --dataset_dir=data_preprocessing/dump_data_depth/ --checkpoint_dir=checkpoint/checkpoint_depth/ --learning_rate=0.0002 --seq_length=3 --batch_size=4 --max_steps=350000## Train PoseNet
python geonet_main.py --mode=train_rigid --dataset_dir=data_preprocessing/dump_data_pose/ --checkpoint_dir=checkpoint/checkpoint_pose/ --learning_rate=0.0002 --seq_length=5 --batch_size=4 --max_steps=350000mode 设置为train_flow时,是用来训练DirFlowNet或者ResFlowNet。
## Train ResFlowNet
## 训练ResFlowNet时,--init_ckpt_file需要指向train_rigid模式下有相同训练数据的预训练的模型,即model-depth
python geonet_main.py --mode=train_flow --dataset_dir=../data_preprocessing/dump_data_depth/ --init_ckpt_file=../models_self/depth/model-345000 --checkpoint_dir=models/flow_residual/ --learning_rate=0.0002 --seq_length=3 --flownet_type=residual --max_steps=100001## Train DirFlowNet
python geonet_main.py --mode=train_flow --dataset_dir=../data_preprocessing/dump_data_flow/ --checkpoint_dir=models_self/flow_direct/ --learning_rate=0.0002 --seq_length=3 --flownet_type=direct --max_steps=400001